








公众号/AI前线
策划编辑 | Debra
作者 | Yann LeCun, Jerome Pesenti, Mike Schroepfer
编译 | Debra
编辑 | Natalie

AI 前线导读: 本月,Facebook 人工智能研究院(FAIR)成立满五周年了!Facebook 这个社交网络巨头无疑对互联网产生了巨大的影响,不管是好的还是坏的。而 FAIR 的研究成果更是对 AI 研究社区和 Facebook 运营的方式,产生了不可磨灭的影响。
在这个特殊的时刻,FAIR 的创办者兼首席 AI 科学家 Yann LeCun、FAIR 现任负责人 Jerome Pesenti 以及 Facebook 首席技术官 Mike Schroepfer 在官网联合发布博客,盘点了 FAIR 五年来所做的事情以及达成的成就。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
Yann LeCun 表示:“没有深度学习,Facebook 就无法运营,它已经深入到 Facebook 的方方面面”。
据 LeCun 透露,在 FAIR 创办之前,Facebook 没有任何研究实验室,公司做的都是一些短期的工程项目,6 个月就算是很长的项目周期了。

在 Facebook 的前五年,Facebook CTO Mike Schroepfer 并不同意创建这个研究实验室,但直到 2013 年,AI 将成为 Facebook 未来成功的关键因素这个事实才变得清晰起来。
Yann LeCun 回忆,五年前在他到 Facebook CEO Mark Zuckerberg 家中赴宴之后没多久,FAIR 就成立了。LeCun 表示,当时他向 Zuckerberg 说明了 Facebook 建立一个研究实验室的重要性,而后者表示开放的基因存在于 Facebook 之中,这番话让 LeCun 觉得非常高兴。
FAIR 不是一个“温室”,几乎所有的研究成果最后都会对广泛的 AI 社区产生重要的影响。与此同时,硅谷的科技公司们也展开了 AI 竞赛,然而,Facebook 内部的 FAIR 和其应用机器学习(AML)团队各自为营,给了 Facebook 考虑其未来长期发展很大的空间。
以下为博客全文,由 AI 前线翻译整理:
五年前,我们创建了 Facebook 人工智能研究小组(FAIR),通过公开研究的方式推动人工智能的发展,为所有人带来益处,此机构旨在理解智能的本质以创造智能机器。从那时起,FAIR 收获颇多,并成长为一个国际研究组织,在门洛帕克(美国加利福尼亚州圣马特奥县东南部城市)、纽约、巴黎、蒙特利尔、特拉维夫、西雅图、匹兹堡和伦敦均开设了实验室。如今,人工智能已成为 Facebook 的核心,FAIR 也成为 Facebook 更大的 AI 组织中的一部分,该组织致力于人工智能研发的各个方面,从基础研究到应用研究和技术开发。
FAIR 在各方面的工作中采用开放模式,与社区广泛合作。我们的团队经常发布最前沿的研究,并尽可能开源我们的研究代码、数据集,以及如 PyTorch、fastText、FAISS 和 Detectron 等工具。这种开放式的方法成功推进了人工智能研究的发展。今年,FAIR 的研究人员在众多国际顶级会议中得到了认可,比如在 ACL、EMNLP、CVPR、ECCV 中得到了最佳论文奖,在 ECCV、ICML 和 NeurIPS 得到了时间检验奖项。我们知道,开放可以让所有人在 AI 上取得更快的进展。
使机器真正智能化是一项科学挑战,也是一项技术和产品工程挑战。 FAIR 研究的重点之一聚焦于解决推理、预测、规划、无监督学习等基本问题。反过来,这些研究领域又需要在生成模型、因果关系、高维随机优化和博弈论等领域有更好的理论理解。我们需要进行这些长期的研究探索,才能释放人工智能在未来的全部潜力。我们从过去五年中做过的所有项目中选择了一小部分,来展示了 FAIR 如何逐渐接近使命,为我们的领域做出贡献,并对世界产生影响。

FAIR 官博专门制作了一个动态时间线,展示 FAIR 这五年的重点项目(感兴趣的读者可以访问官博查看详情)
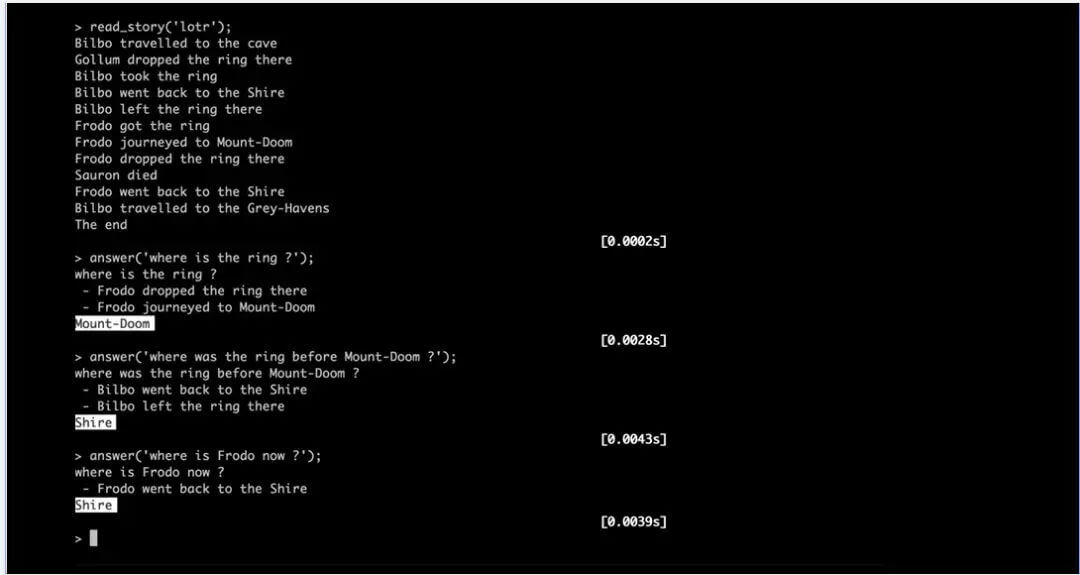
2014 年,FAIR 的研究人员发现了神经网络的一个内在局限性——长期记忆。虽然神经网络可以在数据集训练过程中学习,但是一旦这些系统开始运行,通常就无法存储新信息以解决以后的特定任务。因此,我们开发了一种新的学习模型机器,它们能够记住足够的交互,以回答一般知识问题并参考先前对话中的句子。在 2014 年关于此方法的论文中(https://code.fb.com/ai-research/fair-fifth-anniversary/), 我们通过一个支持内存的网络来回答有关《魔戒》系列剧情的问题,并根据提供给它的简短摘要进行测试。该系统能够学习简单的语言模式,概括未知单词的含义并做出正确回答。例如,在故事的最后,Frodo 在郡中,而戒指在末日火山(Mount Doom)中。
FAIR 在未来两年将继续研究这一方法,并拓展和探索相关领域。通过 StackRNN(https://research.fb.com/downloads/stack-rnn/) ,团队使用 push-pop 堆栈增强了 RNN,可以用无监督的方式从序列中进行训练。通过 bAbl(https://research.fb.com/downloads/babi/) ,团队构建了问答任务的数据集,提高了文本理解基准性能。bAbI 现在是开源项目 ParlAI 的一部分,包含从回应餐厅预订请求到有关电影演员的答案在内的数千个对话示例。我们还迭代了内存网络架构,使它们满足实际应用程序需求。这些更新包括端到端内存网络(https://arxiv.org/abs/1503.08895,可以较少的监督工作),键值存储网络(https://arxiv.org/abs/1606.03126, 可以通过从完全无监督获得的源信息,如维基百科条目,进行泛化来训练)。
长期以来,通过自我监督学习(SSL)探索大量未标记数据是 FAIR 将 AI 规模化的优先事项之一。使用 SSL,机器可以通过馈送未标记的图像、视频或音频来学习世界的抽象表示。例如,向机器展示视频剪辑对其进行训练并预测未来的帧。通过学习预测,机器捕获有关世界如何运作的知识并学习它的良好抽象表示。SSL 让机器通过观察来学习并积累大量关于世界的背景知识,这有点像人类和动物幼崽。我们希望,这可以形成一种常识。得到能够预测世界的模型也是构建人工智能系统的关键,这种模型应该可以推理、预测其行为的后果,并在现实世界中采取行动。
2014 年,来自蒙特利尔大学 MILA 的研究人员提出了一种新的无监督学习方法,称为生成对抗网络(GAN)。我们立即被自我监督学习的潜在应用吸引了。然而,虽然 GAN 看起来很有潜力,但只是在一些“玩具”问题(非真实世界中的实际问题)上得到了证明。从 2015 年开始,我们发表了一系列论文,这些论文有助于说服研究界,GAN 真的可以起作用。通过将两个神经网络相互对抗,我们使用 GAN 来训练机器在存在不确定性的情况下进行预测。在典型的 GAN 架构中,生成器网络基于一堆随机数(可能是过去的视频帧)生成数据,例如图像或视频帧。同时,鉴别器网络必须能够区分真实数据(即真实图像和视频帧)和生成器生成的“假”输出。这样的持续对抗能同时优化两个网络,并产生越来越好的预测结果。
我们的每篇论文都集中在 GAN 的不同变体上,包括深度卷积生成对抗网络(DCGAN https://arxiv.org/abs/1511.06434) 和拉普拉斯对抗网络(LAPGAN http://papers.nips.cc/paper/5773-deep-generative-image-models-using-a-laplacian-pyramid-of-adversarial-networks) 中的图像生成,以及对抗梯度差异损失预测器(AGDL https://arxiv.org/abs/1511.05440) 中的视频预测。但所有这些成果的最大贡献,是表明 GAN 可以“生成”看起来真实的图像,例如,不存在的卧室、人脸或狗等。

由生成网络创建的一系列时装设计
此后,其他研究人员开始研究我们在 GAN 中的工作,并使之生成出了令人惊叹的高分辨率图像。
但是,GAN 同时也因很难调整并且经常无法收敛而臭名昭著。因此,FAIR 通过专注于理解理论层面的对抗性训练,探索使 GAN 更可靠的方法。2017 年,我们引入了 Wasserstein GAN(WGAN https://arxiv.org/abs/1701.07875) 方法,该方法提出了一种使鉴别器变得“平滑”且更有效的方法,以告诉生成器如何改进其预测。WGAN 本质上是第一个在广泛应用中可以稳定收敛的 GAN。这避免了在系统优化时需要平衡鉴别器和生成器输出的问题,提高了学习的稳定性,特别是对于高分辨率图像生成任务。
从那时起,FAIR 研究人员和 Facebook 工程师开始在各种应用中使用对抗性训练方法,包括长时间视频预测和时尚作品的创作。但是,GAN 真正有趣的是它们对于未来的意义。作为一种全新技术,它创造了在拥有少量数据的领域生成数据的可能。未来,GAN 可能将成为我们构建可以自主学习机器的关键工具。
文本理解不是单一的任务,而是一个庞大的子任务矩阵,它将单词、短语和整个语言数据集组织成机器可以处理的格式。但在大部分工作可以进行之前,文本本身必须分类好。多年前,诸如 word2vec 之类的 NLP 模型通过广泛的、基于单词的训练对文本进行分类,模型为其训练数据集中的每个单词分配不同的向量。对于 Facebook 来说,这种方法太慢了,也太依赖于完全监督的数据。我们需要一种最终可以分类数百种甚至上千种语言的文本分类方法。该系统需要能够扩展到整个基于文本的功能和服务,以及我们的 NLP 研究。
所以在 2016 年,FAIR 构建了 fastText(https://code.fb.com/ml-applications/expanded-fasttext-library-now-fits-on-smaller-memory-devices/) ,这是一个快速进行文本分类和学习单词表示的框架,它考虑了分类单词的更大形态。在 2017 年发表的一篇论文中(https://arxiv.org/pdf/1607.04606.pdf) ,FAIR 提出了一个模型,将向量分配给“子词单位”(例如,3 或 4 个字符的序列)而不是整个单词,让系统为训练中没有出现的单词创建表示。最终,该模型的分类可以扩展到数十亿个单词,并从新的、未经训练的单词中学习,同时速度也比普通的深度学习分类器训练快得多。在某些情况下,fastText 在几秒钟内就可以完成之前模型需要花费数天才能完成的训练任务。
事实证明,FastText 对基于 AI 的语言理解研究和应用做出了重要贡献,现在它已有 157 种语言版本。原论文在其他出版物中被引用了一千多次,而 fastText 成为字嵌入系统最常用的测试标准之一。在 Facebook 之外,fastText 已经被用于各种各样的应用程序,从大家比较熟悉的,如消息回复建议,到充满异国情调的, 一个名为 The Great Outdoors 的“算法剧院” ,它使用 fastText 对互联网评论进行筛选并将结果作为表演的脚本。该框架部署在 Facebook 上,对 19 种语言的文本进行分类,并与 DeepText 结合进行翻译和自然语言理解。
快速、准确和灵活的翻译是帮助世界各地人们进行交流的关键。因此,FAIR 在早期就开始寻找一种优于当时最先进的统计机器翻译的新方法。建立基于 CNN,集速度、准确性和学习能力为一体的神经机器翻译(NMT https://code.fb.com/ml-applications/a-novel-approach-to-neural-machine-translation/) 架构花了我们三年的时间 。(FAIR 在 2017 年发表了一篇文章 https://arxiv.org/abs/1705.03122, 详细介绍了其工作原理。)在我们的实验中,这种方法使 RNN 速度提高了 9 倍,同时保持了最先进的准确率。

Facebook 神经机器翻译系统图解说明
我们的 CNN 不仅可以更轻松地在更有限的数据集上训练,而且能更好地理解拼写错误或缩写单词,例如将“tmrw”翻译为“mañana”。总的来说,NMT 使得翻译准确性平均提高 11%,翻译速度提高 2.5 倍。除了改进我们自己的系统之外,我们还开发了 fairseq 代码和模型(https://github.com/facebookresearch/fairseq) ,fairseq 是我们用于基于 CNN 系统的序列到序列建模工具包。
为了避免需要大量翻译训练数据集(通常称为语料库),我们还在探索其他方法,如多语言嵌入,这可以实现跨多种语言的训练。去年,我们发布了 MUSE(https://github.com/facebookresearch/MUSE) ,这是一个开源 Python 库,提供了两种不同的学习多语言嵌入的方法:一种是有监督方法,使用库中包含的 110 种双语词典,另一种是新的无监督方法,没有平行语料库也能在两种语言之间构建新的双语词典。接着,我们在一篇获得 EMNLP 奖的论文中(https://arxiv.org/abs/1804.07755) 证明了无监督翻译完整句子的训练有了显著的改进。
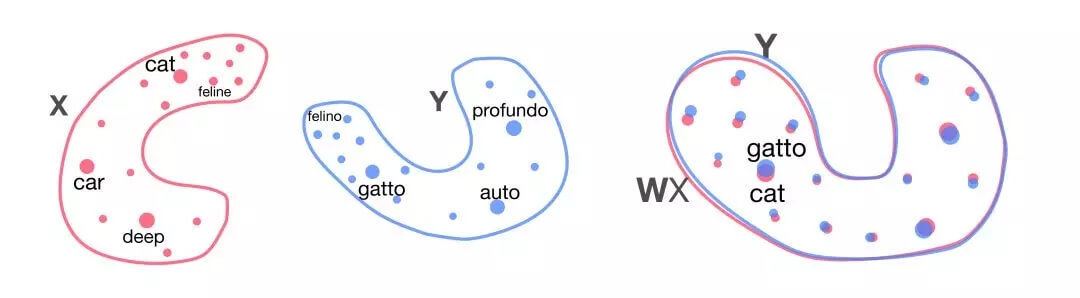
可以通过简单的旋转(右)对齐两种语言(左)的二维字嵌入。旋转后,通过最近邻搜索进行单词翻译。
通过分享像 fairseq 和 MUSE 这样的研究和资源,我们让其他人也可以使用更快、更准确、更通用的翻译技术,无论是用于研究目的还是生产应用。
人工智能的进步不仅取决于具有突破性的想法,还取决于拥有强大的平台和工具来测试和实施这些想法。建立这些系统并与全世界分享也是 FAIR 优先要做的事。
2015 年,我们开源了由 FAIR 创建的 Torch 深度学习模块(https://code.fb.com/developer-tools/fair-open-sources-deep-learning-modules-for-torch/) ,以加快更大规模的神经网络训练。2016 年,为我们发布了 Torchnet(https://code.fb.com/core-data/lighting-the-way-to-deep-machine-learning/) ,让社区可以更轻松、快速地构建有效且可重复使用的学习系统。不久之后,我们推出了 Caffe2 ,这是我们用于移动计算的模块化深度学习框架,目前正在全球超过 10 亿部手机上运行神经网络。然后,我们与微软和亚马逊合作发布了 ONNX,它是神经网络的通用代表,可以根据需要在框架之间任意切换。
需要特别指出的是,我们在 PyTorch上的工作兑现了 FAIR 对快速迭代、有意义的影响、开放系统以及与 AI 社区合作的承诺。一开始PyTorch 只是少数 FAIR 研究人员在开发。我们选择在 Torch 开源库的基础上构建深度学习框架,而不是构建一个全新的深度学习框架,我们还与英特尔和英伟达的加速库集成,以最大限度地提高速度。
2017 年初,我们发布了 PyTorch,两年之后,它已经成为 GitHub 上增长速度第二快的开源项目,也是全球 AI 开发人员的首选框架。10 月,数百名 AI 社区成员参加了第一届 PyTorch 开发者大会,聆听了加州理工学院、FAIR、fast.ai、谷歌、微软、英伟达、特斯拉等许多公司的演讲。现在,PyTorch 1.0 的发布集成了 Caffe2 和 ONNX 的模块化、面向生产的功能,提供从研究原型到生产部署的无缝路径,并与云服务和技术提供商进行深度集成。
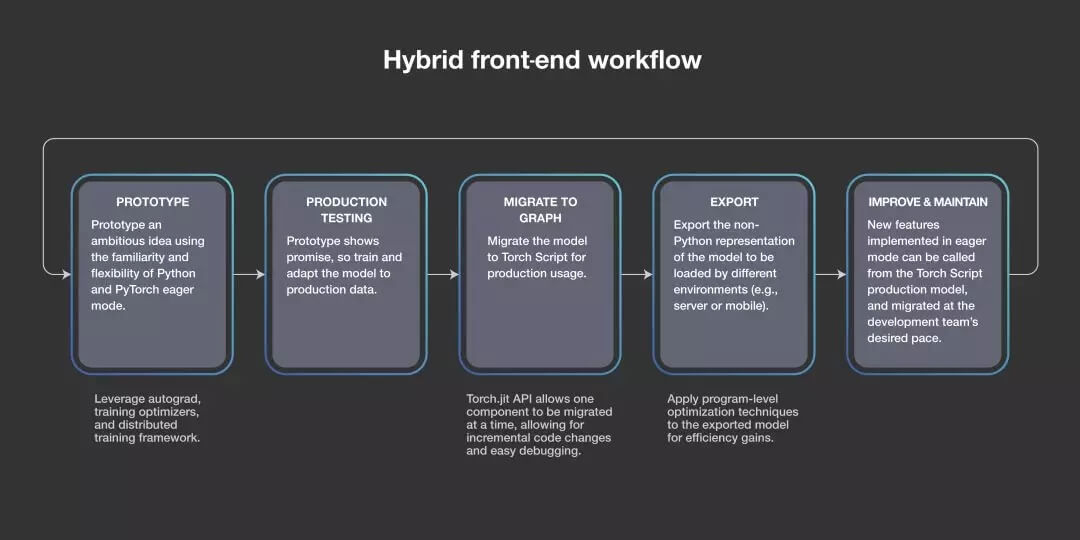
PyTorch 深度学习平台的混合前端流程图
PyTorch 集成在数十亿人使用的 Facebook 产品,以及 fairseq(-py) 等 FAIR 研究项目中,后者将翻译速度提高了 80%。PyTorch 也被用于我们的强化学习机器人 ELF OpenGo(https://research.fb.com/facebook-open-sources-elf-opengo/) 、EmbodiedQA,以及基于数十亿带标签的开放图像数据集训练图像识别网络。除了 Facebook 之外,PyTorch 还为 AllenNLP 的项目提供支持,让纽约大学教授 Narges Razavian 博士能够利用人工智能来改善疾病的早期检测和发现。现在,Udacity 和 fast.ai 正在帮助更多人加入 PyTorch。
因为 PyTorch 使模型从研究到生产变得更快更容易,我们在 Facebook AI 相似性搜索(FAISS)上的工作加速了大规模搜索的发展。FAISS 最初是一个内部研究项目,旨在更好地利用 GPU 来识别与用户偏好相关的相似性,现在,它是同类型中能够处理十亿级数据集最快的库。FAISS 带来了打造推荐引擎和基于 AI 的辅助系统的可能性。去年,我们将之开源(https://github.com/facebookresearch/faiss), 此后被开发者社区广泛采用,目前 FAISS 项目在 GitHub 上 star 数已经超过 5000,并集成到了英伟达的 GPU 加速 scikit-learn 库 cuML 中。
探索智能的本质是一种关于多感官模式的研究,但 FAIR 过去五年里在计算机视觉上的进步却是值得被记录的。
在 FAIR 诞生之前,Facebook 的一个小型 AI 专家团队在想办法更好地理解像素在图像中表示人物的方式,以便在正确的时间为人们展示合适的照片。快进到 2017 年,FAIR 的 Mask-CNN(https://arxiv.org/abs/1703.06870) 获得了计算机视觉国际会议最佳论文,它将计算机视觉世界的物体检测与语义分割结合到了一起。

计算机视觉技术的进展
正如该论文所述,“没有花里胡哨的东西,Mask R-CNN 在每项任务中都优于所有现有的单模型参赛作品,包括 COCO 2016 挑战赛冠军。”这项工作迅速成为更广泛的 AI 社区进行计算机视觉研究的基础。随后,我们将该技术集成到了 Facebook 开源的 Detectron 系统(https://research.fb.com/downloads/detectron/) 中,将元算法的直观易用性、速度和准确性带给了全球的研究人员。
这项基础工作现在支持着无数 Facebook 的系统,例如帮助视障人士自动替代文字和检测劣质内容的工具。它也成为了未来应用的基础:我们平台上的 AR 功能和 Portal 中的智能相机都源于这项工作。这项研究仍在继续,但重点转移到了视频,我们的 DensePose 项目(https://github.com/facebookresearch/DensePose) 将帮助系统理解视频内容和照片。
计算机视觉并不是 FAIR 探索解决大规模挑战的唯一领域。FAIR 还与 Facebook 的应用机器学习(AML)团队合作,解决训练速度和训练集大小,以及缺乏监督数据集的限制。
在今年早些时候发表的一篇论文中,AML 团队讨论了他们如何使用主题标签在大型开放图像数据集上训练图像识别网络,其中最大的包括 35 亿个图像和 17000 个主题标签。结果证明,它比以前发表的任何成果水平都要高出一个数量级,获得了迄今为止业界公布的最高准确率:85.4%。
FAIR 对训练速度的研究成就了这一突破,FAIR 能够将 ImageNet 的训练速度相比先前的水平提高一个数量级,训练时间缩短为不到一小时,使用了比以前常规实验中大一个数量级的小批量数据集进行 SGD 训练。用他们的话说:“为了实现这一结果,我们采用线性缩放规则来调整学习率作为小批量尺寸的函数,并开发一种新的预热方案,以克服训练早期优化上的挑战。”
随着训练速度的提高,我们能够对比以前更大的数据集进行弱监督学习定向研究。这两项结果都凸显了 FAIR 和 AML 之间进行合作的重要价值。当人工智能研究得到实用研究和生产应用的支持时,将会加速研究并获得更先进的成果。
当我们创建 FAIR 的时候,我们的最终目标是了解智能,发现其基本原则,并使机器更加智能化。现在,我们的目标没有改变。我们将继续将研究工作扩展到诸如开发能够通过自我监督学习获得世界模型的机器,训练机器进行推理,并训练它们规划和构思复杂的连续动作。这是我们致力于机器人、视觉推理和对话系统的原因之一。上述项目展示了我们过去曾走过的路,但科学和技术进步长途漫漫,让机器在人们的日常生活中变得足够智能,我们还有很长的路要走。
参考链接:
https://code.fb.com/ai-research/fair-fifth-anniversary/
https://techcrunch.com/2018/12/05/where-facebook-ai-research-moves-next/

 友情链接
友情链接