




最近,研究人员能够从少量血液样本中测量数千种血浆蛋白,这为广泛的数据提供了新的维度,可以增进我们对人类健康的了解。
该研究以《Machine Learning based Reconstruction for the MUonE Experiment》为题,于 2024 年 3 月 10 日发布在《Computer Science》上。

传统的材料研发模式主要依赖「试错」的实验方法或偶然性的发现,其研发过程一般长达 10-20 年。
该研究以「Explainable machine learning for profiling the immunological synapse and functional characterization of therapeutic antibodies」为题,于 2023 年 11 月 30 日发布在《Nature Communications》。

该研究以「DeepDelta: predicting ADMET improvements of molecular derivatives with deep learning」为题,于 2023 年 10 月 27 日发布在《Journal of Cheminformatics》。

公众号/ ScienceAI(ID:Philosophyai) 编辑 | 萝卜皮 机器学习方法,特别是在大型数 […]

设计新型催化剂是解决许多能源和环境挑战的关键。尽管包括机器学习 (ML) 在内的数据科学方法有望加速催化剂的开发,通过机器学习方法很少发现真正新颖的催化剂,因为它最大的局限性是假设无法推断和识别特殊材料。





德国柏林马克斯·普朗克学会弗里茨·哈伯研究所(Fritz-Haber-Institut der Max-Planck-Gesellschaft)和柏林洪堡大学(Humblodt Universität zu Berlin)的研究团队提出了一个通用的数据驱动框架,该框架提供定量预测以及定性规则,用于通过符号回归和敏感性分析的组合指导所有数据集的数据创建。
该研究以「Deploying synthetic coevolution and machine learning to engineer protein-protein interactions」为题,于 2023 年 7 月 28 日发布在《Science》。
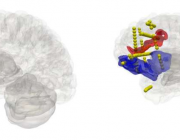
作为 HBP 的一部分,法国艾克斯-马赛大学(Aix-Marseille Université,AMU)的研究人员开发了整合患者测量数据的计算大脑建模技术。






数据对于深度学习来说至关重要,而数据增强策略对于提升训练样本数据量、改善模型稳定性和鲁棒性,提高对于真实世界的适应性和泛化性具有重要的作用。

高丽大学的研究人员认为从厨师本身出发来制定食谱是一件很主观的事情,各国之间、各大厨之间的习惯偏好都不尽相同,那能不能从海量的数据中得出普适性的规律呢?
微信公众号/新智元 来源:Science 编辑:大明、小芹、张乾 【新智元导读】Science在线发表最新论文 […]


政府工作报告要写、想写的内容很多,能最终挤进这不到两万字报告中的内容,可谓“一字千金”。












 友情链接
友情链接