








公众号/AI前线
作者|Ben Letham 等
译者|Sambodhi
编辑|Debra
AI 前线导读:贝叶斯优化其实就是在函数方程不知的情况下根据已有的采样点预估函数最大值的一个算法。贝叶斯优化的主要目的是与大部分机器学习算法类似,学习模型的表达形式,在一定范围内求一个函数的最大(小)值。针对机器学习的高斯过程 (Gaussian Processes,GP) 是一个通用的监督学习方法,主要被设计用来解决回归问题。Facebook 是全球最大的社交网站,如此庞大体量的在线系统要如何有效地调优呢?让我们看看贝叶斯优化在这方面是如何应用的。
Facebook 依靠庞大的后端系统,每天为数十亿人提供服务。在这些后端系统中,许多都有大量的内部参数。例如,支持 Facebook 的 Web 服务器使用 HipHop 虚拟机(HHVM)来处理服务请求,而 HHVM 有几十个参数用于控制即时编译器。另一个例子是,用于各种预测任务的机器学习。这些系统通常都会涉及多层预测模型,具有大量参数,用于确定模型如何连接在一起,从而产生最终建议。这些参数必须通过使用实时随机实验仔细地进行调优,也称为 A/B 测试。这些实验中,每一项都可能需要一周或更长时间,因此挑战在于:用尽可能少的实验来优化一组参数。

A/B 测试通常用作改进产品的一次性实验。我们的论文《Constrained Bayesian Optimization with Noisy Experiments》,现已在 Bayesian Analysis 期刊上发表。在这篇论文中,我们描述了如何使用一种被称为贝叶斯优化(Bayesian optimization)的人工智能技术,根据先前测试的结果自适应地设计一轮 A/B 测试。与网格搜索或手动调优相比,贝叶斯优化可以让我们用更少的实验共同调优更多的参数,并找到更好的值。我们已经在一系列后端系统中使用这些技术进行了数十次参数调优实验,发现它在机器学习系统调优方面特别有效。
AI 前线注:论文《Constrained Bayesian Optimization with Noisy Experiments》见:https://projecteuclid.org/euclid.ba/1533866666
在线系统参数调优的一种典型方法是手动运行小型网格搜索,分别对每个参数进行优化。贝叶斯优化构建了参数与感兴趣的在线结果之间关系的统计模型,并使用该模型来决定运行哪些实验。这种基于模型的方法具备几个关键的优势,特别是优化在线机器学习系统的方面。
使用参数维度进行更好地扩展:考虑到可运行的在线实验数量的限制,网格搜索或手动调优不能用于同时进行多个参数调优。模型的使用允许贝叶斯优化扩展到更多的参数;我们通常会共同优化多达 20 个参数。这对于机器学习系统而言很重要,因为在这些系统中,参数之间的交互经常需要进行联合优化(joint optimization)。
减少实验次数:贝叶斯优化允许我们在多轮实验中借用信息:对连续空间中的参数值进行测试不仅可获得有关其结果的信息,还可以获得有关附近点的信息。这使得我们能够大大减少探索空间所需的实验数量。
更好的实验结果:该模型能够识别不太可能产生良好结果的部分空间,并避免对这些参数值进行测试。这改善了实验组内的体验。
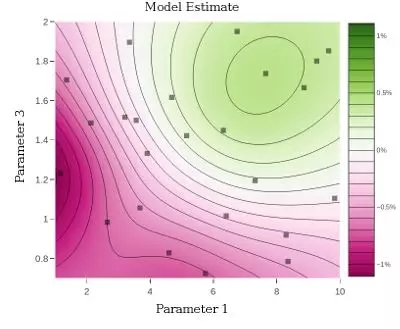
理解参数空间:建模允许我们可视化并更好地理解参数如何影响感兴趣的结果。如下图所示,显示了 8 参数实验的二维切片,这张可视化的典型图是为我们更好地理解参数空间而绘制的:
我们将在本文中介绍贝叶斯优化的高级描述,然后阐述本论文的工作和一些实验结果。
贝叶斯优化是一种解决优化问题的技术,其中目标函数(即感兴趣的在线指标)没有分析表达式,而是只能通过一些耗时的操作(即随机实验)来评估。通过数量有限的实验来有效地探索多维空间的关键是建模:真正的目标函数是未知的,但我们可以将模型拟合到目前为止的观察值,并使用该模型来预测参数空间的良好部分,我们应该进行额外的实验。
高斯过程(Gaussian process,GP)是一种非参数贝叶斯模型。因为高斯过程提供了很好的不确定性估计(uncertainty estimates),并且易于分析处理,因此它在贝叶斯优化中工作得很好。它提供了在线指标如何随感兴趣的参数变化的估计值,如下图所示:
AI 前线注:高斯过程可参阅 https://en.wikipedia.org/wiki/Gaussian_process
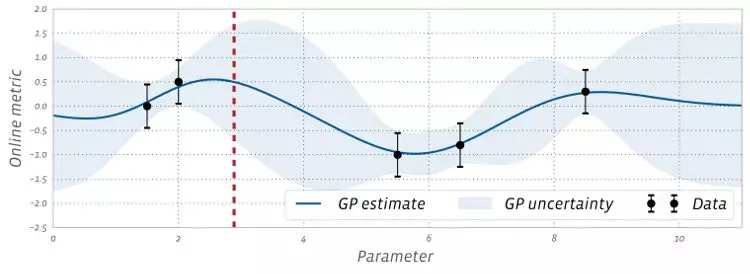
上图中的每个数据标记对应于该参数值的 A/B 测试额度结果。通过平衡探索(高不确定性)和开发(良好的模型估计),我们可以使用 GP 来决定接下来要测试的参数。这是通过计算采集函数(acquisition function)来完成的,该函数使用任何给定参数值估计进行实验的值。
假设我们要尝试决定是否应该使用参数配置 x 进行实验。在 x 处的观察值是多少?这个问题的答案取决于效用函数(utility function)。假设我们计划在观察 x 之后结束优化,优化的效用就是它找到的最佳点的值。在这种情况下,观察 x 的效用就是它的 f(x) 值比当前最佳值提高了多少,我们称之为 x*(假设我们正在最大化):
I(x) = max(0, f(x) – f(x*)).
I(x) 是一个随机变量,因为 f(x) 是一个随机变量,但 f(x) 的后验由 GP 模型解析可知。期望增量(expected improvement,EI)获取函数选择在 GP 后验下使 I(x) 的期望值最大化的点 x。EI 是一种常用的采集函数,因为这种期望具有易于计算的解析形式,在实践中表现良好。如下图所示,图上为模型拟合的 EI 值:

将 EI 最大化的参数(红色虚线)在下次实验中进行测试。然后根据该实验结果更新模型,并重新计算 EI 以选择新的候选项。循环重复执行上述操作,直到搜索完成,如上面的动画中多次迭代所示。
高斯过程假设响应面是平滑的,这使我们能够从参数空间中的附近观测中借用信息。它使我们确信已彻底探索了这个空间,而无需实际测试每个可能的参数值。
使用贝叶斯优化对在线系统进行调优有几个挑战,这些在线系统优化催生了本文中描述的工作。
噪声:通过随机实验观察到的噪声水平通常相当高,特别是与典型的贝叶斯优化(如超参数调优)的机器学习应用相比。
约束:除了要优化的指标之外,还必须始终满足约束条件。这些约束通常是噪声指标本身,因此我们必须考虑他们的可行性的后验分布。
批量实验:因为在线实验非常耗时,所以它们通常不以线性顺序运行,而是在大批量的并行测试中运行,如上面的动画所示。在我们的实验中,我们经常一次评估多达 50 种配置,因此需要贝叶斯优化过程,它可以返回大批待评估的点。
对 EI 的扩展可以处理这些问题,但是噪声通常是通过启发式方法处理的,当噪声水平达到典型的 A/B 测试时,我们发现这种方法的性能很差。对于观测噪声,我们现在不仅在 f(x) 的值上存在不确定性,而且我们也有其他不确定性:其中观测是当前最好的,x 及它的值 f(x)。处理观测噪声的一种常见方法是忽略它,并使用嵌入式估计量(plug-in estimator),通过替换 GP 的均值估计 f(x*)。
在本文中,我们阐述了一种处理观测噪声的贝叶斯方法,其中包含了 EI 所期望的由噪声引起的后验不确定性。也就是说,我们不计算 I(x) 在 f(x) 后端的期望,而是计算在 f(x) 和 f(x*) 的联合后验下计算它。这种期望不再具有 EI 这样的封闭形式,但我们可以很容易地从 GP 后验中得到过去观测值 f(x_1),…,f(x_n) 绘制样本,并且条件分布 f(x)|f(x_1),…,f(x_n) 具有封闭形式。因此,期望值服从蒙特 – 卡洛近似值(Monte Carlo approximation),其中我们对 f(x_1),…,f(x_n) 进行采样,然后采用条件期望 E[I(x) | f(x_1), …, f(x_n)] 的封闭性是的 f(x_1),…,f(x_n)]。我们在论文中证明了拟蒙特卡洛积分(quasi-Monte Carlo integration)能够很好地估计这种期望并能有效地进行优化。
我们使用了本文中描述的方法来优化 Facebook 上的多个系统,并在文中描述了两个这样的优化。首先是优化 Facebook 排名系统之一中的 6 个参数。索引器中涉及到这些特定的参数,这些参数将聚集要发送到预测模型的内容。第二个示例是优化 HHVM 的 7 个数字编译器标志。此优化的目标是降低 Web 服务器上的 CPU 使用率,同时限制不增加峰值内存使用率。下图显示了测试的每个配置的 CPU 使用率(总计 100),以及每个点满足内存约束的概率:
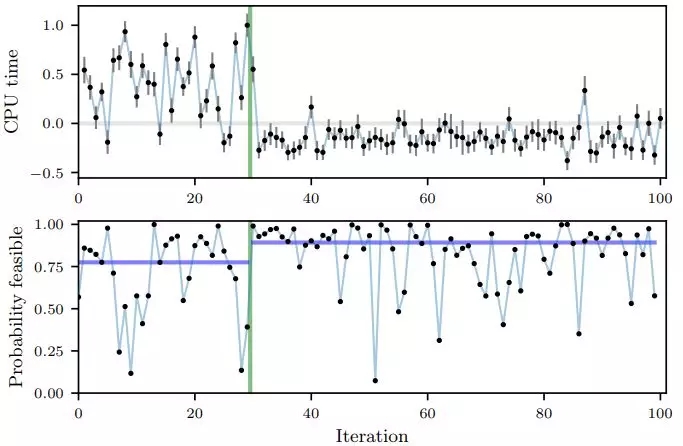
前 30 次迭代是随机生成的配置(直到绿线),然后使用贝叶斯优化来确定要评估的参数配置。在这个实验以及我们运行过的其他实验中,我们发现贝叶斯优化能够找到更好的配置,更有可能满足约束条件。在此优化中发现的编译器标志设置是在开源 HHVM 中设置的新默认值。
我们发现,利用本文描述的方法,贝叶斯优化是一种通过噪声实验进行优化的有效且强大的工具。它取代了手动探索多维空间的方式,让工程师的生活变得更加轻松,并改善了后端系统和机器学习基础设施的在线性能。
原文链接:
https://research.fb.com/efficient-tuning-of-online-systems-using-bayesian-optimization/

 友情链接
友情链接