




德国柏林马克斯·普朗克学会弗里茨·哈伯研究所(Fritz-Haber-Institut der Max-Planck-Gesellschaft)和柏林洪堡大学(Humblodt Universität zu Berlin)的研究团队提出了一个通用的数据驱动框架,该框架提供定量预测以及定性规则,用于通过符号回归和敏感性分析的组合指导所有数据集的数据创建。
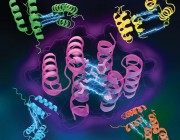
该研究以「Deploying synthetic coevolution and machine learning to engineer protein-protein interactions」为题,于 2023 年 7 月 28 日发布在《Science》。
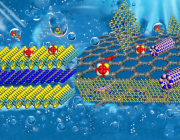
为了使量子材料的发现成为可能,来自太平洋西北国家实验室 (PNNL) 研究人员将详细的数据库作为他们的虚拟实验室。研究人员创建了一个新的未被充分研究的量子材料数据库,为发现新材料提供了一条途径。

但这种情况正在开始改变。借助一种称为稀疏卷积神经网络 (Sparse Convolutional Neural Network,SCNN) 的机器学习工具,研究人员可以专注于数据的相关部分并筛选出其余部分。

PENCIL的分类模式识别特定表型富集的亚群,与差异丰度测试算法具有相同的应用。然而,基于监督学习的 PENCIL 框架提供了一种更灵活的方式来同时选择基因和识别亚群。为了证明这一独特的特征,与其他方法进行比较的模拟被设计为需要基因选择。



最近,大型语言模型 (LLM),尤其是基于 Transformer 的模型在机器学习研究领域发展迅速。这些模型已成功应用于自然语言、代码生成、生物和化学研究等各个领域。

BM 欧洲研究院和苏黎世联邦理工学院的研究人员提出了 Regression Transformer(RT),这是一种将回归抽象为条件序列建模问题的方法。这为多任务语言模型引入了一个新方向——无缝桥接序列回归和条件序列生成。


法国国家科学研究中心和艾克斯-马赛大学以及荷兰马斯特里赫特大学的研究团队,利用模型比较框架并对比声学、语义(连续和分类)和声音到事件深度神经网络表示模型预测感知声音差异和 7 T 人类听觉皮层功能磁共振成像响应的能力。
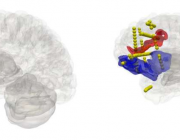
作为 HBP 的一部分,法国艾克斯-马赛大学(Aix-Marseille Université,AMU)的研究人员开发了整合患者测量数据的计算大脑建模技术。
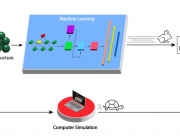
通过在阿贡的 Theta 超级计算机上进行的模拟,该团队创建了一个包含 20,000 个结构的数据库,用于氧与掺杂碳化钼的结合能。他们的模拟考虑了几十种掺杂元素和催化剂表面每种掺杂元素的一百多个可能位置。Theta 是阿贡领导计算设施、美国能源部科学用户设施办公室的一部分。


有的蛋白质在基态结构中缺乏 Pocket,因此被认为是「不可成药的蛋白质」。


RNA 分子上的甲基化修饰,关系到某些蛋白的表达,进而会影响到细胞的状态,对于疾病治疗药物开发具有潜在应用价值。

自 2022 年 11 月公开发布以来,ChatGPT 引起了全世界的关注,在全球数百万用户面前展示了人工智能的非凡潜力。

在这里,艾伦图灵研究所、伦敦大学、罗氏制药以及 Genentech 的研究人员,概述了该领域的研究进展,并提出了从具有结构化缺失的数据中学习的一系列重大挑战。

全局机器学习力场(MLFF)能够捕捉分子系统中的集体相互作用,由于模型复杂性随系统规模显著增长,现在可以扩展到几十个原子。



让 OpenAI 创建的图像生成系统 DALL·E 2 绘制一幅「金鱼在海滩上啜饮可口可乐」的图画,它会吐出超现实的图像。











 友情链接
友情链接