








公众号/AI前线
作者 | Jesus Rodriguez
译者 | 谢丽
编辑 | Vincent
AI 前线导读:为了缩短从实验到产品的周期,Uber 推出了一个机器学习栈 PyML。这是一个库,使开发者能够以与生产运行时兼容的方式快速开发 Python 应用程序。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
 Uber 一直是加速真实世界机器学习解决方案实现最活跃的公司之一。就在今年,Uber 推出了 Michelangelo、Pyro.ai 和 Horovod 等技术,这些技术以现实世界中机器学习解决方案关键构建块为重点。近日,Uber 推出了一个机器学习栈,这一次是为了缩短从实验到产品的周期。PyML 是一个库,能够以与生产运行时兼容的方式快速开发 Python 应用程序。
Uber 一直是加速真实世界机器学习解决方案实现最活跃的公司之一。就在今年,Uber 推出了 Michelangelo、Pyro.ai 和 Horovod 等技术,这些技术以现实世界中机器学习解决方案关键构建块为重点。近日,Uber 推出了一个机器学习栈,这一次是为了缩短从实验到产品的周期。PyML 是一个库,能够以与生产运行时兼容的方式快速开发 Python 应用程序。
PyML 试图解决的问题是大规模机器学习应用中无处不在的挑战之一。通常,数据科学家用于原型模型的工具和框架与相应的生产运行时之间存在明显的不匹配。例如,对于数据科学家来说,使用基于 python 的框架(如 PyTorch 或 Keras)来生成实验模型,然后调整这些模型使其适合于像 Apache Spark ML 管道这样具有特定约束的运行时,这是非常常见的。机器学习技术专家把这个问题称为灵活性和资源效率之间的取舍问题。就 Uber 而言,数据科学家正在使用 Python 机器学习框架构建模型,这些框架需要由 Michelangelo 团队进行重构,以匹配 Apache Spark 管道的约束。
克服这一限制意味着扩展 Michelangelo 的功能,以支持使用主流机器学习框架创建的模型,同时保持训练和优化模型的一致性。
PyML 简介
Uber PyML 的目标是简化机器学习应用程序的开发,弥合实验和生产运行时之间的差距。为了实现这一点,PyML 以下面三个方面为重点:
下图说明了 PyML 的基本架构原则。
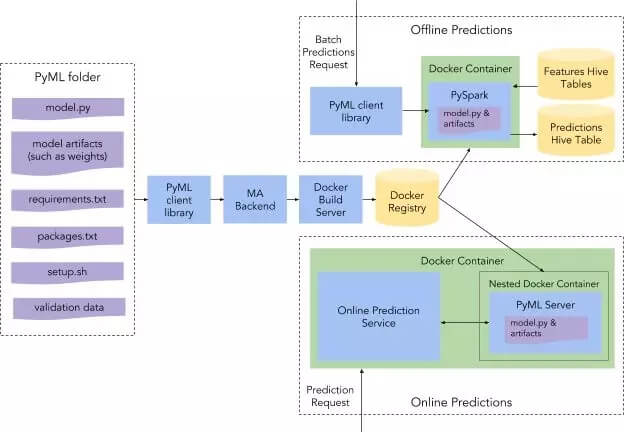
PyML 模型可以使用不同的机器学习框架编写,如 TensorFlow、PyTorch 或 Scikit-Learn。模型可以使用的数据集类型主要有两种:DataFrames 和 Tensors。DataFrames 存储表格式结构化数据,而 Tensors 存储多维命名数组。在创建模型之后,把它们调整为标准的 PyML 契约定义,这本质上是一个从抽象类 DataFrameModel 或 TensorModel 继承的类。在这两种情况下,用户只需要实现两个方法:一个是加载模型参数的构造函数,另一个是接受并返回 DataFrames 或 Tensors 的 predict() 方法。

在创建 PyML 模型之后,可以使用一致的结构把它们打包到 Docker 容器中。PyML 引入了一种基于四个基本构件的标准部署格式:

使用这种结构,开发人员可以使用以下代码打包和部署 PyML 模型。PyML Docker 镜像将包含模型和所有相应的依赖项。模型将可以立即在 Michelangelo 控制台执行。


PyML 支持批处理(离线)和在线执行模型进行预测。离线预测被建模为 PySpark 上的抽象。在那种情况下,PyML 用户只需提供一个 SQL 查询,与模型期望输入相匹配的列名和类型,以及存储预测输出的目标 Hive 表的名称。在后台,PyML 使用与在线模型相同的镜像和 Python 环境启动了一个容器化 PySpark 任务,以确保离线和在线预测之间没有区别。执行离线预测相对简单,如下面的代码所示:

PyML 模型的标准双操作(init、predict)契约简化了在线预测的实现。PyML 通过启用 Docker 容器的轻量级 gRPC 接口实现了在线预测,Docker 容器由一个如下图所示的常见的在线预测服务使用。根据请求,在线预测服务将通过 Mesos 的 API 以嵌入式 Docker 容器的形式启动相应的特定于 PyML 模型的 Docker 镜像。当启动容器时,它启动 PyML RPC 服务器,并开始监听来自在线预测服务的 Unix 域套接字上的预测请求。

PyML 通过弥合实验和运行时环境之间的差距,解决了大型机器学习应用程序中其中一个最重要的挑战。除了特定的技术贡献外,PyML 的架构可以适应不同的技术栈,可以作为组织开始机器学习旅程的重要参考。
关于 PyML 的更多技术细节,请查阅 Uber 技术博客:
https://eng.uber.com/michelangelo-pyml/
查看英文原文:
https://towardsdatascience.com/uber-introduces-pyml-their-secret-weapon-for-rapid-machine-learning-development-c0f40009a617

 友情链接
友情链接