




那么对于数据驱动的机器人方法也不仅仅需要发展优秀的强化学习算法,同时也需要建立大规模的机器人学数据。




数据对于深度学习来说至关重要,而数据增强策略对于提升训练样本数据量、改善模型稳定性和鲁棒性,提高对于真实世界的适应性和泛化性具有重要的作用。

这是获得2018年国际机器人艺术大赛(RobotArt)的第一名的“艺术家”CloudPainter带来的作品,使用机器学习来重新诠释塞尚的印象派画作。

机器学习算法利用统计数据从大量数据中找到数据的模式。这里的数据可以有很多形式,如数值、文字、图像,甚至你点一次鼠标也算,反正就是你周围的一切一切。

FacebookAI Research、加州大学伯克利分校和伊利诺伊大学厄巴纳 – 香槟分校的科学家描述了一个通过使用逆机器学习模型摄取视频“伪标记”来学习层次结构。

Facebook最近公布了三组机器人,姑且就叫它们六足大昆虫、好奇宝宝、摸象的盲人好了。


人类具有适应环境变化的强大能力:我们可以迅速地学会住着拐杖走路、也可以在捡起位置物品时迅速地调整自己的力量输出,甚至小朋友在不同地面上行走都能轻松自如地切换自己的步态和行走模式。


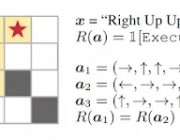

当时支持与反对方各自罗列出很多观点,但我们或许可以承认,这些讨论都是建立在这样一个前提上:新技术与农村生活的结合,已经开始触发一些改变。

在我们期待春节的最后一周,大洋彼岸天蓝水美的夏威夷将在1月27号到2月1号召开AAAI-2019人工智能会议。


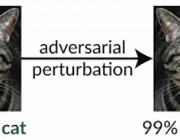
Topbots 总结了他们眼中 2018 年里 10 篇最为重要的 AI 研究论文,带领大家领略过去的一年中机器学习领域的关键进展。



FAIR 的创办者兼首席 AI 科学家 Yann LeCun、FAIR 现任负责人 Jerome Pesenti 以及 Facebook 首席技术官 Mike Schroepfer 在官网联合发布博客,盘点了 FAIR 五年来所做的事情以及达成的成就。

AI的火爆,让今天在加拿大蒙特利尔开幕的第32届神经信息处理系统大会(NeurIPS 2018),就成为了各国研究组织和企业刷存在感的香饽饽。










 友情链接
友情链接