








源 | 小象 编译 | 小象-陈志扬、陈圣茜
什么是集成方法?集成方法是一种机器学习技术,他结合了多个基本模型,目的是获取一个最佳预测模型。为了更好地理解这个概念我们需要回顾一下机器学习的最终目标和模型构建的整个过程,而本文则会深入应用集成学习的具体算法实例和应用原因来进行讲述。
本文将主要使用决策树对集成方法的定义与实用性进行简要的概述,但是需要知道的是集成方法还可以应用于决策树以外的其他算法中。
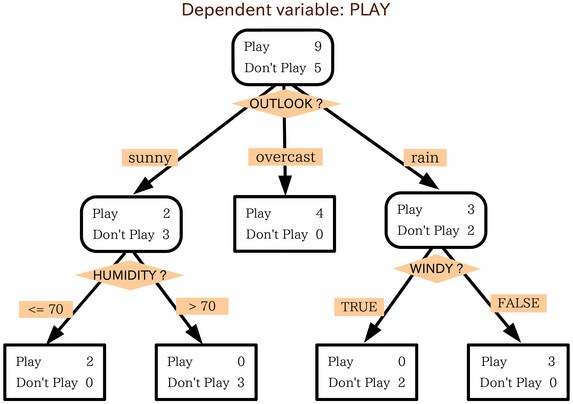
决策树通过一系列问题和条件来确定预测值。如上图,这个简单的决策树可以决定我们是否可以在外玩耍。它将几个天气因素纳入考量,在考虑每个因素之后,会给出一个决定或是提出另外一个问题。
在这个例子中,如果天气是阴天,我们将出门玩耍;然而如果是雨天,我们会再考虑是否刮风,如果刮风我们就不出去了。但是如果没有刮风,那就把鞋带系好吧——因为我们要出去玩耍了。
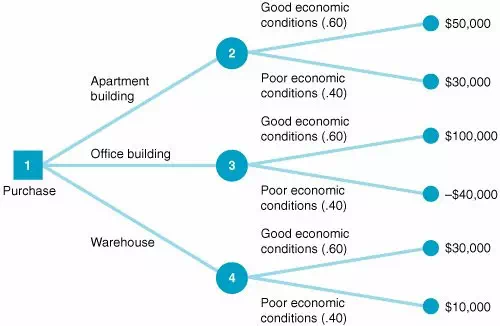
决策树同样也可以用相同的模式解决定量问题。在上图的决策树中,我们想要知道是否应该投资商业地产。它是办公楼,仓库,还是公寓楼?经济条件是好是坏?这项投资能带来多少回报?在用这个决策树的求解过程中,这些问题都需要被回答。
当我们构建一棵决策树的过程中,我们需要思索以下问题:我们要基于哪些特征来做决策?以什么阈值来把问题的答案归为是或否?在第一个例子中,如果我们在决策树中询问了有朋友一起会怎么样?
如果有,在任何情况下的决策都是出去玩耍;如果没有,我们才会继续依据天气来做出决策。通过添加一个额外的问题,我们希望更好地划分回答是与否的情况。
这就是我们为什么要使用集成方法的原因!相比较于依赖一棵决策树并期望它能在每一个分支点都做出正确的决定,集成方法允许我们同时参考一堆决策树样本,计算出在每个分支点应该使用哪些特征、提出什么问题,并根据这些决策树样本汇总的结果来做出最后的预测。
集成方法
1. BAGGing算法,或称Bootstrap-AGGregating算法。叫BAGGing这个名字,是因为它是综合了Bootstrapping和Aggregagtion而形成的一个组合模型。
若我们有一组数据样本,可以利用Bootstrap算法抽取出多个子集,然后在每个子集上训练一棵决策树,并利用算法将这些决策树融合成一个效果最好的分类器。下面这张图可以让我们更好地理解这个流程:

一个数据集,利用Bootstrap算法得到若干子集,然后在每个子集训练一棵决策树。所有决策树得到的结果可以被汇总得到一个最准确、高效的结果。
2. 随机森林模型。随机森林模型可以认为是类似于BAGGing的一种算法,只是在细节上稍有不同。在确定如何分支与做决策时,BAGGing算法中的决策树可以从所有特征中去选择。
因此,即使通过Bootstrap算法得到的子样本组也许有细微差异,数据整体上还是会被每棵决策树以相同的特征开始划分。与此相反,随机森林模型在随机选取的一部分特征中,选取特征来划分。
相比于在每个节点都使用相似的特征来划分,随机森林模型在各个子模型间体现出了更多的差异——因为每棵决策树会基于不同特征集合来划分。这种程度的差异性使得随机森林能在更大的范围内进行模型融合,从而得到一个更加准确的预测。我们可以参考以下这张图来理解这个过程。

随机森林使用数据的一组随机特征,并利用每一组生成若干棵随机树。这些树在最后会被整合成一个模型。
与BAGGing算法相似,我们需要用Bootstrap算法从数据集中取出若干子集,并在每个子集上训练一棵决策树。然而,这些决策树会根据不同的特征分支(上图中的特征用形状来表示)。
总结
任何机器学习问题的目的都是找到一个模型能最好地预测我们所想要的结果。相比较于构建一个模型并寄希望于这个模型是我们所能生成的最好的模型,集成方法参考了多个模型并将他们融合成一个最终模型。
我们需要知道决策树不是使用集成方法的唯一,只是在如今的数据科学领域最受欢迎且相关的一种而已。

 友情链接
友情链接