








晓查 李林 编译自 Quora 量子位 出品 | 公众号 QbitAI
昨天,美国问答网站Quora宣布完成了8500万美元的D轮融资,估值翻倍。这样说来,Quora现在的估值应该是18亿美元,成了一只新的独角兽。
在过去一年里,Quora除了继续扩大用户规模之外,还开始了商业化尝试,机器学习技术在这家公司业务上的应用,也增加了很多,不仅已有的机器学习应用用上了更大更好的模型,机器学习的使用领域也有扩张。
那么,Quora现在是怎样使用机器学习的?其机器学习负责人Nikhil Dandekar前不久发文做了一下介绍,量子位编译如下:
我将介绍Quora产品的不同部分,讨论我们在其中是如何使用机器学习的。
Quora知识共享的主要方式是问题和答案。这从用户希望获得一个令其满意的回答开始,或者说从“信息需求”开始。
用户在Quora上提出了一个新的问题后,我们有一套机器学习系统进行问题的理解,即从问题中提取信息,从而使接下来的流程变得更容易。下面,我描述一下这个问题理解系统。
我们关心内容的质量,这一切都以问题的质量开始。我们有一个ML系统可以对问题质量进行分类,帮助我们区分高质量和低质量的问题。除了问题质量,我们还会确定一些不同的问题类型,这会帮助我们确定在接下来的流程中如何处理问题。
最后,我们也做了问题主题标签来确定问题的主题。大多数主题建模应用都可以处理大型文档文本和较少的主题关键词,但我们处理的是一个的简短问题文本和超过一百万个潜在主题,这使得这项工作成为一个更具挑战性的问题。
在所有问题理解模型中,我们从问题本身和它的语境来获得其特征。例如,询问问题的用户,询问问题的地点等等。
满足用户信息需求的另一种方法是让他们在现有问题中找到他们所需的答案。我们有两个主要的搜索系统:问题栏(Ask Bar)搜索,它为Quora主页上的页首搜索栏提供支持;还有一个就是全文搜索,这是一个更深入的搜索系统,您可以通过点击问题栏结果中的“搜索” 选项来获得。这些搜索系统使用不同的排名算法,这些算法在搜索速度、相关性以及返回结果的广度和深度方面有所不同。
问题理解系统的输出是问题生命周期中下一个步骤的重要输入:如何从专家那里获得答案。在这里,我们也有机器学习系统,帮助我们更好地解决这个问题。
邀请回答(Request Answers,直译是“请求回答”,以前称为要求回答,Ask to Answers,A2A)是Quora的一项功能:允许用户将请求发送给其他用户,要求他们为特定问题写一个答案。
我们将邀请回答构建成了一个机器学习问题,用这种方法来推荐建议邀请的用户。我们在另一篇博客文章中介绍了这个系统的细节:“请求回答”中的机器学习问题。地址:https://engineering.quora.com/Ask-To-Answer-as-a-Machine-Learning-Problem
在A2A之外,我们将未答复的问题与专业问题回答者进行匹配的主要方式是通过Quora主页信息流。问题排名对我们来说是一个非常重要的问题。我们将上面所述的问题属性、用户属性以及一系列其他原始的和衍生的功能作为这个排名模型的输入,为用户生成具有话题性、相关性的个性化的Feed 。这是几天前我feed的截图:
如上图所示,信息流不仅包括你可以撰写答案的问题,还包括值得阅读的回答。答案内容的信息流排序也是一个对我们来说非常重要的机器学习问题。信息流中的问题排名和答案排名使用类似的底层系统,但二者的目标非常不同,因此在其基础模型中使用了不同的特征集合。
另一个我们使用机器学习来评估值得阅读答案排名的是我们向用户发送的电子邮件摘要。所有这些排名问题都由相当先进的机器学习系统提供支持,这个ML系统使用多种模型和许多不同的功能来实现最终排名。
一旦用户发现有趣的问题,我们希望确保他们能在Quora上有一个很好的阅读体验。对一个问题的答案进行排名,对我们来说是一个重要的ML应用,它能确保最相关的答案在问题的顶部出现。我们在这篇文章里详细介绍答案排名背后的ML系统:Quora回答排名上的机器学习方法,地址:https://engineering.quora.com/A-Machine-Learning-Approach-to-Ranking-Answers-on-Quora
除了答案,我们也对评论做出排名,以确保你在顶部看到最相关的答案评论。所有这些排名系统都超出了简单的赞同或者反对,而是通过来自用户的赞同和反对、内容质量、活跃度等信息来得出最终排名。
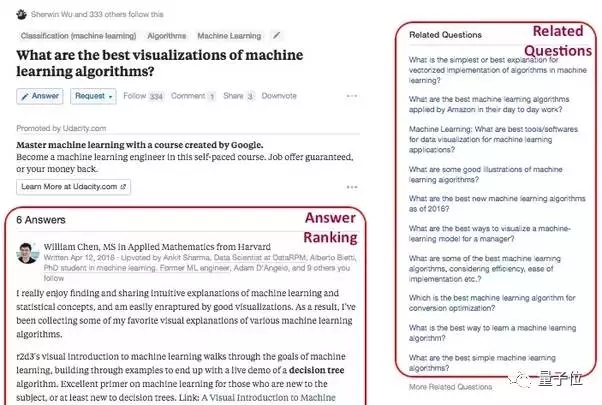
我们还想确保在阅读特定问题的答案后,你能有很好的途径来查找相关内容以持续你的阅读体验。机器学习的一个产品功能就是提供相关问题。我们在问题页面上显示相关问题,帮助用户更轻松地在Quora问题空间中导航。我们还用相关主题和热门主题的排名系统来帮助指引Quora的读者。在主页,我们还会在面板上显示值得关注主题和值得关注用户的内容,这两个都是基于我们对用户的了解而个性化的推荐系统。
上述ML系统的一个非常重要的元素是个性化。个性化涉及让产品和底层系统与Quora的每个用户相关。使ML系统个性化的一个重要组成部分是对用户的理解。作为对用户理解的一部分,我们观察和获得用户的各种特征,比如他们喜欢和不喜欢的主题,他们在不同领域的专业知识和他们的社交网络属性。我们还有各种“用户实体”关联系统,例如用户和主题的关联,用户和用户的关联等等。所有这些个性化标志都是重要的输入,不仅用在本节讨论的“阅读”上,在问题与专业答案撰写者的匹配问题上也很重要。
对于Quora良好的用户体验来说,内容质量是一个关键因素,我们想让站内的问题、答案、话题和其他内容从高质量起步,并一直保持下去。为此,我们用一组机器学习系统来维护内容质量,以下是其中的几个:
重复问题检测:这涉及到检测具有相同意图的不同问题,并将它们合并为一个标准问题。我们曾经发文介绍过Quora解决这个问题的方法,还举办了一个Kaggle竞赛并发布了重复问题数据集。
Quora如何检测重复问题:https://engineering.quora.com/Semantic-Question-Matching-with-Deep-Learning
重复问题检测Kaggle竞赛:https://www.kaggle.com/c/quora-question-pairs
恶意内容检测:友好和尊重是Quora社区讨论的准则,但是对任何一个这区来说,要保持这两点都很难。我们用机器学习和人工审核相结合,来识别冒犯性的、会伤害用户的内容,来确保良好的用户体验。
垃圾信息检测:对大多数UGC(用户生产内容)的应用来说,垃圾信息检测都很重要,我们也不例外。我们将几个不同的机器学习系统结合起来使用,来拦截垃圾内容,以及发布这类内容的用户。
2016年,我们开始试水商业化。现在,我们在问题页面上展示和问题意图相关的广告,并用机器学习来预测广告点击率,确保我们展示的广告是和用户相关的,对广告主也有较高的价值。
我们在商业化上的机器学习尝试还处于早期,在接下来的几个月或几年中,我们会继续拓展机器学习在这个领域的应用。

除了上文列出的这些,我们还有其他机器学习系统,但篇幅所限,就不再列举了。
我们让团队选择最好的模型和工具,但同时也在这些工具之间保持标准化和复用。
这是我们用到的一些模型(排名不分先后):
逻辑回归(Logistic Regression)
弹性网络(Elastic Nets)
梯度提升决策树(GBDT, Gradient Boosted Decision Trees)
随机森林(Random Forests)
(深度)神经网络
LambdaMART
矩阵分解(奇异值分解、BPR、加权ALS等)
向量模型及其他NLP技术
K均值及其他聚类方法
……
我们还支持使用开源和内部库来完成工作,例如TensorFlow、sklearn、xgboost、lightgbm、RankLib、nltk等开源库,以及Quora自己的矩阵分解库QMF等内部库。
QMF详情:https://github.com/quora/qmf
从2015年到现在,我们还有一个激动人心的发展,是形成了一个机器学习平台团队,这个团队的目标是让公司的其他机器学习工程师搞起机器学习来更容易,包括离线(模型训练)和在线(模型使用)环节。
在线方面,机器学习平台所拥有的系统能帮助机器学习工程师创建和部署高性能、高效率、高可靠性、高可用性的实时机器学习系统。
离线方面,有了机器学习平台团队的帮助,工程师们就能快速以标准化、可复用的方式建立数据管道,做特征生成、训练模型等工作。
一个专注的平台团队,帮Quora加速了机器学习开发速度,也为我们做好了扩展系统规模以处理更大的数据量的准备。
另外早在2015年,Quora负责工程的副总裁Xavier Amatriain就“如何在Quora中使用机器学习”写了一篇文章:Quora在2015年如何使用机器学习?感兴趣的小伙伴可以去 https://www.quora.com/How-does-Quora-use-machine-learning-in-2015 阅读。


 友情链接
友情链接