








公众号/将门创投
来源:Hackernoon
编译:T.R
人脸识别
目前最先进的人脸识别系统可以达到99%的准确率。作为使用最为广泛的机器学习算法,人脸识别得到了飞速的发展,但在这背后需要我们对几件事情保持清醒。首先,99%的正确率是来自与验证数据集的测试结果,而验证数据集则来自于与训练数据集相同的数据集,并从中随机抽取。这就意味着数据的均值和方差与训练数据十分相似。但当我们将系统置于真实情况下时,实际照片的特性与训练数据不可能相同,那么实际的精度很有可能低于99%。
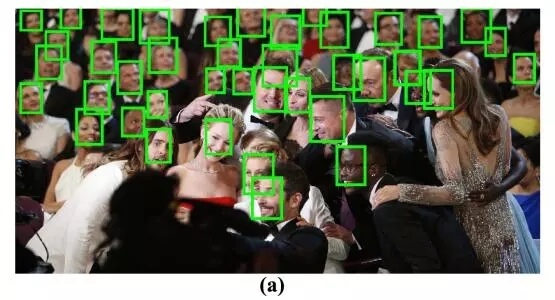
模型有时候会将其他的东西识别成人脸(假阳性)或者忘却漏掉了人脸(假阴性)。不同的模型在不同的阶段有着不同的表现,在使用时你需要确定你需要什么样层次的模型,给出多高的精度是可以接受的。在选择权衡算法时,一个模型在检测几千张脸时错检几十张,而另一个模型可以将准确率提高一半但需要10x的处理时间和运算,那么前者将会是不错的选择。剩下的可以交给人类来做,我们对于少量假阳性和假阴性的样本有着非常快的准确识别能力。
下面是几个关于模型训练的数据清理经验。最好的当然是保证每一张脸都可以很容易地看到,没有模糊遮挡,也没有很奇怪的角度。同时图像要保持适度的分辨率,分辨率太高的图像容易引入造成算法失效的噪音。
光学字符识别(OCR)
目前最先进的光学字符识别系统对于文件的识别与排版已经有十分优异。基于边缘检测、计算机视觉与字符识别的技术使得OCR不断改进,对于扫描文档几乎没有障碍了。

但目前OCR还不能够胜任的是非扫描文件的识别,这也是验证码还能作为网站人类识别的功能存在。人类对于字母识别有着无与伦比的能力,无论是模糊、扭曲、颜色不同都不在话下,而计算机望尘莫及。
OCR很有用但对于一些场景下使用不当就会文不对题,下面这张球赛的截频就是一个典型的例子。

上图如果用OCR识别很有可能生成这样的一大串:
[0] PREMIER LEAGUE [1] TOT 2 [2] M [3] U [4] 0 [5] 36:2 [6] 4 [7] SPORTS [8] NEW 0 BUR 0 [9] HALFTIME [10] LIVE [11] NBCSN
如果没有上下文语境我们很难明白识别出的意思,哪里是队名哪里是logo?这会造成很大的混乱。
我们不应该像使用通用OCR一样来直接简单粗暴的套用,而是需要针对情况进行分析。对于上面的例子如果我们想要追踪球员,那么目标追踪的方法会很好,但如果想要追踪比赛分数和时间,那么将OCR限定在固定区域中会是不错的选择。
视 频
视频是一种很神奇的存在,虽然很多机器学习模型能在视频上实现和照片一样的效果,但总会有意想不到的情况。数字世界的解码和封装总是与视频的压缩率和长宽比耦合在一起。
同时考虑到处理时间和算力的限制,对视频进行处理时我们往往选择低分辨的格式。当你选择低分辨率或者较高的压缩时,视频并不会是一组连续的静态图片,所以计算机视觉的识别方法将会与静态图片中的识别方法有很大的差别。
为了说明这一情况我们可以随便点开一个视频并暂停,如下图所示。人们的脸变得模糊、角度和整体形象都显得和静态下十分不同。

下面应该是计算机看到的人脸区域:

你能从中认出图中的主角是谁吗?如果对你来说很困难那么对于计算机来说也不容易!
对于人类来说,在视频中识别人脸很容易,但要把独立的帧抽取出来你会发现图像质量出乎意料的差。
但我们也不能否定机器学习,因为机器学习在大多数情况下对于视频的自动化分类和标注时十分重要的手段。我们需要明白的是我们期望得到的结果以及如何去修正模型实际的表现。如果一个庞大的全球名人识别模型对一段视屏进行检测可能会出现很多假阳性的结果,但是如果使用一个仅仅包含几个著名人士的模型来检测则会得到好得多的结果。如果你的模型表现不好,你还可以从数据的角度来改进,譬如说某个节目中人脸出现的位置就可以作为先验知识来帮助机器提高正确率。我们需要尝试不同的模型和工作流总能取得成功。
如何成功的应用机器学习?
机器学习十分强大,有人将它应用于检测学术造假的论文,也有人将它应用于人脸身份认证、不良内容的裸露检测等。同样也用于为用户推荐商品和服务的推荐引擎上,在这样的场景下假阳性和假阴性的推荐结果不会造成太大影响,事实上一些异常推荐还为用户探索新事物提供了条件。
还有改善搜索引擎的个性化能力,检测农作物动物的疾病以及预测产量等等方面。机器学习将会有无数的应用,我们对它充满期待,但同时也会把握住期待的方向让机器学习正常运转。

 友情链接
友情链接