








公众号/将门创投
From:Google 编译:T.R Ace

人脸检测是应用最为广泛的计算机视觉任务之一,特别是在移动端上发挥着不可替代的重要作用,包括美颜、人脸跟踪、VR、人脸特效、人脸识别等任务以及刷脸支付、直播、试妆等应用上都有着广泛的引用,几乎涵盖了人工智能落地的方方面面。作为很多后续工作的第一步,人脸检测器需要达到非常高效的性能,尽可能高速准确地完成检测任务。
为了不断提升用户的流程体验、促进人脸相关应用的进一步发展、拓宽支持人脸检测的设备范围,来自谷歌的研究人员通过改造mobileNet提出更为紧凑的轻量级特征提取方法、结合适用于移动端GPU高效运行的新型锚框机制,以及代替非极大值抑制的加权方法保证检测结果的稳定性,在移动端上实现了超高速的高性能人脸检测BlazeFace,最快不到一毫秒的检测速度为众多人脸相关的应用提供了更广阔的发展空间。
BlazeFace
强大的模型一定有强大的细节在支撑。
BlazeFace模型一共从四个方面进行了有效改进,从而大幅减小了计算量并提高了检测精度与稳定性。它提升了mobilenet中深度可分离卷积的计算效率和感受野,基于此构建了有效的特征抽取器、改进锚框机制后处理过程。
更大的感受野更快的计算。mobilenet中的深度可分离架构包含了每个通道上的3*3卷积和逐点进行的在深度方向上的1*1的卷积操作。

深度可分离卷积
研究人员发现,其中大部分计算量都发生在最后逐点计算1*1的过程中。例如针对一个s*s*c的张量,如果使用k*k卷积核为大小的深度可分离操作,那么第一步操作的计算量是s^2*c*k^2,第二步针对d个通道的输出进行逐点1*1卷积的计算量则是s^2*c*d,第二步相对于第一步的计算量消耗是d/k^2倍。在mobilenet论文中也提高1*1卷积对于计算资源的占比较高。
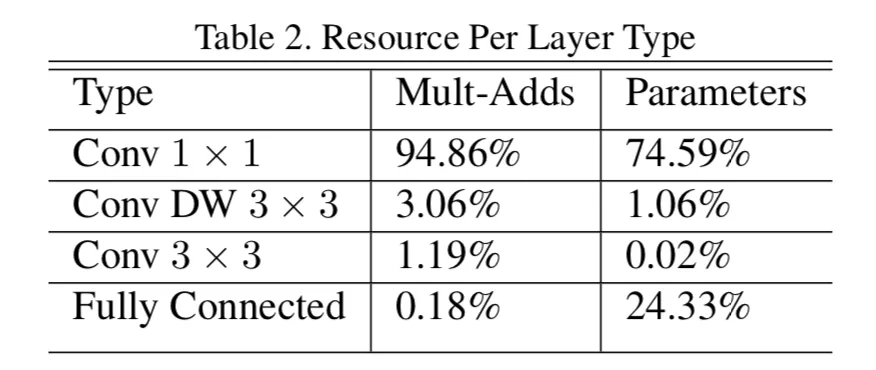
让我们再来直观的感受一下这两种操作计算量的大小。针对实际的iPhoneX手机,其中基于Metal Performance Shader实现的3*3卷积,针对56*56*128大小的16比特浮点张量操作需要0.07ms,而使用1*1卷积对128通道到128通道的操作则需要耗时0.3ms,几乎是前者的四倍多。
这样的结果为研究人员指明了提高效率的方向,增加深度可分离卷积操作中第一步核的大小是相对高效的选择。所以在BlazeFace中研究人员将卷积核的大小扩大成了5*5。卷积核的增大在bottleneck总量减小的情况下保证了模型感受野的大小。

此外,MobileNetV2的bottleneck通过非线性将深度增加的扩张和深度缩减的投影分开。
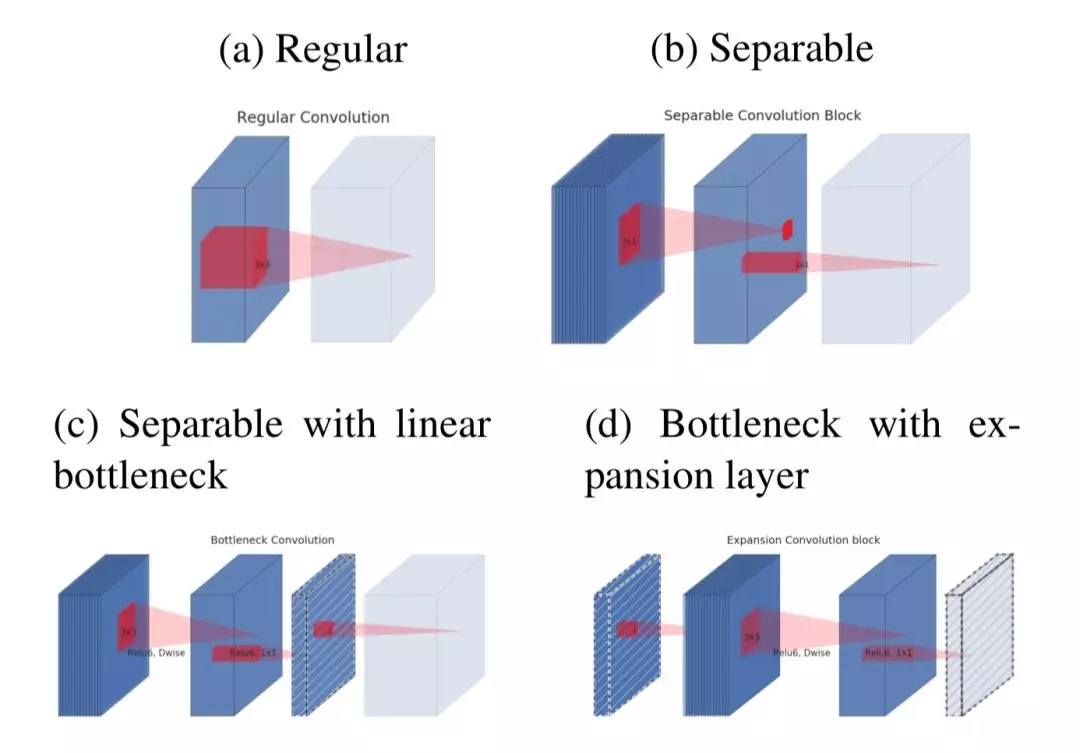
mobileNet中的深度可分离卷积单元
为了适应Blaze单元中更少的通道数,研究人员对这一阶段进行扫描使得残差可以实现类似拓展通道分辨率的操作。
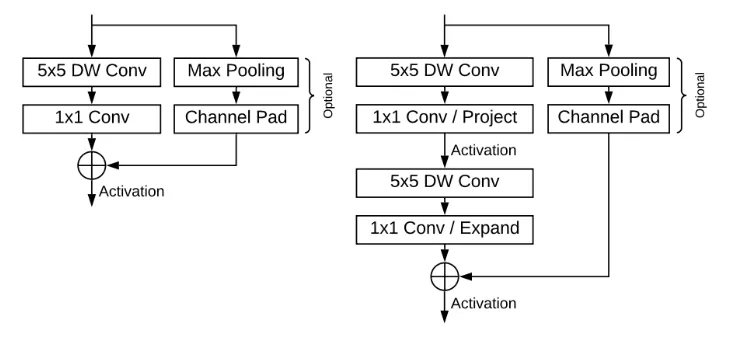
BlazeBlock的单元构造,包括增大的卷积核与残差连接。
左图是基本的blaze单元,右图是双blaze单元
由于增大了卷积核后的Blaze单元的开销很小,使得另一个层的加入成为可能。于是研究人员又在上面模块的基础上开发出了双份的Blaze单元。不仅增加了感受野的大小,同时也提高了特征的抽象。
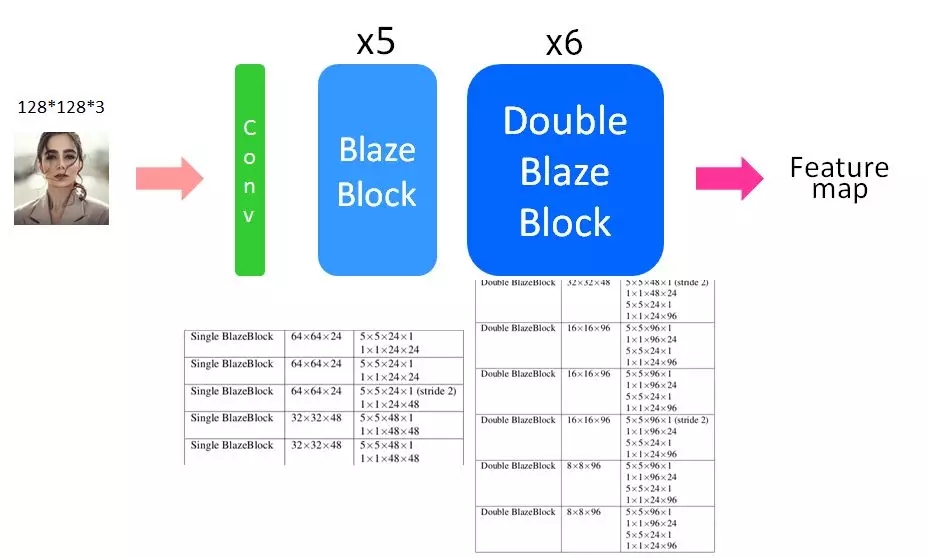
特征抽取器。虽然这一模型同时适合与后摄和前摄,研究人员在文章中针对前视摄像头作为例子来构建特征抽取器,前视摄像头需要搜索的范围更小,计算需求也更少。
模型的输入是针对128*128大小的rgb图像展开的,在一个卷积后叠加了5个单Blaze单元和6个双Blaze单元,可以看到通道数最多的时候达到了96,而最低的空间分辨率则不低于8*8的大小。
可以发现这一模型的最大通道数大大小于其他模型,而最低空间分辨率也较高。下面是模型的构造细节:
锚框机制。锚框在目标检测中广泛使用,通常为了适应多尺度的目标,预定义的锚框都包含了多个不同的分辨率。同时大幅度的将采样也为目标检测中的计算量带来了较多的优化。虽然SSD中使用了多个不同尺度的特征度来进行预测,单池化金字塔架构中却表明过多尺度的特征图可能在某个分辨率后变得冗余。
同时GPU计算相比于CPU存在一个需要注意的关键问题,针对特定层的计算GPU存在固定的调度开销,在对低分辨率层进行计算时会尤其明显。例如测试中的MobileNetV1耗时4.9ms,其中只有3.9ms真正在进行计算。

综上考虑,研究人员对于锚框的设计作出了以下几个方面的改进:
后处理。由于在8*8的特征图上存在多个锚框,很有可能产生多个重叠的结果。为了处理多个不同的框,先前的方法利用执行度的非极大值抑制来选择可能性最高的框作为结果,但这会带来人脸检测结果的抖动,造成人类感知上的不适。
为了缓解这种抖动,研究人员使用融合策略代替了非极大值抑制,通过加权平均多个重叠结果的方式来估计最后回归的bbox参数。这不会增加额外的计算量,在减小抖动的同时还提升了10%的精度。实验表明这一机制使得前视摄像头的人脸检测抖动降低了40%,后摄则降低了30%。
优异性能
实验中研究人员利用66K图像进行了训练,2K多样性图像进行了测试。下图显示了数据在地理位置上的多样性:

针对前视摄像头模型,只有超过20%的区域被人脸(faces)占据才考虑(后摄5%,为了与实际情况相符)。下图显示了与MobileNetv2-SSD对比下的前视摄像头性能,研究人员利用tensorflowLite在16bit下实现了模型,在iPhoneXS上仅需0.6ms,这意味着达到了1600fps+的速度。

研究人员还测试了在不同型号手机上的实现结果,速度都在约170fs到1600ps之间。

最后研究人员还比较了回归参数的预测质量,由于模型体量较小带来了一定程度的退化,但不影响AR或者人脸跟踪中的使用。

应用展示
高速准确的人脸检测网络将为后续的人脸相关任务提供有效地预处理,包括关键点检测、轮廓、表面几何估计、微表情识别和人脸解译等任务。
通过与BlazeFaze给出的人脸关键点结合,算法可以得到跟随人脸旋转的bbox,得到居中的、尺度归一化的、相对框无较大角度误差的人脸结果,这将大幅度降低后续对于图像的旋转和平移处理,节约了计算的开销。

例如在人脸轮廓检测中,首先利用BlazeFace模型预测出人脸框和对应的关键点,随后利用更为复杂的模型对人脸轮廓进行进一步优化估计。这些检测结果可以用于后续帧的处理中。
研究人员展示了基于这一人脸检测模型的一系列例子,包括人脸几何重建、分割、美妆等等。
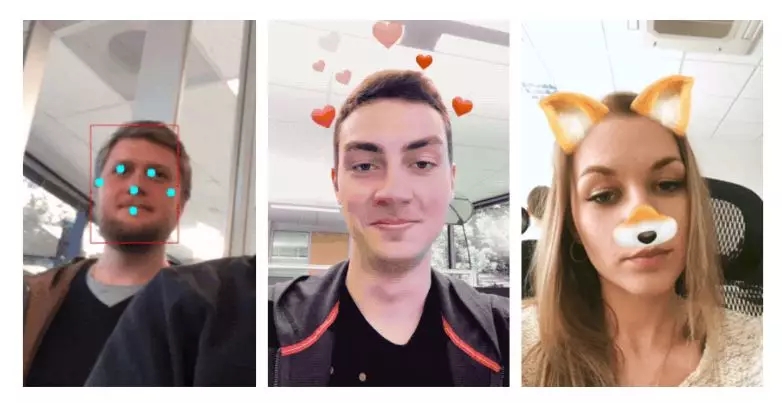
值得一提的是,研究人员还将这一方法集成到了多模态媒体机器学习工具mediapipe中,这一工具包含了多种图像处理模块和方法、可以基于图机制来构建多模态的机器学习应用工具链,并实现跨平台的运行。
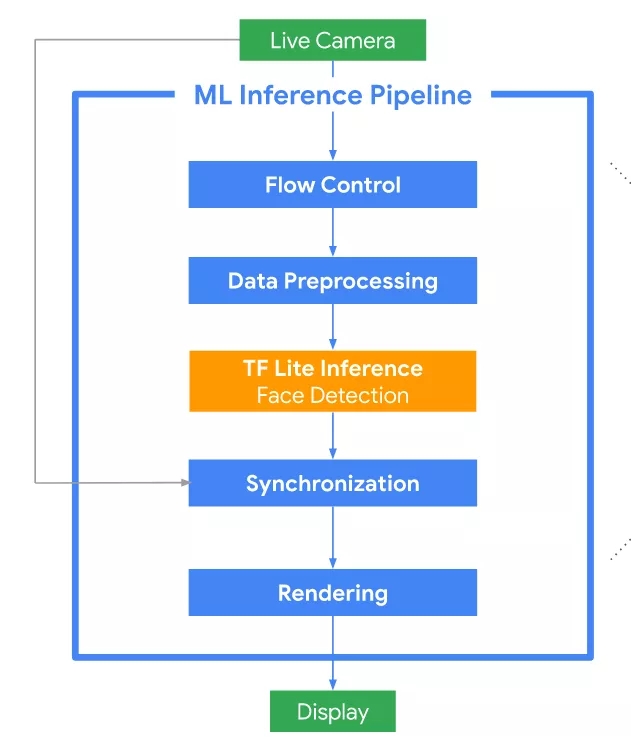
最后附上一份Blazeface的海报,再次感受下这一算法众多的创新:

ref:
https://arxiv.org/pdf/1704.04861.pdf
https://arxiv.org/pdf/1801.04381.pdf
https://arxiv.org/pdf/1905.02244.pdf
https://arxiv.org/pdf/1907.05047.pdf
MediaPipePaper:https://arxiv.org/pdf/1906.08172.pdf
project:https://sites.google.com/view/perception-cv4arvr/blazeface
code:https://github.com/tkat0/PyTorch_BlazeFace
MediaPipeline:https://github.com/google/mediapipe
https://sites.google.com/view/perception-cv4arvr/mediapipe
++http://mixedreality.cs.cornell.edu/workshop/program
++https://sites.google.com/view/perception-cv4arvr/home
shader:
http://m.elecfans.com/article/678537.html
https://www.jianshu.com/p/4a685873c088
https://blog.csdn.net/yufei494215506/article/details/78855933
https://www.machine-learning.news/list/general
https://tkat0.github.io/posts/
picture from:
https://www.pexels.com/photo/selective-focus-portrait-photo-of-woman-in-beige-coat-posing-2584297/
https://dribbble.com/shots/6663874-Equality-2-2
https://dribbble.com/shots/4397995-smiling-faces
https://dribbble.com/shots/4896518-Heads-or-tails-Heads

 友情链接
友情链接