








公众号/AI 科技评论
AI 科技评论按:Topbots 总结了他们眼中 2018 年里 10 篇最为重要的 AI 研究论文,带领大家领略过去的一年中机器学习领域的关键进展。现在点开了这份清单的人显然是极为幸运的,获得了一个精彩瞬间回放的机会。
不得不说,考虑到这个领域极快的发展速度和极多的论文数量,肯定还有一些值得阅读的突破性论文没能包括在这份榜单中。不过这份清单是一个好的开始。
「用于文本分类的通用语言模型的精细调节」
论文地址
https://arxiv.org/abs/1801.06146
内容概要
两位作者 Jeremy Howard 和 Sebastian Ruder 提出了可以用预训练的模型解决多种 NLP 任务的想法。通过这种方法,研究人员不需要为自己的任务从零开始训练模型,只需要对已有的模型做精细调节。他们的方法,通用语言模型精细调节 ULMFiT ,得到了当时最好的结果,比其他模型的错误率降低了 18% 到 24%。更令人钦佩的是,ULMFiT 只用了 100 个有标签样本得到的结果就可以和用 10K 有标签数据从零开始训练的模型一样好。
论文思想要点
为了应对缺乏标注数据的问题,以及让 NLP 分类任务更轻松、更省时,他们提出了把迁移学习用在 NLP 问题中。这样,研究人员们不再需要从零开始训练新模型,只需要找到一个已经在相似的任务上训练完毕的模型作为基础,然后为新的具体问题微调这个模型即可。
然而,为了让这样的做法发挥出理想的效果,这个微调过程有几个细节需要注意:
领域内学者评价
未来可能的相关研究
AI 科技评论详解文章
ImageNet 带来的预训练模型之风,马上要吹进 NLP 领域了
「模糊梯度防御带来的只是安全的假象:绕过对抗性样本的防御」
论文地址
https://arxiv.org/abs/1802.00420
内容概要
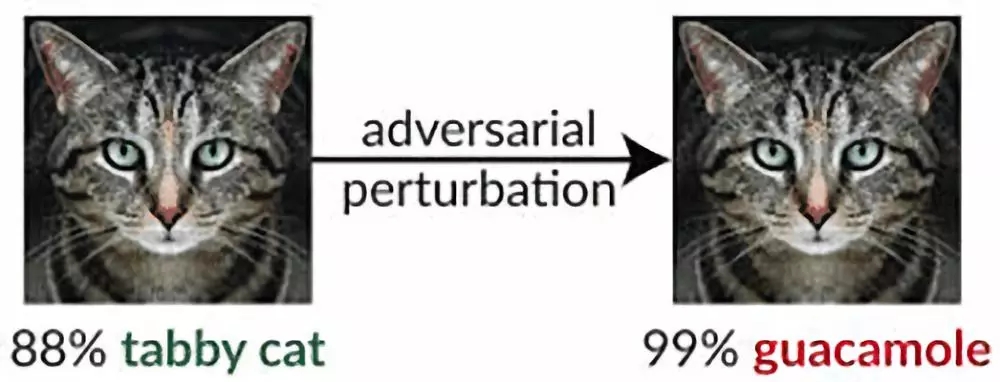
研究人员们发现,对于对抗性样本的防御,目前主要使用的是梯度模糊方法,但这种方法并不能带来真正的安全,因为它可以被轻松规避。这篇论文了研究了三种使用了梯度模糊的防御方法,并展示了可以绕过梯度模糊防御的技巧。他们的发现可以帮助目前使用了梯度模糊防御的组织机构考虑如何强化自己的方法。
论文思想要点
目前有三种常见的梯度模糊做法:
基于梯度的方法有一些问题,我们可以看到下面这些迹象:
论文的关键成果是,通过实验表明如今使用的大多数防御技术都还很脆弱。ICLR 2018 接收论文中的 9 种防御技术中,有 7 种都使用了梯度模糊,而论文作者们提出的新攻击方法可以完全绕过 7 种中的 6 种防御,并部分绕过最后 1 种。
领域内学者评价
未来可能的相关研究
我们需要考虑在细致、全面的评价方式下构建新的防御技术,目标是不仅能够防御现有的攻击方式,还要能够防御以后有可能开发出的新的防御方式。
「深度上下文依赖的单词表征」
论文地址
https://arxiv.org/abs/1802.05365
内容概要
来自艾伦人工智能研究院(Allen Institute for Artificial Intelligence)的作者们介绍了一种新型的深度上下文依赖单词表征: Embeddings from Language Models (ELMo)。在使用了 ELMo 强化的模型中,每个单词的向量化都是基于它所在的整篇文本而进行的。把 ELMo 添加到现有的 NLP 系统中可以带来的效果有:1,错误率相对下降 6% 到 20%;2,训练模型所需的 epoch 数目显著降低;3,训练模型达到基准模型表现时所需的训练数据量显著减小
论文思想要点
领域内学者评价
未来可能的相关研究
「一般卷积网络和循环网络用语序列建模的实证评价研究」
论文地址
https://arxiv.org/abs/1803.01271
内容概要
领域内有种常见的假设:对于序列建模问题来说,选择一个循环网络架构作为出发点是默认的做法。这篇论文的作者们就对这种假设提出了质疑。他们的结果表明,一般的时序卷积网络(TCN)能在许多种不同的序列建模任务中稳定地超出 LSTM 以及 GRU 之类的典型的循环神经网络。
论文思想要点
领域内学者评价
特斯拉 AI 总监 Andrej Karpathy 评论:「在用 RNN 之前一定要先试试 CNN。CNN 的表现会好到你惊讶的。」
未来可能的相关研究
为了在不同的序列建模任务上进一步提高 TCN 的表现,我们还需要更多的架构探索、算法探索方面的合作。
「公平的机器学习的影响是有延迟的」
论文地址
https://arxiv.org/abs/1803.04383
内容概要
这篇论文的目标是想要确保,当使用一个机器学习算法生成分数来决定不同的人是否能够得到某些机会(比如贷款、奖学金、工作等)时,人口统计学角度分出的不同族群可以被公平地对待。UC 伯克利人工智能实验室(BAIR)的研究人员们表明,使用常见的公平性条件实际上有可能伤害到弱势群体,这是由于某些后果的出现是有延迟的。通过这项研究他们希望鼓励大家在设计公平的机器学习系统时考虑它的长期后果。
论文思想要点
领域内学者评价
未来可能的相关研究
「世界模型」

论文地址
https://arxiv.org/abs/1803.10122
内容概要
David Ha 和 Jurgen Schmidhuber 开发了一个世界模型,它可以用无监督的方式快速训练,学到所处环境的空间和时间表示。这个智能体可以成功地在赛车地图中导航,并且在 VizDoom 环境中躲开怪物发射的火球。而这些任务对于此前的方法来说都难以解决。
论文思想要点
论文所提的解决方案包含三个独立的部分:
领域内学者评价
这篇论文在 AI 研究者间得到了广泛的讨论,它是一项设计优美的使用神经网络做强化学习的研究,而且让智能体在自己「幻想」出的世界中进行训练。
未来可能的相关研究
AI 科技评论详解文章
「任务学:任务迁移学习的解耦」
论文地址
https://arxiv.org/abs/1804.08328
内容概要
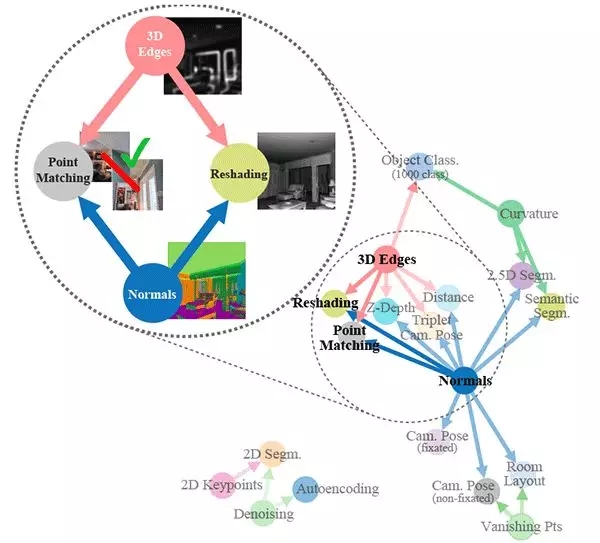
自从现代计算机科学发展的早期以来,就有许多研究者们提出不同的视觉任务之间具有某种结构。现在,Amir Zamir 和他的团队终于做出了寻找这种结构的尝试。他们使用一个完全计算性的方式进行建模,发现了不同视觉任务之间的许多有用的联系(甚至包括一些非平凡的视觉任务)。他们也表明了可以利用这些相互依赖关系进行迁移学习,只需要大约 1/3 的标注数据就可以达到相同的模型表现。
论文思想要点
领域内学者评价
未来可能的相关研究
AI 科技评论详解文章
CVPR18最佳论文演讲:研究任务之间的联系才是做迁移学习的正确姿势
「知道你不知道什么:SQuAD 中无法回答的问题」
论文地址
https://arxiv.org/abs/1806.03822
内容概要
斯坦福大学的一组研究人员们拓展了著名的斯坦福问答数据集 SQuAD,在其中增加了超过 5 万个无法回答的问题。这些问题的答案是无法从给出的文本段落中找到的,无法给出回答,但这些问题又和那些可以回答的问题看起来非常相似。更进一步的是,给出的文本段落中会含有仿佛相符但实际上并不正确的答案,这进一步提高了数据集的难度。升级后得到的 SQuAD 2.0 也就成为了现有顶尖模型的重大挑战:一个在原版的 SQuAD 上可以得到 86% 准确率的强有力的神经网络模型,如今在 SQuAD 2.0 上只能得到 66% 的准确率。
论文思想要点
领域内学者评价
未来可能的相关研究
未来可以继续开发出新种类的模型,它们要能够「知道自己不知道什么」,从而对自然语言有更好的理解。
「用于高保真度自然图像生成的大规模 GAN 的训练」

论文地址
https://arxiv.org/abs/1809.11096
内容概要
DeepMind 的一个研究团队认为目前的深度学习技术就已经足以从现有的 ImageNet、JFT-300M 之类的图形数据集生成高分辨率的、多样化的图像。具体来说,他们展示了生成式对抗性网络(GANs)如果以非常大的规模训练的话,可以生成看起来非常真实的图像。这个「非常大的规模」有多大呢?相比于以往的实验,他们的模型的参数数量是 2 到 4 倍,训练所用的批量大小也达到了 8 倍。这种大规模的 GANs,他们称为 BigGANs,已经称为了分类别图像生成的最新顶级模型。
论文思想要点
领域内学者评价
未来可能的相关研究
「BERT:用于语言理解的深度双向 Transformer 模型的预训练」
论文地址
https://arxiv.org/abs/1810.04805
内容概要
谷歌 AI 团队展示了一个新的用于自然语言处理的前沿模型:BERT(Bidirectional Encoder Representations from Transformers,用于 Transformer 模型的双向编码器表征)。它的设计可以让模型同时从左以及从右处理文本内容。虽然概念上说起来很简单,但 BERT 带来了惊人的实际表现,它刷新了 11 项不同的自然语言处理任务的最好成绩,包括问答、命名实体识别以及其他一些和通用语言理解相关的任务。
论文思想要点
领域内学者评价
未来可能的相关研究

 友情链接
友情链接