









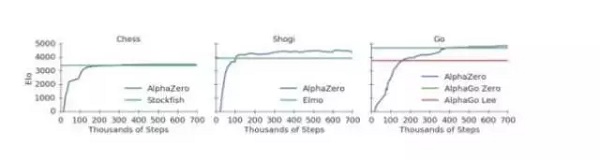
此外,我们看到这次的AlphaZero与AlphaGo Zero有几点不同,首先AlphaGo Zero是在假设结果为赢/输二元的情况下,对获胜概率进行估计和优化。而AlphaZero会将平局或其他潜在结果纳入考虑,对结果进行估计和优化。其次,AlphaGo和AlphaGo Zero会转变棋盘位置进行数据增强,而AlphaZero不会。第三,AlphaZero只维护单一的一个神经网络,这个神经网络不断更新,而不是等待迭代,四,AlphaZero中,所有对弈都重复使用相同的超参数,因此无需进行针对特定某种游戏的调整。
论文地址:https://arxiv.org/pdf/1712.01815.pdf

 友情链接
友情链接