




传统的材料研发模式主要依赖「试错」的实验方法或偶然性的发现,其研发过程一般长达 10-20 年。
该研究以「Explainable machine learning for profiling the immunological synapse and functional characterization of therapeutic antibodies」为题,于 2023 年 11 月 30 日发布在《Nature Communications》。
「这里的见解是,我们可以看到模型正在学习什么,以做出某些分子将成为良好抗生素的预测。从化学结构的角度来看,我们的工作提供了一个具有时间效率、资源效率和机械洞察力的框架,这是我们迄今为止所没有的。」麻省理工学院医学工程与科学研究所(IMES)和生物工程系医学工程与科学 Termeer 教授 James Collins 说道。

该研究以「DeepDelta: predicting ADMET improvements of molecular derivatives with deep learning」为题,于 2023 年 10 月 27 日发布在《Journal of Cheminformatics》。

公众号/ ScienceAI(ID:Philosophyai) 编辑 | 萝卜皮 机器学习方法,特别是在大型数 […]

密度泛函理论(DFT)的定理建立了多体系统的局部外部势与其电子密度、波函数以及单粒子约化密度矩阵之间的双射映射。

设计新型催化剂是解决许多能源和环境挑战的关键。尽管包括机器学习 (ML) 在内的数据科学方法有望加速催化剂的开发,通过机器学习方法很少发现真正新颖的催化剂,因为它最大的局限性是假设无法推断和识别特殊材料。

微观结构分割是一种从显微图像中提取结构统计数据的技术,是在广泛的材料研究领域建立定量结构-性能关系的重要步骤。



为了使量子材料的发现成为可能,来自太平洋西北国家实验室 (PNNL) 研究人员将详细的数据库作为他们的虚拟实验室。研究人员创建了一个新的未被充分研究的量子材料数据库,为发现新材料提供了一条途径。



最近,大型语言模型 (LLM),尤其是基于 Transformer 的模型在机器学习研究领域发展迅速。这些模型已成功应用于自然语言、代码生成、生物和化学研究等各个领域。

BM 欧洲研究院和苏黎世联邦理工学院的研究人员提出了 Regression Transformer(RT),这是一种将回归抽象为条件序列建模问题的方法。这为多任务语言模型引入了一个新方向——无缝桥接序列回归和条件序列生成。
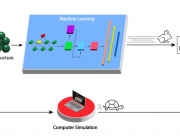
通过在阿贡的 Theta 超级计算机上进行的模拟,该团队创建了一个包含 20,000 个结构的数据库,用于氧与掺杂碳化钼的结合能。他们的模拟考虑了几十种掺杂元素和催化剂表面每种掺杂元素的一百多个可能位置。Theta 是阿贡领导计算设施、美国能源部科学用户设施办公室的一部分。

有的蛋白质在基态结构中缺乏 Pocket,因此被认为是「不可成药的蛋白质」。

RNA 分子上的甲基化修饰,关系到某些蛋白的表达,进而会影响到细胞的状态,对于疾病治疗药物开发具有潜在应用价值。


全局机器学习力场(MLFF)能够捕捉分子系统中的集体相互作用,由于模型复杂性随系统规模显著增长,现在可以扩展到几十个原子。



这一回,帝国理工学院和剑桥大学首次把目光转向了动物,并开创性地提出:AI可以从动物身上学习常识!

2020年2月13日,美国外国投资委员会(CFIUS)外国投资审查法案最终规则正式生效。这是对2018年外国投资风险审查现代化法案(FIRRMA)的进一步确定和细节规定的落实。










 友情链接
友情链接