








公众号/AI前线
作者|George Seif
编译 | 郝毅
编辑|Emily
AI 前线导读:近年来,深度学习在计算机视觉领域已经占据了绝对的主导地位,在许多相关任务和竞赛中都获得了最好的表现。这些计算机视觉竞赛中最有名的就是 ImgaeNet。参加 ImageNet 竞赛的研究人员通过创造更好的模型来尽可能精确地分类给定的图像。过去几年里,深度学习技术在该竞赛中取得了快速的发展,甚至超越了人类的表现。现在我们来回顾一下深度学习的的演变,从而深入地了解它是如何发展的、我们可以从中学到什么以及未来应当如何发展。

ImageNet 竞赛的挑战
那么 ImageNet 挑战赛的难点在哪里呢?让我们先从它的数据开始说起。ImageNet 分类任务的数据是经过手工标注的 1000 类图片,这些图片来自于 Flickr 和其他搜索引擎。数据的分布情况如表格所示:

在 2012 年,ImageNet 已经拥有了近 130 万张训练图像。对于这种大规模图像分类任务,最大的挑战就是图像的多样性。我们通过几个例子来说明这个问题。
在下图中,左边是另一个图像分类挑战赛 PASCAL 中的样例图像。在 PASCAL 竞赛中,有近 20000 张训练图像和 20 个物体种类。这项竞赛中有很常见的类,比如像下图中的“鸟”,”狗“和”猫“。再看 ImageNet 挑战赛,跟前面的竞赛完全不同。ImageNet 并没有一个叫做”狗“的普通类,ImageNet 对每个品种的狗都有一个对应的类。不同于 PASCAL 只有”狗“这一种类,对于不同品种的狗,ImageNet 共有 120 个类。因此任何能够用于这个任务的算法或模型都必须能够处理这些非常细粒度的、详细的类,即使它们看起来非常相似并难以区分。
从技术角度讲,我们想要最大化类间变量。也就是说,对于包含两种不同品种的鸟类图像,我们的模型需要判断出它们之间的差异性,即使它们都是鸟,但是在我们的数据集中它们却是不同的类。

ImageNet 另一个具有挑战性的原因是:同一类物体可能看起来很不相同。我们来看一下下面这些图。左边的两幅图像都来自于”橙子“这一类,右边的两幅图像都来自于”桌球台“这一类。然而,每一张图像看起来都不一样!作为人类我们可以区分出其中一张图中的橙子被切开了而另一张图中的则没有;也可以看到一张图中的桌子是放大了的而另一张图中的没有。这就是所谓的类间变量。我们希望最小化这个变量,因为对于同一类的两张图像,我们需要深度学习模型能够认为它们看起来很相像。

深度学习在图像分类中的快速发展
自 2012 年以来,针对图像分类任务的深度学习模型的发展几乎每年都会有重大突破。由于数据规模庞大且具有挑战性,ImageNet 挑战赛一直是衡量图像分类任务的标杆。在这里,我们要深入了解一下深度学习在这个任务上的发展以及推动这一发展的主要框架。
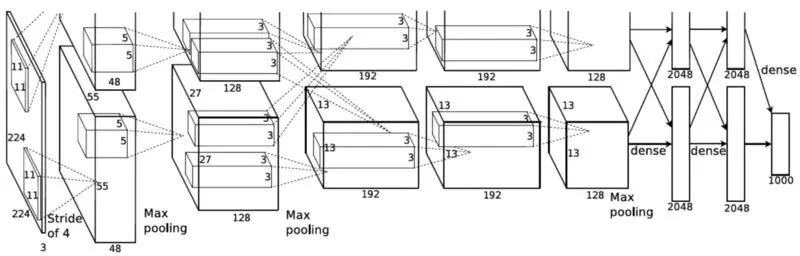
2012 年,一篇来自多伦多大学的文章引起了所有人的注意。这篇文章就是《ImageNet Classification with Deep Convolutional Networks》,发布在 NIPS 上。这篇文章随后成为了该领域最具影响力的论文,并且在 ImageNet 挑战赛上降低了 50% 的错误率,这是一个史无前例的进展。
这篇文章建议使用深度卷积神经网络 (CNN) 来进行图像分类。相比于今天使用的各种卷积神经网络,它相对来说比较简单。这篇文章的主要贡献是:
总的来说,AlexNet 是一项里程碑式的工作,它提供了使用 CNN 完成计算机视觉任务的基准和基本技术。
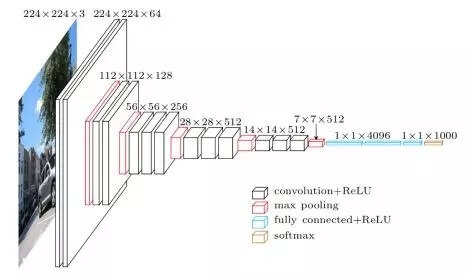
论文《Very Deep Convolutional Neural Networks for Large-Scale Image Recognition》于 2014 年问世,文中的 VGGNet 进一步扩展了包含许多卷积层和 ReLu 的深度网络。它们的核心思想是,你并不需要很多新奇的技巧来获得很高的准确率,大量的 3×3 卷积核和非线性网络就可以做到这一点!这篇论文的主要贡献是:

在文章《Going Deeper with Convolutions》中,GoogLeNet 框架首次真正解决了 计算资源 的问题,并提出了 多尺度处理 方法。当我们不断加深分类网络的深度,我们面临着需要使用大量内存的困境。另外,之前已经发展出了很多不同尺寸的滤波器:从 1×1 到 11×11,如何选择使用哪种滤波器?Inception 模块和 GoogLeNet 解决了这些问题,具体贡献如下:
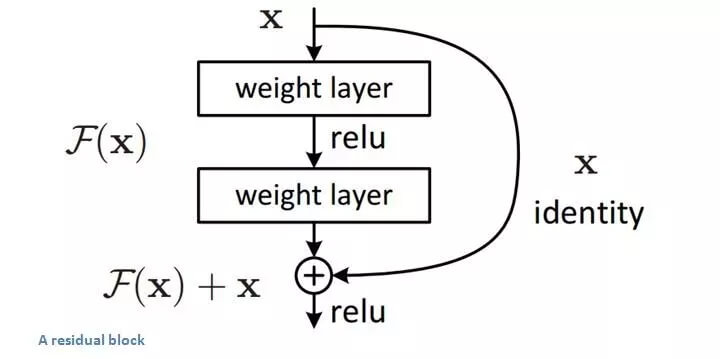
自从 2015 年《Deep Residual Learning for Image Recognition》首次发布,ResNet 在众多计算机视觉任务的精确度上获得了巨大的提升。ResNet 在 ImageNet 挑战赛上首次超越人类表现,并且残差学习 (residual learning) 如今被普遍应用于很多性能最好的网络:

在文章《Densely Connnected Convolutional Networks》中提出的 DenseNet 将快捷连接发展到了极致。DenseNet 扩展了 ResNet 中快捷连接的想法,但比其具有更稠密的连接:
以上就是过去几年中图像分类任务发展中的一些重要框架。令人激动的是,这些已取得的重大突破与进展已经被用于解决很多实际应用,但是仍然存在一个问题……
深度学习未来将如何发展
正如我们所回顾的那样,面向图像分类的深度学习研究一直蓬勃发展!我们已经在该领域取得了很多重大突破,甚至超越了人类的表现。深度神经网络现在已经广泛地应用于许多商业化的图像分类问题中,甚至成为了很多新兴科技的基础。
尽管深度学习已经取得了很多重大的进展,但是我们仍需保持谦虚的态度,力求让它变得更好。深度学习在图像分类问题中仍然存在很多挑战,如果我们想要获得更进一步的发展,如何解决这些挑战是至关重要的。这里我将回顾一些我认为重要的研究人员正在积极尝试解决的问题:
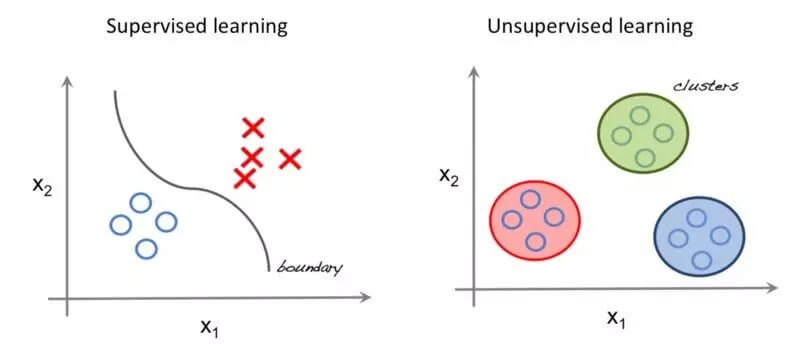
如今,大部分图像分类任务使用的深度学习方法都是有监督的,即我们需要大量的标注数据来进行训练,这些数据是单调的,而且难以获得。比如 ImageNet 挑战赛有 130 万张训练样本,但是只有 1000 个不同的种类,并且需要人工获取和标注所有的图像,这是非常费时费力的工作。
很多时候,当公司想要将一个图像分类网络应用到他们自己的具体应用中,他们需要使用迁移学习的思想来微调在 ImageNet 上预训练过的网络。为了微调网络,他们还需要收集自己的数据并进行标注,这仍然是乏味且费时的过程。
研究人员目前正在积极努力地解决这个问题,并取得了一些进展。越来越多的工作开始转向这个方面,比如快速有效地迁移学习,半监督学习和小样本学习。我们可能无法直接进入无监督学习,但是这些方法的研究是朝着正确方向迈出的重要一步。

生成对抗网络 (GAN) 的流行带来了图像分类的一个新挑战:对抗图像。对抗图像的类别对人类来说是显而易见的,但是深度网络却不能正确地识别。比如上面的图像,只是加入了轻微的失真 (表观上的),深度网络就将它从熊猫分到了长臂猿。
这张图像在人类看来这仍然是一只熊猫,但是由于某些原因导致深度网络进行了错误的分类。这在实际应用的时候是非常危险的:试想一下如果自动驾驶汽车没有识别出行人而直接开过去会怎样?导致这一问题的部分原因可能是由于我们对网络内部的原理和机制没有充分的理解,但是无论如何,研究人员正在积极地投身于解决这个具有挑战性的问题当中。
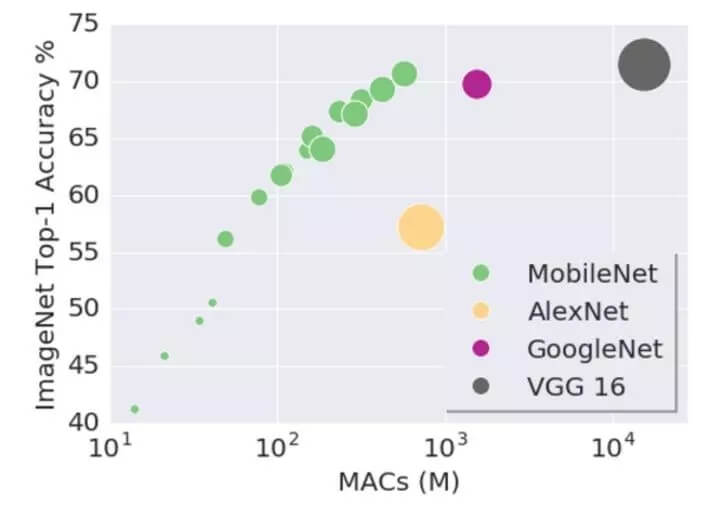
深度学习方面的很多进步是由硬件(尤其是 GPU)的改进所驱动的,GPU 可以高速地处理并行计算程序。由于使用矩阵操作,深度网络需要大量的乘加运算,而 GPU 非常擅长这些运算。这对于深度学习的发展来说非常棒,但是并不是所有地方都有 GPU 可以用!
许多顶尖的网络,包括上面已经讨论过的网络,都只能在高端 GPU 上正常运行。移动设备是一个巨大的市场,如何让深度神经网络也能服务于这个市场是关键一步。此外,随着网络越来越深,它们往往需要更多的内存,这也限制了更多的设备来运行网络。
实际上,这方面的研究最近已经有了很大的提升,逐渐流行的 MobileNets 是一种可以直接在移动端运行深度网络的框架。它使用另一种卷积方式来减少内存消耗和推理时间。
总结
本文介绍了图像分类的难点,并回顾了深度学习在该领域取得的惊人进展。同时提到一些正在面临的挑战,能够看到使用新的科学和工程方法来应对这些挑战是件十分令人激动的事情。
查看英文原文:
https://towardsdatascience.com/deep-learning-for-image-classification-why-its-challenging-where-we-ve-been-and-what-s-next-93b56948fcef

 友情链接
友情链接