








公众号/将门创投
来源:TowardsDataScience
编译:T.R
学习=表示+评价+优化
对于一个具体的机器学习问题,面对眼花缭乱的算法到底该选择哪一个呢?我们首先需要明白机器学习的三要素:
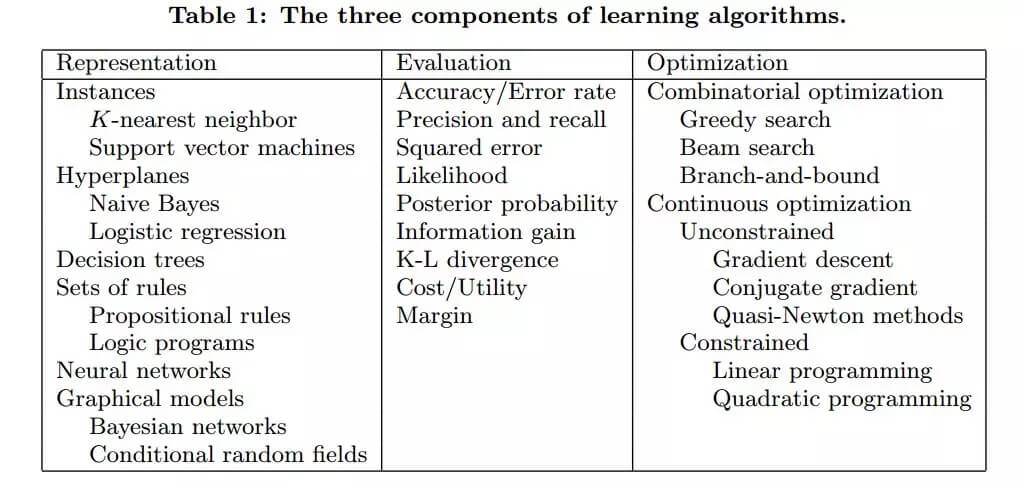
下表是三种要素一些常见的分类:
泛化性
机器学习的根本目标是在训练数据外的样本上实现较好表现的泛化性。因为无论训练数据有多少,我们总是无法保证它们覆盖了所有的情况。大多数初学者很容易犯的错误就是在训练数据上获得了好的结果就沉浸在成功的喜悦中。所以需要记住机器学习模型的好坏是看它在新数据上的表现的。如果你请别人做分类器,那么你一定要保留一些数据作为测试、如果你为别人做分类器也需要在最开始保留一部分数据来测试分类器的有效性。
虽然保留测试数据集减少了训练数据的大小,但我们可以通过交叉验证来克服这一问题。通过将数据分为数分,并将其中每一份轮流作为测试集以调节算法的表现。
泛化性作为机器学习的目标时,我们一般会使用训练误差来作为指导而不是去操作被优化的函数本身。同时局部优化算可能比全局优化算法表现好。

仅仅有数据是不够的
把泛化性作为机器学习的指标带来了一个严重的问题:数据永远是不够的!在没有额外信息的情况下我们无法获取一个比随机更好的模型。但幸运的是目前大多数假设已经足够帮助模型做的足够好,这也是目前机器学习如此成功的原因。就像演绎和规划法是知识的杠杆一样,可以将一小部分的输入知识转换大量的输出。但它们却不能不输入任何东西就生成出知识来。机器学习不是魔法,它不能从无到有的生成知识,只能从少到多。学习和种植作物很像,我们需要做的是将种子和养料施下,剩下的就交给大自然了。学习则是通过数据和知识的结合生成可以处理实际问题的程序了。
过拟合有不同的面貌
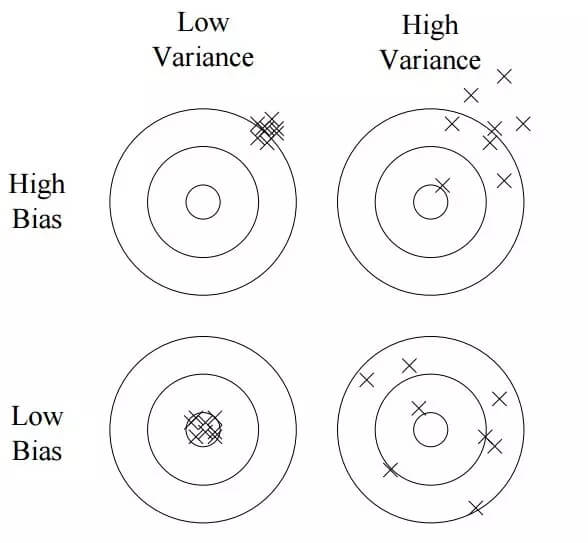
如果模型过于复杂而训练数据又不充分的情况下我们就有陷入过拟合的危险。我们都和熟悉过拟合但对于它的来源却不甚了解。通常情况下我们将它分解为偏差和方差两个部分来理解,其中偏差是模型产生错误结果的一种趋势,而方差则是产生结果的随机性。通常情况下线性分类器的偏差会很高,而决策树偏差很小但方差却很大。同样对于不同的优化方法来说,集束搜索的偏差比贪婪搜索要低但方差很高,因为它尝试了更多的假设。最后需要注意的是,过拟合不是由噪声引起的,及时全部正确的训练样本也会出现过拟合问题。
上文提到的交叉验证是对抗过拟合的好方法,但对于参数很多的模型来说正则化则更有效。通过引入对复杂项的惩罚来保持模型的简练,使得模型不容易产生过拟合。
直觉在高维空间中失效
在二维或者三维空间中构建一个分类器对于人类来说很容易,我们可以在视觉上审视其边界。但我们对于高维空间缺乏足够的经验,使得我们难以理解其中的奥妙,这阻碍了我们设计出更好的分类器。有些时候更多的特征维度可能会带来更糟的结果。
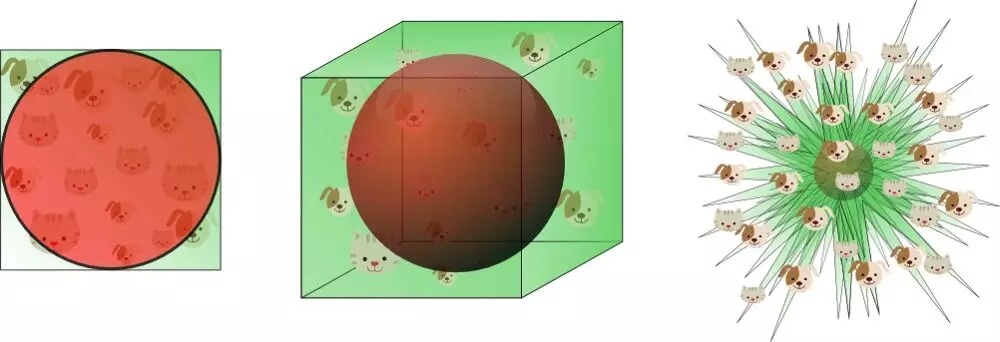
高维空间的分布不像低维空间这么均匀,主要集中在壳层表面和周围。但幸运的是大多数的样本集中在近低维的流型上,这使得我们可以在有效的低维度上建模。或者利用维度减约技术来缩减维度,帮助学习。
论文中的理论并不像看起来的那样
论文中的很多结论都有他们存在的假设、边界、条件。他们主要的作用是作为理解和推动算法设计的资源,而不是我们在算法实践中的决策标准。他们可以有力的推动算法的设计。正因为数据和理论的深度交融才使机器学习领域迅速发展。但机器学习领域的论文是一种开发交融的交流,前人的工作并不意味着要约束后来者的工作,而是帮助后来者走得更好的动力和源泉。
关键的特征工程
每天都会有很多机器学习算法成功也会有很多算法谢幕,其中决定成败的原因是他们使用的特征各不相同。如果一个算法可以使用一些相互独立并与分类相关的特征它就很容易实现,但当分类十分复杂特征不明显时,这就面临很大的困难。很多情况下原始数据并不能提供最好的特征表示。所以这是机器学习中我们需要最为重视也是很多技巧所在的地方。
很多新人会惊讶于在问题中真正用于学习的时间很少,而很多时间却用于繁杂的数据收集、整合以及清洗,并进行预处理和特征设计。同样机器学习不是一个一蹴而就的过程,而是一个循序渐进迭代的过程。特征工程虽然涉及领域知识,但却是学习工程中的中重要内容。
虽然机器学习的圣杯是自动抽取特征的一系列算法,但实际工作中真正有效的算法还是来源于特征的迭代和结合。要重视特征工程带来的作用。

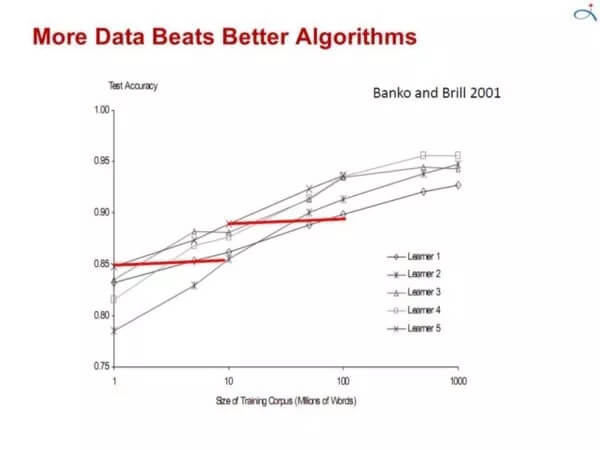
更多的数据胜过更好的算法
但我们得到一个模型后,需要进一步改进这个模型我们有两种可行的办法,其一是建立更好的算法那,其二是收集更多的数据来训练已有的算法。虽然很多机器学习研究者偏爱新算法,但收集更多数据才是提高模型表现更为快速的方法。毕竟机器学习的本质就是从数据中学习知识嘛。
随着数据的增加引入了规模性的问题。在机器学习中,除了时间和内存、另一个重要的资源就是训练数据。但数据的增加也带来了矛盾,越多的数据虽然模型越复杂,但会耗费越多的时间来计算。在实际情况中,很多情况下人们都从最简单的算法开始逐步尝试。算法一般分为两种类型一种是具有固定参数的类型,像线性分类器随着数据增加它具有一个上限。另一种是可变化的模型,可以随着数据规模的增加改变模型的大小(也称为非参数模型),他们可以充分利用数据。但由于算法同样存在限制,实际中性能也具有上限。
在机器学习中最大的瓶颈不是算力也不是数据,而是人类的介入。我们需要比较算法调整模型,也需要将算法数据的结果变成人类可以理解的方式来分析。人类介入产生的价值和努力很难定量计算,但却十分重要。研发出先进的算法需要机器学习专家和领域专家的通力合作。
多个模型优于单个模型
早先机器学习的研究者们,每个人都基于先验知识有各自钟爱的学习模型。而后随着时代的发展,人们开始尝试多种模型并从中选取最优的作为解决方法。但后来人们发现,与其选出最优的方案,不如直接将多个模型的结果综合到一起来的好。目前通常的做法是从训练集中随机选出一系列数据并单独训练分类器,而后利用权重或者投票的方法将这些分类器综合起来解决问题。
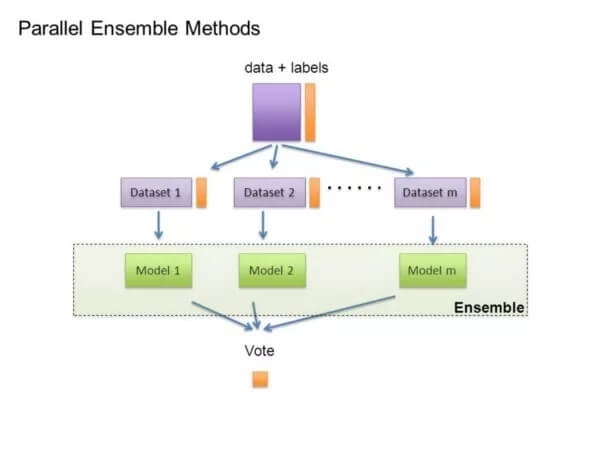
通常来说,利用权重分配训练样本使得新的分类器主要集中于原先分类器错误的样本上,这类方法称为推举法(boosting);而独立分类器的输出作为高层分类器的输入,这样称为堆叠法。
简洁与精度
奥卡姆剃刀在机器学习中意味着精度与复杂度的平衡。如果两个训练误差相同的模型,那们较为简单的模型意味着更低的测试误差。但天下没有免费的午餐,就如前文提到的模型综合一样,我们不能说简单的模型就一定更好,同样参数的个数越多也不一定意味着过拟合。
模型的复杂度意味着假设空间的大小。更小的假设空间意味着我们可以用更小的表示来表达它,理论上将更简洁的表达意味着更好的泛化性。但在实际中权衡精度和复杂度的时候,我们在设计的时候更偏向与简洁的表示,而他们的精确性却是来自于我们倾向于重视精确而来的,而不是来源于假设的简洁。
可表示的特征并不意味着可以学习
理论上和变量数目相同的参数模型乐意表达或者至少无限近似其空间中的任何函数,但我们需要明白的是可以被表达并不意味着可以被学习。例如我们无法得到叶子比训练样本数还多的决策树模型。我们在训练时总是在有限的资源下搜索函数,最后的结果只是模型可以学习空间中的一小部分函数。而这一子集对于不同的表示来说却各部相同。所以学习的关键问题并不是能不能表示,而是能不能学习,并尝试不同的学习模型。数据更为复杂的表示意味着我们有可能用更少的训练数据来实现学习。目前的研究前沿之一就是在为更深更复杂的表示寻找可能的学习方法。

相关性并不意味着因果联系
我们在机器学习中学到的正是不同变量之间的相关性,而学习预测的目标则是利用这些结果去指导行动。但机器学习所能做的只是观察数据,而预测变量并不受机器学习的控制,这属于去试验数据。虽然有的算法可以从观测中抽取潜在因果联系,但应用十分有限;同时相关性只是因果的潜在表现,我们可以用于指导更深入的研究,并理解因果链条。机器学习在实践中的目标是预测行为的效果(变量的结果)而不仅仅是相关性;但如果你能收集到实验数据的话,那就竭尽所能去做吧。
和很多学科一样,机器学习拥有很多至关重要的智慧隐藏在人民群众中,这篇文章给出了很多我们在书本上学不到的技巧和知识。希望能够为我们的实践带来有益的帮助。
如果想看原文:
https://homes.cs.washington.edu/~pedrod/papers/cacm12.pdf
这位教授还提供了贴心的书籍和教程:The Master Algorithm
http://www.cs.washington.edu/homes/pedrod/class

 友情链接
友情链接