








公众号/机器之心
选自code.facebook
作者:Ves Stoyanov、Necip Fazil Ayan
机器之心编译
传统的自然语言处理系统只能对应于特定语言,如果想要让其应用支持多种语言,则需要从头开始构建相应数量的新系统。Facebook 最近提出的多语言嵌入方法可以在一些「已知」语言上训练 Classifier,应用于「未知」语言上,成功解决了社交平台中 AI 应用的多语言支持问题。本文将向你简要介绍这一技术背后的原理。
在 Facebook 上,超过一半的用户使用非英语语言。整个平台上,人们使用的语言超过 100 种。这种多元化的环境对于我们的服务是很大的挑战——如何为每个用户提供首选语言的无缝体验,尤其是在这些体验是由 Facebook 机器学习和自然语言处理(NLP)系统提供支持的情况下。为了向整个社区提供更好的服务——无论是推荐(Recommendations)和 M 建议(M Suggestions),还是检测和删除违反政策的内容——我们都需要建立一个能够适应多语言 NLP 任务的机器学习系统。
显然,现有的适用于特定语言的 NLP 技术无法应对这种挑战,因为支持每一种语言意味着从头开始构建全新应用。Facebook 找到了应对之策。近日,他们展示了最新提出的多语言嵌入技术,它可以帮助处理多语言的问题,帮助人工智能应用更快速地处理新语言的问题,为用户提供更好的产品体验。
跨语言 NLP 的挑战
NLP 的一个常见任务是文本分类,即将预定义类别分配给文本文件的过程。文本分类模型几乎用于 Facebook 的所有部分,如识别用户是否在贴文中请求系统推荐,或者自动移除负面内容,如垃圾信息。分类模型通常通过向神经网络提供大量标注数据作为样本来进行训练。模型通过该过程学习如何对新样本进行分类,然后执行预测以为用户提供产品体验。
训练过程通常针对某种特定语言,这意味着对于你想要分类的每种语言,你都需要收集大量训练数据。收集数据成本高昂且耗时,当我们想要支持 100 多种语言时,收集就变得更加困难了。
我们使用的另一种方法是收集大量英语数据来训练英语分类器,然后如果需要分类另一种语言的文本(如土耳其语),则将土耳其语文本翻译成英语,然后将译文发送给英语分类器。
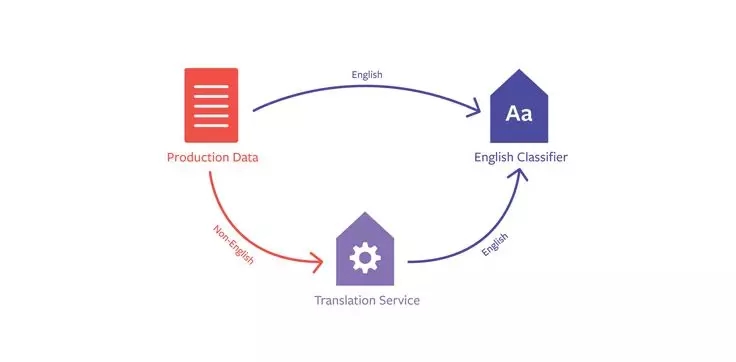
但是,该方法也有一些缺陷。首先,翻译中的误差会传输给分类器,导致性能下降。其次,它要求对我们想进行分类的非英语内容另外启用翻译服务。这导致分类产生极大延迟,因为翻译的耗时通常比分类要长。
我们认为这两种方法都不够好。我们想要更通用的解决方案,可以对我们支持的所有语言输出一致、准确的结果。
使用多语言词嵌入执行文本分类
目前文本分类模型使用词嵌入或将词表征为多维向量,将其作为理解语言的基本表征。词嵌入具有非常好的属性,它们非常易于操作,并且相似意义的词汇在向量空间中彼此距离很近。一般而言,词嵌入是针对特定语言的,每种语言的词嵌入需要单独训练,且存在于完全不同的向量空间。
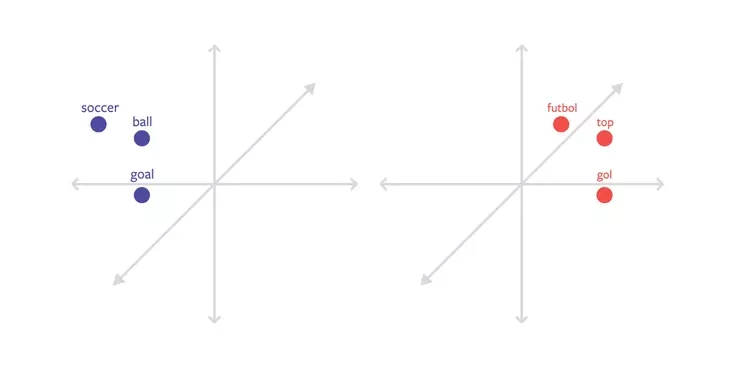
实现多语言文本分类的一种方法是开发多语言词嵌入向量。利用这种技术,每种语言的词嵌入都存在于同一个向量空间中,且不同语言间语义相似的词在向量空间中距离相近。例如,土耳其语中的「futbol」和英语中的「scoccer」在嵌入空间中距离非常近,因为它们在不同语言中代表着相同的意思。
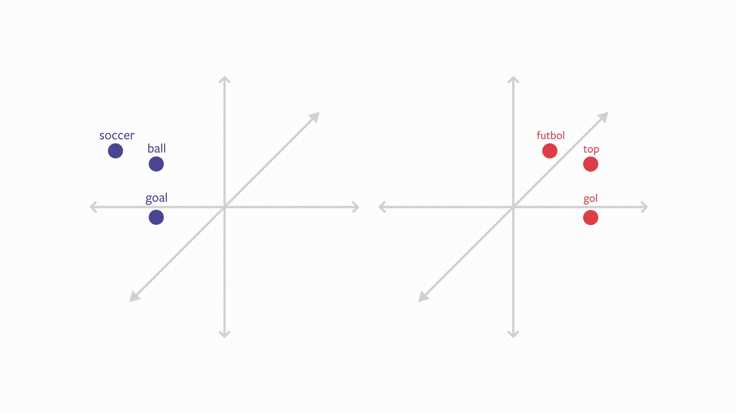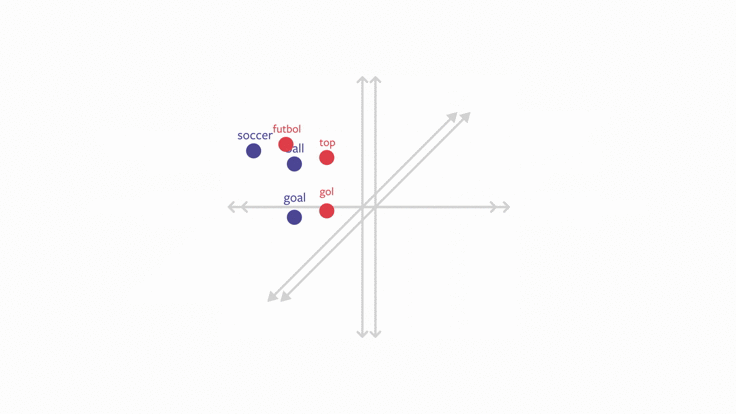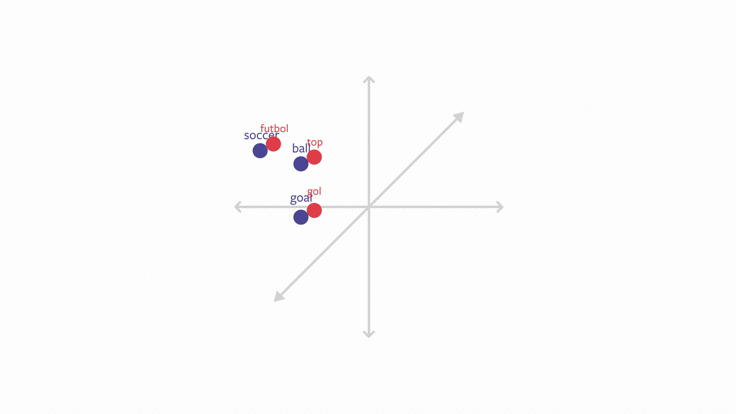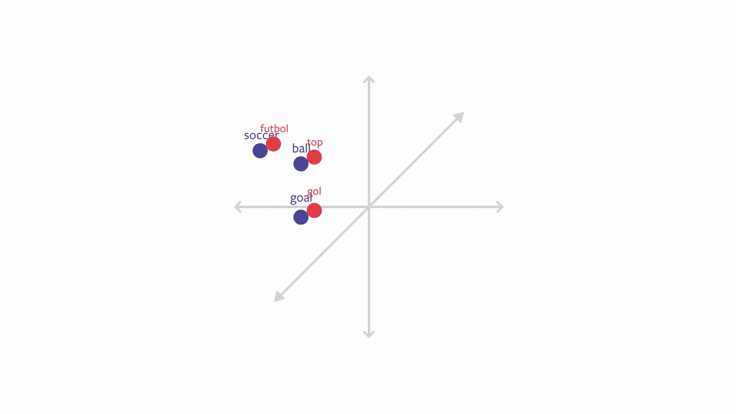
为了实现跨语言文本分类任务,我们可以使用这些多语言词嵌入作为文本分类模型的基本表征。由于新语言中的单词在嵌入空间中与已训练语言的单词相近,所以分类器也能在新语言上执行良好。因此,我们可以使用一种或多种语言进行训练,学习在一种从未训练过的语言中执行分类任务。
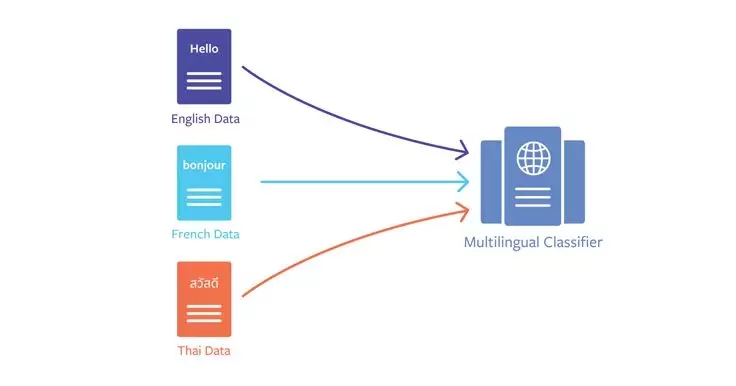
训练多语言嵌入
为了训练多语言词嵌入,我们首先使用 fastText 和数据(由来自 Facebook、Wikipedia 的数据组合而成)为每种语言分别训练词嵌入。然后我们利用词典将所有嵌入空间投影到共同空间(英语)。词典从平行数据(即由两种不同语言的意义相同的句子对构成的数据集)中自动导出,平行数据也用于训练翻译系统。
我们利用矩阵将嵌入投影到共同空间。该矩阵被用于最小化词嵌入 x_i 和它的投影 y_i 之间的距离。即,如果词典由(x_i,y_i)对构成,我们需要选择投影器 M,使得:
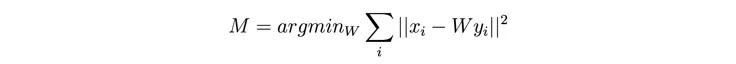
其中,M 表示令 L2 范数求和最小化的 W。此外,我们将投影矩阵 W 限制为正交矩阵,从而保持词嵌入向量之间的初始距离。
我们将这些嵌入整合到 DeepText,即我们的文本分类框架中。DeepText 包含多种将词嵌入作为基本表征的分类算法。我们在 DeepText 中将多语言词嵌入作为基本表征来训练多语言模型,并将词嵌入「固定」,或在训练过程中保持其不变。此外,工作流可以使用不同语言的训练集和测试集,并计算语言内和跨语言的性能。该方法使开发跨语言模型的进程变得更加容易。
对于一些分类问题,用多语言词嵌入训练的模型展现的跨语言性能非常接近于特定语言分类器的性能。我们观察到,当用在训练中未见过的语言进行测试时,准确率达到了 95%,和用特定语言数据集训练的分类器性能相当。之前的翻译输入方法的跨语言准确率通常只能达到特定语言模型的 82%。新的多语言方法的整体延迟时间相比翻译和分类方法,缩短了 20 倍到 30 倍。
在 Facebook 的大规模应用
我们完成了一些基本工作,如对于每个应用,从语言特定的模型转向多语言嵌入,作为通用的基础层:
我们在 Facebook 的生态系统中以不同方式应用多语言嵌入,从检测违反政策内容的 Integrity 系统到支持 Event Recommendation 等功能的分类器。
正在进行的工作
通过多语言嵌入进行扩展的方法前途无限,但是我们仍然有很多工作要做。
研究人员发现,目前的多语言嵌入对英语、德语、法语、西班牙语,及与其相近的语言性能略微好一些。该技术仍在继续扩展的过程中,未来会专注于对我们不具备大量数据的语言尝试新技术。Facebook 还将继续研究捕捉跨语言文化背景细微差别(如词组「it’s raining cats and dogs.」)的方法。
该研究的团队将与 FAIR 合作,从词嵌入到利用高级结构(如语句或段落)的嵌入改善多语言 NLP、捕捉语义含义。Facebook 希望这种技术的性能优于语言特定的模型,在文化和语言特定的信息和解析方式方面提高准确度。
原文链接:https://code.facebook.com/posts/550719898617409/under-the-hood-multilingual-embeddings/

 友情链接
友情链接