








公众号/AI前线
作者 | David Mack
译者 | 无明
编辑 | Vincent
AI 前线导读:我们经常会问“什么时候与朋友会面”或“超市什么时候开门”之类的问题。这些问题问的是有关世界中某个对象的属性。这篇文章将介绍如何使用知识图和神经网络来回答这类问题。

这个可以使用数据库来实现,非常简单。为简单起见,我们假设问题是图中的一个节点。在 Neo4j 图数据库中,可以进行简单的查询:

但在本文中,我们将采用神经网络方法。我们可以使用神经网络做一些传统数据库无法做到的事情,当然,我们需要编写更多的代码,并解决一些有趣的挑战。
文中的代码可以从 GitHub(https://github.com/Octavian-ai/gqa-node-properties)上获取。
既然数据库引擎已经可以轻松地获取节点属性,为什么要设计一个更复杂的基于神经网络的解决方案呢?
本文的灵感来自我们构建的 MacGraph,MacGraph 是一个复杂的知识图问答系统,完全基于神经网络。这种方法可以做到传统数据库引擎无法做到的事情:
通过神经网络从图中提取节点属性,整个推理系统可以是单个可微分函数(如一个 TensorFlow 图),而且可以使用梯度下降和监督学习进行训练。
最后,使用神经网络构建这个系统本身是一项有趣的挑战!
在构建机器学习解决方案时,如果没有达到高准确率就很难知道模型是否存在缺陷,或者数据是否包含固有的噪声和模糊性。
为了消除这种不确定性,我们采用了合成数据集。这是我们根据自己的规则生成的数据。得益于数据的显式结构,我们可以确信一个好的模型可以达到 100%的准确率。在比较不同的架构时,这确实很有用。
CLEVR-graph(https://medium.com/octavian-ai/clevr-graph-a-dataset-for-graph-based-reasoning-5e4e64f28ffb)包含了一组关于程序生成的运输网络图的问题和答案。下面是其中一个运输网络的示例以及一些示例问题和答案:
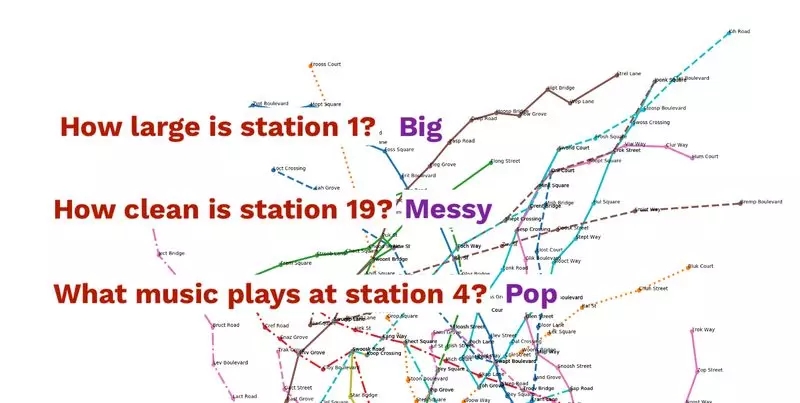
CLEVR-graph 中的每个问题都带有一个答案和一个独特的程序生成图。
图形 – 问题 – 答案三元组被编译成 TFRecords。如果不存在,训练脚本将自动下载数据集的编译版本(https://storage.googleapis.com/octavian-static/download/gqa-node-properties/tfrecords.zip)。
CLEVR-graph 可以生成很多不同类型的问题。在本文中,我们只生成与站点属性相关的那些。总共有十二个(例如,X 有多干净?Y 在播放什么音乐?),并且它们与每个图形中随机选择的站点相结合,以提供问答配对。由于只有十二种不同的问题模板,因此训练数据将缺少一些多样性。这使数据集就更容易处理。我们将语言多样性作为未来的延伸挑战,并希望看到读者的解决方案!
我将简要介绍一下我们所使用的技术,因为可能有些读者不熟悉它们。
简单地说,知识图保存了实体和实体之间关系的信息。我们可以很自然地画出一个家庭成员间的关系:
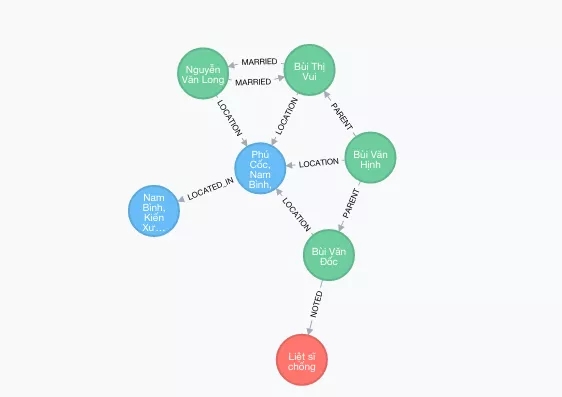
这是一种图结构,其中每个实体可以与其他实体具有任何数量的关系,高度灵活,并且可以用来表示世界中的很多事物(例如运输网络、社交网络、服务器、维基百科)。
谷歌在构建自己的“知识图”时,这个词才开始流行起来,现在存储了超过 700 亿个事实数据。他们用它来帮助回答人们向谷歌搜索引擎和“Ok Google”提出的搜索问题。
知识图的一大好处是它们可以存储很多类型的信息。通过添加更多实体并在现有实体和新实体之间添加关系连接就可以轻松扩展知识图。
对于这个系统的机器学习部分,我们将使用 TensorFlow。TensorFlow 是一个模型构建和训练框架,可用它构建模型并在我们的数据上进行训练。TensorFlow 已迅速成为最受欢迎的机器学习库之一。
TensorFlow 可以节省大量的开发时间。在 TensorFlow 中构建模型后,相同的代码可用于实验、开发和生产部署。现在有很多平台(如 FloydHub、Google CloudML 和 AWS SageMaker)可用于训练和部署 TensorFlow 模型。
这个系统采用 TensorFlow 构建,可在合成数据集挑战中实现 100%的准确率。
以下是该系统概览:
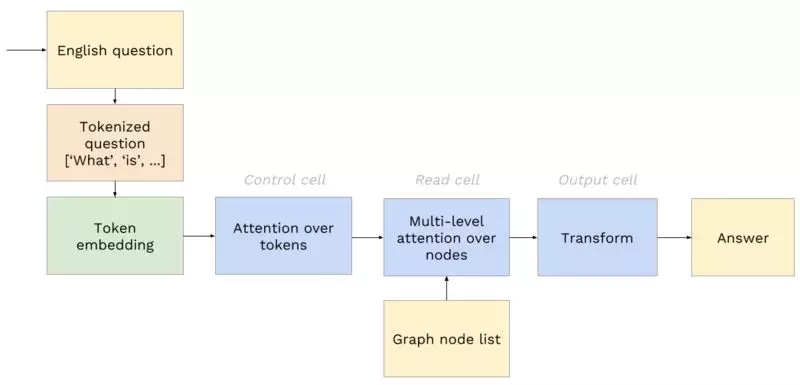
系统首先将输入问题转换为整数标记,然后被作为向量嵌入。
接下来,控制单元对标记向量执行 attention 操作。这将生成用于后续单元的控制信号。
然后,读取单元使用控制信号从图节点列表中提取节点。然后它提取该节点的一个属性。我们稍后将更详细地解释这个单元。
最后,输出单元将读取单元的输出转换为答案标记(例如映射到字典中英文单词的整数)。
我们已经展示了模型的概览,接下来让我们描述每个部分的工作原理。我将解释模型的不同部分,并提供相关链接,毕竟在一篇文章中很难完全解释所有细节和背景。
第一步是将英语问题转换为可供模型使用的信息:
处理这个过程的代码位于 GitHub 存储库中的 build.py 中(https://github.com/Octavian-ai/gqa-node-properties)。
对文本进行标记是必要的,因为我们的序列编码器需要操作一系列值。我们对输入问题、知识图中的数据和答案输出使用了相同的标记方案。这样网络就可以使用输入问题中的单词来查询知识图中的节点。
为了便于引用问题中的站点,站点以 1 到 70 之间的随机整数进行命名。问题中的站点整数被视为标记,并被分配一个整数 ID(通常与站点号不同)。
在被标记化为整数后,这些标记就会被嵌入。这会将每个标记整数映射到该整数对应的特定向量。它使网络能够学习标记的有用表示(例如,经常扮演相同语言角色的标记可能最终会导致相似的嵌入)。
下一步是从问题标记中提取信息,以便帮助读取单元从知识图中读取正确的数据。这将生成控制信号。
我们通过对嵌入问题标记进行 attention 操作来实现。这将输出一个组合了嵌入问题标记向量的信号。
对于我们正在使用的数据集,控制单元倾向于从问题中提取站点名称标记向量。然后用在读取单元中,用来从图中提取站点节点。

控制单元对嵌入问题执行经典的 attention 操作。通过训练变量来生成查询,然后将其与每个问题标记向量组合起来生成点积分数。这些分数再通过 softmax 进行传递。最后,将问题标记向量相加在一起,并通过它们的分数进行加权。
读取单元是网络的核心,它与知识图形进行实际的交互。你可以将读取单元视为我们自己的微型数据库引擎。
读取单元格做了三件事:
首先,让我们解释知识图是如何存储和表示我们的网络的。
对于这个模型,我们只需要图中的节点。
我们将其表示为一个二维表。每行都是一个节点。每列都是不同节点的属性。表格中的每一个值都是表示标记的整数。以下是这种结构的示例,为了可读性,使用了字符串而不是标记整数:

读取单元以层级的方式执行两次 attention 操作。第一个 attention 操作提取节点,第二个 attention 操作提取节点的属性,然后生成读取信号。

节点提取采用了“基于的值 attention”。通常,网络使用控制信号从问题中提取站点名称,然后将其与查询操作中的表的名称列以及提取的相关节点进行比较。
属性提取采用了“基于索引的 attention”。知道这个操作的人并不多,所以我们在这里解释一下。查询输入(控制信号)通过密集层转换为向量,在值列表中每个项目对应一个元素(节点属性列表)。然后对其进行 softmax 操作,并将这些分数用于生成值列表的加权和。
这个操作起到的作用是网络可以指定从节点中提取哪一列,与列中的值无关。这很有用,因为问题本身只包含关于期望值的弱信息,但可用于指导模型需要提取的属性列。
最后一步是将读取信号转换为答案标记,并将其输出。与分类网络的标准一样,输出的是概率分布。由于我们的词汇表中有 128 个不同的标记,因此输出信号是 128 宽的矢量,它被传给用于训练的交叉熵损失函数和用于预测的 argmax。
模型已经使用 Adam 优化器进行训练,学习率为 0.001,梯度削减为 0.4。标记嵌入宽为 64,批次大小为 32。
要自己训练网络,可以从我们的 GitHub 克隆代码,使用 pipenv install 安装依赖项,使用 pipenv shell 进入虚拟环境,然后运行 train.sh。
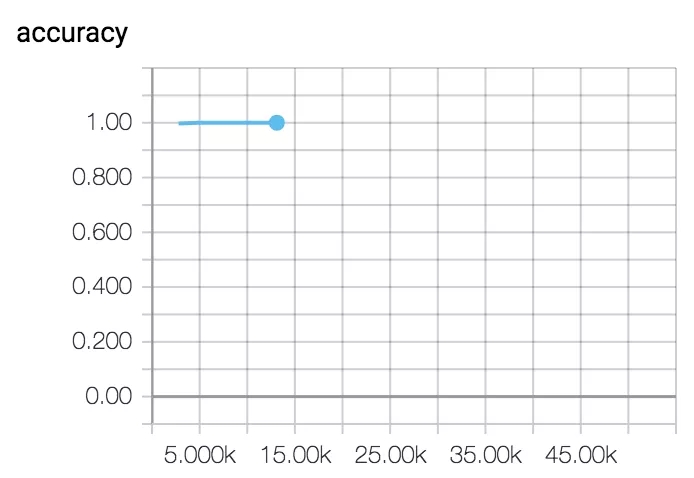
经过 8000 训练步骤之后,网络的准确率达到了 99%以上。这符合我们的预期,因为数据集不包含噪声和模糊性。
通过运行 tensorboard –logdir output/ 可以看到训练进度:
你也可以调用 predict.sh 在预测模式下观察网络的内部工作情况。这个脚本将打印每个预测以及 attention 操作的内容:

我们已经成功地展示了如何在知识图上执行基本查询,并希望能够为你提供一些可以用于解决其他问题的想法。
有很多有趣的方法可用来扩展这个网络:
英文原文:
https://medium.com/octavian-ai/graphs-and-neural-networks-reading-node-properties-2c91625980eb

 友情链接
友情链接