




该研究以「Codon language embeddings provide strong signals for use in protein engineering」为题于 2024 年 2 月 23 日发布在《Nature Machine Intelligence》。

该研究以「DeepDelta: predicting ADMET improvements of molecular derivatives with deep learning」为题,于 2023 年 10 月 27 日发布在《Journal of Cheminformatics》。

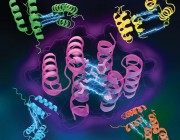
该研究以「Deploying synthetic coevolution and machine learning to engineer protein-protein interactions」为题,于 2023 年 7 月 28 日发布在《Science》。

最近,大型语言模型 (LLM),尤其是基于 Transformer 的模型在机器学习研究领域发展迅速。这些模型已成功应用于自然语言、代码生成、生物和化学研究等各个领域。
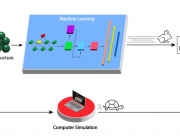
通过在阿贡的 Theta 超级计算机上进行的模拟,该团队创建了一个包含 20,000 个结构的数据库,用于氧与掺杂碳化钼的结合能。他们的模拟考虑了几十种掺杂元素和催化剂表面每种掺杂元素的一百多个可能位置。Theta 是阿贡领导计算设施、美国能源部科学用户设施办公室的一部分。

在这里,Meta AI 团队和纽约大学的研究人员展示了,使用大型语言模型从主序列直接推断结构,可以在高分辨率结构预测中实现一个数量级的加速。


化合物效力预测是机器学习在药物发现中的一种流行应用,为此使用了越来越复杂的模型。



代谢动力学模型通过机械关系将代谢通量、代谢物浓度和酶水平联系起来,使其对于理解、预测和优化生物体的行为至关重要。

公众号/ ScienceAI(ID) 编辑 | 萝卜皮 随着抗生素耐药性感染的增加以及不断演变扩大的大流行病毒 […]



古谚道:“熟读唐诗三百首,不会作诗也会吟。” 这句话放在目前的人工智能语言模型中也非常适用。

据 VentureBeat 报道,大约 90% 的机器学习模型从未投入生产。换句话说,数据科学家的工作只有十分之一能够真正产出对公司有用的东西。



这和三月份股市一惊一乍的表现完全不同,3月16日,道琼斯平均指数下跌了近13%,这是1987年以来最大的单日跌幅,这场危机史无前例的规模让人们变成了惊弓之鸟。

团队收集了来自905个病人的病理数据样本,主要借助MLP和CNN模型建立了理想的AI诊断模型。在与真实诊断结果经过比对后,团队认为它至少能够带来两个实际好处:提升CT分析效率和新冠诊断效率。
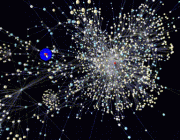

为了深入研究这一问题,来自谷歌的研究人员在NeurIPS上发表了一项对模型在数据集分布漂移情况下不确定性进行评测的工作,细致地分析了前沿的深度学习模型在数据分布漂移和处于分布外数据的作用下的不确定性。













 友情链接
友情链接