








公众号/机器之心
选自arXiv
作者:Shunyu Yao 等
机器之心编译
参与:乾树、刘晓坤
MIT 和清华大学的研究者提出目标几何、外观和姿态的分解表征架构,并将其整合到深度生成模型中,实现了对 2D 图像目标的 3D 操控。这种操作体验犹如使用了 3D 游戏引擎,背向的汽车可以翻过来,离得远的汽车可以拉近并自动放大。会不会在将来,给几张图片我们就能为 3D 赛车游戏建模~
人类感知世界的能力令人难以置信,但更厉害的是人类模拟和想象未来的智力。给出如图 1 所示的街道图像,我们可以毫不费力地检测并识别汽车及其属性,更有趣的是,人类可以想象汽车在 3D 世界中如何移动和旋转。
受这些人类能力的启发,在这项工作中,MIT CSAIL 和清华大学的研究者寻求获得机器的可解释、可表达和可分解的场景表征,并使用学习到的表征来进行灵活的 3D 感知场景操控。
深层生成模型在学习图像的层次表征和将表征解码回图像方面取得了显着的突破。然而,获得的表征通常限于单个孤立的目标,难以解释,并且缺少单一目标背后的复杂 3D 结构。因此,这些深度生成模型不支持图像处理任务,例如图 1 所示的目标移动。
另一方面,图形引擎使用预定义的结构化和分解的输入(即图形编码)来渲染图像。因此,它们可以直接用于场景处理。但是,从图像中恢复图形编码通常很难。
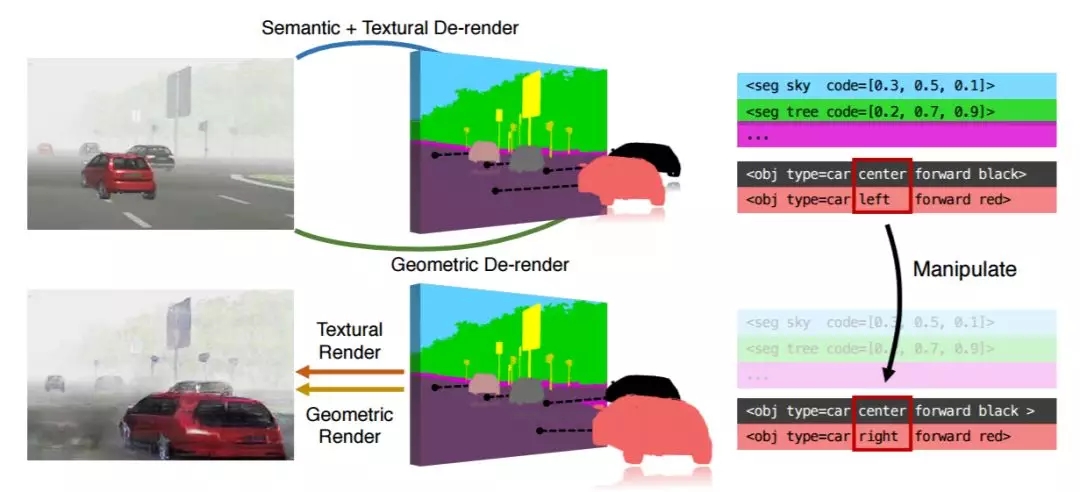
图 1:学习一个对场景语义以及三维信息和目标纹理进行编码的整体场景表征。编码器 – 解码器模型学习用于图像重建和 3D 感知图像处理的分解式表征。例如,可以用新的 3D 姿态估计将汽车移动到不同的位置。
在本文中,研究者提出将基于目标的、可解释的场景表征融入深度生成模型。该模型采用编码器 – 解码器架构,对应三个分支,一个用于目标几何和姿态估计,一个用于背景外观,一个用于目标外观。
几何分支通过学习近似可微的渲染器推断目标形状和姿态。外观分支首先预测输入图像的实例标签图。然后运用纹理自编码器来获得每个目标的纹理表征。
从纹理中分解出 3D 几何和姿态可实现 3D 感知场景操控。例如,为了拉近汽车,我们可以简单地编辑它的位置和姿势,但保持其纹理和语义不变。
研究者给出了定量及定性结果,以证明该框架对两个数据集 Virtual KITTI 和 Cityscapes 的有效性。由于 3D 感知场景操控问题尚未有一致的描述,除了定性结果之外,研究者还在 Virtual KITTI 上创建了一个图像编辑基准,并对比类似的 2D 流水线来评估本文的模型。研究者还通过评估表征准确率和图像重建质量来研究模型设计。
论文:3D-Aware Scene Manipulation via Inverse Graphics

论文地址:https://arxiv.org/pdf/1808.09351v2.pdf
摘要:我们致力于获得一种可解释的、富有表现力的和可分解的、包含每个目标的整体结构和纹理信息的场景表征。以前通过神经网络学习的表征通常是无法解释的,且受限于单个目标或缺乏 3D 知识。在本文的工作中,我们通过将目标几何、外观和姿态的分解表征整合到深度生成模型中来解决上述问题。我们的场景编码器执行可逆图形操作,也就是将场景转换为结构化目标表征。我们的解码器包括两个组件:可微的形状渲染器和神经纹理生成器。几何、外观和姿态的分解支持处理各种 3D 感知场景,例如,在保持形状和纹理一致的同时随意旋转和移动目标,或改变目标外观而不影响其形状。我们系统地评估了该模型,并表明我们的图像编辑方法优于对应的 2D 方法。
实验

图 5:Virtual KITTI 上的图像编辑示例。(a)远处的汽车可以在拉近的同时保持相同的纹理。(b)只需改变其姿态编码,即可将汽车的左侧、前侧和右侧旋转。同样的纹理编码用于不同的姿态。(c)我们在红色汽车上使用其它不同姿态汽车的纹理编码,而不影响其姿态。我们还可以更改背景的纹理编码以改变环境条件。(d)我们展示了遮挡恢复和消除目标的操作。

图 6:Cityscapes 上的图像编辑示例。(a)我们将一辆被遮挡的汽车向右移动,然后将其移近摄像机。请注意,我们的模型可以自动合成遮挡部分。(b)我们将两辆车拉近摄像机。(c)我们小角度旋转左车。
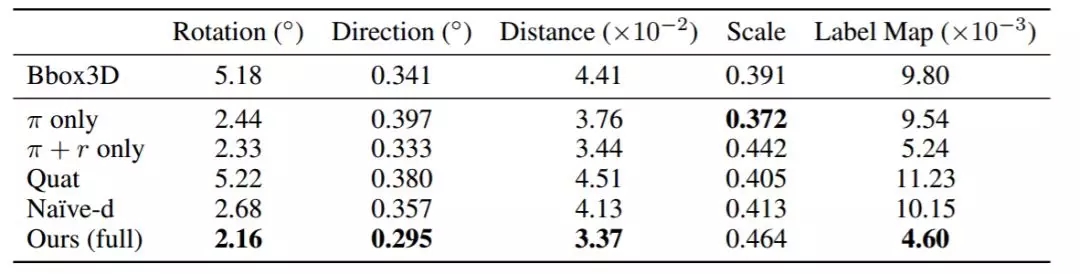
表 2:我们用 ground truth 来比较所有模型在 Virtual KITTI 上的 3D 属性预测的性能,共包含两个变体和三个其它对比项。我们的完整模型在大多数指标上表现最佳。我们的模型取得了更低的误差,例如标签图。

图 7:与 pix2pixHD [Wang et al。,2018] 在 Virtual KITTI 编辑基准上的对比。(a)当 pix2pixHD 失败时,我们成功地恢复了被遮挡的汽车的掩模并将其移近摄像机。(b)我们将汽车从后向前旋转。使用后视图的纹理编码和前视图的新姿态编码,我们的模型计算出应该删除尾灯,而 pix2pixHD 则不能。
方法
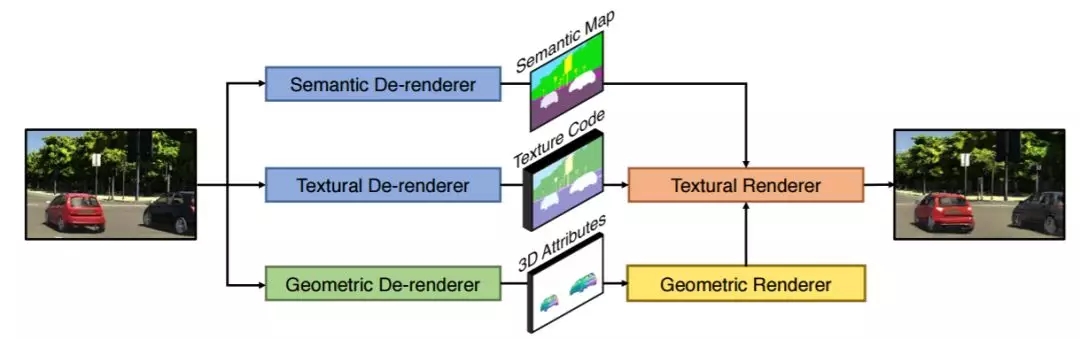
图 2:我们的框架图示。编码器由语义、纹理和几何去渲染器组成,其输出表征会在纹理渲染器中组合以重建输入图像。
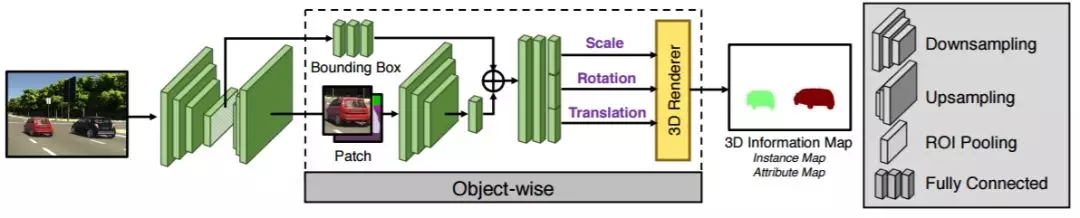
图 3:几何解释模块。该模块接收整个图像,使用目标建议中的合适公式来推断 3D 属性,并且可以为理解和操控生成可解释的表征。
近期在高精度计算机视觉领域的其它研究成果:
MIT 提出精细到头发丝的语义分割技术,打造效果惊艳的特效电影
画个草图生成 2K 高清视频,这份效果惊艳研究值得你跑一跑

 友情链接
友情链接