








公众号/AI前线
作者 | Christopher Dossman
译者 | 姚佳灵
编辑 | Vincent
AI 前线导读:我被问到最多的问题是“我如何获得更高的精度?”。机器学习工程师,无论是新手还是有经验的,都会问这个问题。
因为对业务来讲,机器学习最有价值的地方通常是它的预测能力,所以这个问题很有意义。提高预测精度是从现有系统中榨取更多价值的简单方法。
本指南将分成 4 个不同的部分,每个部分都包含一些策略。
– 数据优化(Data Optimization)
– 算法调整(Algorithm tuning)
– 超参数优化(Hyper-Parameter Optimization)
– 合并,合并还是合并(Ensembles, Ensembles, Ensembles)
并非所有这些想法都可以提升性能,越把它们应用到同样的问题上,就越能看到有限的效果。如果尝试了它们中的一些还是没有起色?那就表明,应该重新考虑一下业务问题的核心解决方案了。本文只是一张速查单,因此,在每个部分,我都会给出更详细资源的链接。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
如果是分类问题,那么,提高表现不佳的深度学习模型性能的最简单方法之一是平衡数据集。真实世界的数据集通常是不平衡的,如果希望有最好的精度,那么深度学习系统要学习如何在两个类之间根据特征而不是通过复制它的分布进行选择。
常用方法包括:
这里有篇好文章,它详细介绍了处理这个问题的更多细节:
http://amsantac.co/blog/en/2016/09/20/balanced-image-classification-r.html
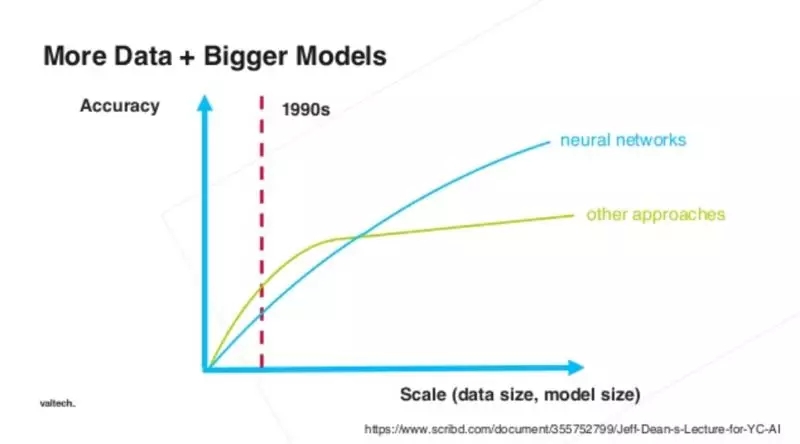
我们中的许多人都熟悉这张图。它显示了深度学习和分类机器学习方法中数据的数量和性能之间的关系。如果你不知道这个,那么试试这个清晰明了的课程。如果想要模型有更好的性能,就需要有更多数据。这取决于可以选择的预算以创建更多标签数据或收集更多没有标签的数据,并更多地训练特征提取子模型。
或者假装一下,直到成功。用于提高精度一个常被忽视的方法是,从已有的数据中创建新数据。以照片为例,工程师常常通过旋转和随机移动现有图像来创建更多图片。这种变换还增加了训练集的减弱过度拟合。
这里有一个创建更多数据的绝佳资源,可以用于图像问题:
https://medium.com/nanonets/how-to-use-deep-learning-when-you-have-limited-data-part-2-data-augmentation-c26971dc8ced
你是否正在研究一个问题,而该问题的背后有很多研究?如果是的,那么你很走运,因为可能有很多工程师已经考虑过如何为该问题获取更好的精度。读读跟这个主题有关的研究论文并注意他们用来解决问题的不同方法!甚至,他们或许已经在 GitHub 上发布了代码,而这些代码让你爱不释手。
谷歌学术搜索(Google Scholar)是开始进行搜索的绝佳地方。他们还提供很多工具帮助你寻找相关的研究。
我使用 Mendeley 来存储和组织研究论文。
你不是失败者,你只是还没成功。无法知道哪个机器学习算法最适合用来解决问题。每当我碰到新问题时,如果新问题背后没有很多研究方法,那么我会看看一些可用的方法,并全部试上一遍。
深度学习(CNN、RNN 等等)和经典机器学习方法(随机森林、梯度提升等等)。
对所有试验结果进行排序,然后对表现最佳的算法进行加倍。
查看数据驱动方法来选择机器学习算法:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
亚当优化算法(the Adam optimization algorithm)是经过验证的。它在所有的深度学习问题常常有令人惊讶的结果。即使它有出色的性能,但是它仍然会让你深陷局部最小问题的迷津。具有亚当优化算法的好处,并有助于消除陷入局部最小问题迷津的一个更好的算法是热重启的随机梯度下降法(Stochastic Gradient Descent with Warm Restarts)。
关于学习速率的好文章在这里:
https://towardsdatascience.com/estimating-optimal-learning-rate-for-a-deep-neural-network-ce32f2556ce0
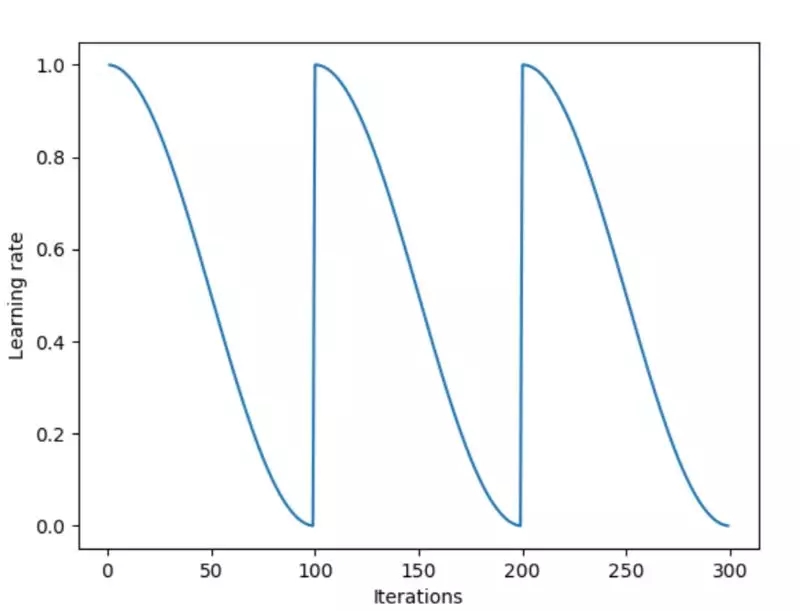
标准程序使用具有大量的期的大型批来处理现代深度学习实施,但是共同的策略产生共同的结果。用你的批大小和训练期的数量来做试验。
这是减少深度学习系统泛化错误的绝佳方法。持续训练也许会提高数据集上的精度,但是到了某一时刻,在模型尚未观察到的数据上的模型精度就会降低。为了提高真实世界的性能,试试提前停止。
提前停止的示例:
https://stats.stackexchange.com/questions/231061/how-to-use-early-stopping-properly-for-training-deep-neural-network
如果想试试一些更有趣的东西,那就试试高效的神经架构搜索(Efficient Neural Architecture Search ,简称 ENAS)。该算法将创建一个自定义网络设计,在数据集上把精度最大化,比起云机器学习用到的标准神经架构搜索更高效。
停止过度拟合的有效方法是使用正则化。有很多不同方法来使用正则化,可以在深度学习项目上训练。如果还没有尝试过这些方法,那么我建议在每个项目中都试试。
这些尝试保持在网络中的所有权重尽可能小,除非有大的梯度可以抵消它。除了经常提高性能之外,它还有易于理解模型的好处。
无法选择最好的模型来用?通常,可以把不同模型的输出组合一下,获得更好的精度。这些算法中的每一个都有两个步骤。
在这种方法中,可以在同样的数据上训练一些不同的模型,这些模型在某种程度上有所不同,然后把这些输出平均一下以创建最终输出。Bagging 可以减少模型中的变化。可以直观地把它看作具有不同背景的人对同一个问题进行思考,但是这些人具有不同的起始位置。就像在团队中一样,可以成为获得正确答案的有力工具。
这类似于 bagging,区别是没有经验公式来计算合并的输出。可以创建基于输入数据的元级学习器,选择如何给来自不同模型的结果赋予权重,以产生最终输出。
休息一下吧。这个方案是从头开始重新考虑问题。我发现这有助于集思广益来解决问题。可以从问问自己这些简单问题开始:
重新考虑问题是提高性能最难的方法,但是,它常常会产生最好的结果。和其他有深度学习经验的人聊聊,有助于找到解决问题的新方法。
阅读英文原文:
https://towardsdatascience.com/deep-learning-performance-cheat-sheet-21374b9c4f45

 友情链接
友情链接