








原作 TAYLOR KUBOTA
Root 编译自 Stanford News
量子位 报道 | 公众号 QbitAI
拐角路口没有装凸面反光镜的话。

老司机开车都得减速慢下来。
谁知道拐弯看不见的地方,会不会有人或小动物突然窜出来。
就更别说无人车了。
辣有没有可能,现有的激光雷达能够提前看到视域外的物体,及时启动制动功能?
斯坦福SCIL实验室在努力
完全有。
在昨天,3月5号,斯坦福SCIL实验室(Stanford Computational Imaging Lab)在Nature上发表了一篇论文,Confocal Non-line-of-sight Imaging based on the Light-cone Transform。

这篇文章,阐述了如何利用反射回来的光束3D建模还原出拐角盲区后的物体。
他们研发这个“透视”技术的初衷,是想用在无人车上,提前预判出拐角的人,增加无人驾驶的安全性。
“听起来很神奇,但这是可以实现的。”斯坦福电子工程助理教授Gordon Wetstein说。
“看见”看不见的
坦率地讲,这个借用激光的反射把拐角盲区的物体成像的方法,并不是只有斯坦福研究团队在做。
不过,他们的算法最好用。
算法原理介绍视频传送⤵
“盲区物体成像的挑战,是找出一种有效的方法来从噪声测量中恢复看不见物体的三维结构,”SCIL实验室研究生David Lindell说。 “我认为,这种方法能有多大的影响力,取决于成像的计算效率。”

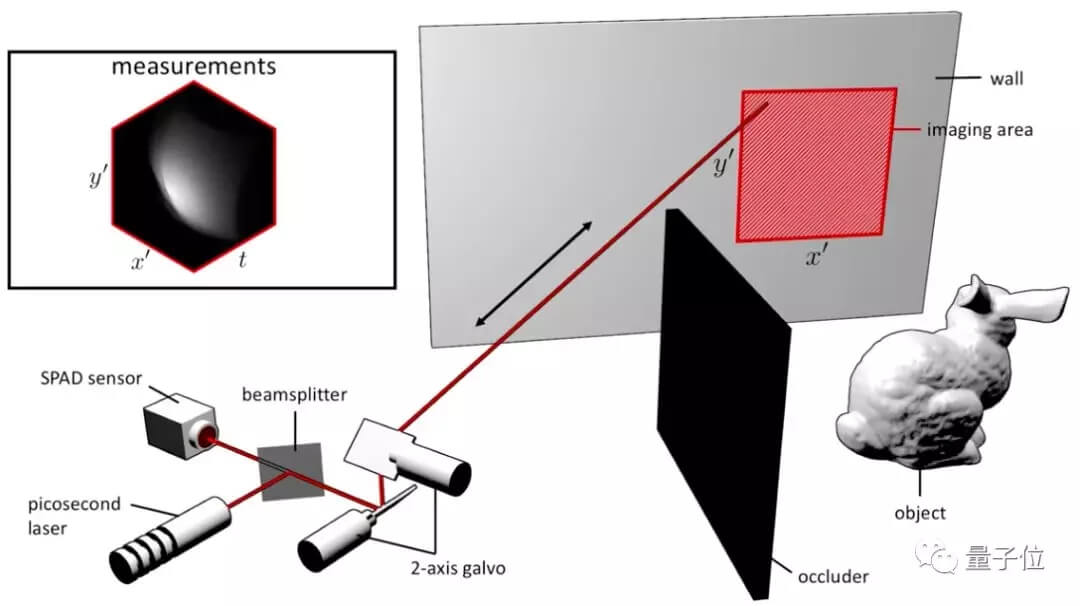
这套系统,研究团队把一个激光器放在了一个光子探测器旁边。
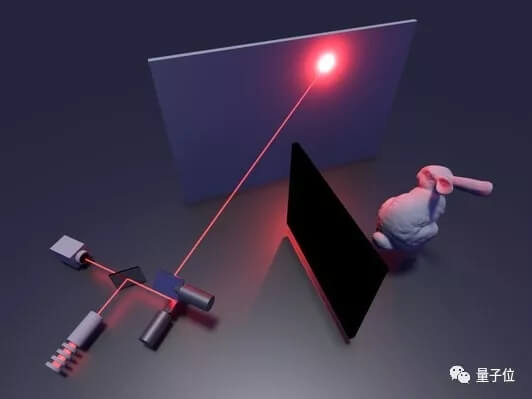
这个探测器高度敏感,可以捕捉到单个光粒子。
研究团队往墙上打人肉眼看不到的激光脉冲,然后这些脉冲遇到拐角背后的物体,会反弹回到墙上来,继而被光子探测器接收。
现阶段,扫描的过程可能需要两分钟到一小时,具体取决于光照条件和盲区物体的反射率。
一旦扫描完成后,算法会计算回收光子的轨迹,逐渐把模糊的点变成清晰的3D模型。
整个过程用不到1秒。算法流弊到可以直接在普通的笔记本上跑起来。
考虑到现有算法优秀的表现,研发特对认为他们可以加快处理速度,扫描完成的一瞬间也能成像复原盲区物体。
实际路测遇到的困难
在这篇文章工作之后,SCIL的研发团队还会继续完善这套“透视”系统。
要知道,现实世界里,无人车行驶的环境比实验室预设的场景复杂得多。
如何快速地响应这些复杂的变化?如何压缩扫描的时间?
这些都是研发团队要解决的课题。
无人车体与盲区物体的距离、环境的光照条件等各种因素,都会影响到光子探测器的光子捕捉。要准确地还原出、“看见”盲区物体的样子,在实际行驶过程中,并不是件容易的事。
另外,这种“透视”技术还得充分利用上散射的光子。而散射的光,还是当下车导航LIDAR系统选择性忽略的信息。
“我们认为,“透视”算法已经可以用到LIDAR系统上了,”该论文的共同主要作者,SCIL博士后Matthew O’Toole说。 “关键的问题是,目前LIDAR系统的硬件能不能支持这种类型的成像。”
在“透视”系统上路之前,研发团队还有两个方向可以再进一步优化。
一个是在日光照射下的表现。还有怎么应对快速移动的物体。
比方说突然有个篮球跑到路中央,或者飞速穿过马路的熊孩子。
研究人员路测了他们的技术。
他们发现,这套“透视”系统只能使用间接光。尽管这套系统可以很灵敏地发现带反光材质的物体,比方说穿了安全服的人,或者交通标志,但是对于没有穿会反光的衣物的一般路人来说,系统就发现不了(liao)了(le)。
“我们的工作,也算是迈出了有意义的一步。相信这个透视功能,未来会让我们所有人都受益的,”助理教授Wetzstein说,“我们接下来会加强这套系统在实操上的适用性。”
Wetzstein除了是电子工程助理教授之外,还兼任计算机学院助理教授,并是斯坦福Bio-X和神经生物学协会的成员。
该项目的资金支持,来自于加拿大政府,斯坦福大学研究生教育副院长办公室,国家科学基金等五个机构。
最后,附论文地址,
https://www.nature.com/articles/doi:10.1038/nature25489
& SCIL实验室网站,
& 编译来源,
https://news.stanford.edu/2018/03/05/technique-can-see-objects-hidden-around-corners/

 友情链接
友情链接