








公众号/AI前线
作者 | Ted Dunning
译者 | 谢丽
编辑 | Vincent
AI 前线导读:本文将重点介绍实时或近实时监控机器学习系统的方法。为此,我们不会过多地讨论模型是否生成了正确的答案,因为你通常在很长一段时间内都无法确定这一点。即便如此,我们常常可以提前很长时间发现模型是否行为不端(在某些重要方面)。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
前 言
不管你信不信,你在机器学习课上学到的东西,并不是让机器学习发挥作用需要知道的东西。学术上的机器学习几乎只涉及机器学习模型的离线评估。这一观点也得到了 Kaggle 或 Netflix 竞赛的大力宣传。在现实世界中,有点令人惊讶,这往往只适合排除真狗的粗剪。对于严肃的生产工作,在线评估通常是决定从最后一轮的几个候选人中选择哪一个进行进一步使用的唯一选择。正如爱因斯坦所说,理论和实践在理论上是一样的,但实际上并不同。模型也是如此。一部分问题是与其他模型和系统的交互。另一部分与现实世界的变化有关,可能是工作中的对手,甚至可能是太阳黑子。当模型选择它们自己的训练数据时出现了一个特别的问题,它们会因此表现出自我强化的行为。
除了这些困难之外,生产模型几乎总是具有服务级别协议,这些协议与它们生成结果的速度和允许的失败频率有关。这些操作事项可能和模型的准确性一样重要……延迟返回的正确结果比及时返回的大部分正确的结果要差得多。
本文将重点介绍实时或近实时监控机器学习系统的方法。为此,我们不会过多地讨论模型是否生成了正确的答案,因为你通常在很长一段时间内都无法确定这一点。例如,如果欺诈模型说一个帐户已经被接管,那么你可能几个月都无法发现真相。然而,即便如此,我们常常可以提前很长时间发现模型是否行为不端(在某些重要方面)。
这里介绍的技术将包括使用粗粒度功能监控器、非线性延迟直方图、如何规范化用户响应数据以及如何将分数分布与参考分布和金丝雀模型进行比较。这些技术可能听起来晦涩难懂,但在这些花哨的名称背后,每个技术都有一个简单的核心,并不真正需要高级数学来理解、实现或解释。
这是个狂野的世界
让我们谈谈除了在课堂上学到的知识外,你还需要注意什么。如果它能像在课堂和比赛中那样发挥作用,那么这个世界绝对会更简单,但它远没有那么简单。不仅提取正确的训练数据需要大量的工程工作,实际运行的模型还必须处理一些非常复杂的现实问题。如果你正在构建一个欺诈模型,欺诈者将调整他们的方法以逃避你的模型的检测。如果你在做市场营销,你的竞争对手总是在寻找方法来超越你的努力。即使是不依赖于人类行为的系统,比如飞机引擎或工厂,也会出现意外。这些意外可能是两个引擎的鸟击,或者铣床的意外升级,甚至是一些相关的问题,比如市场状况或天气。
即使数据环境没有改变,也可能会出现设备故障,导致世界看起来奇怪而令人惊讶。
无论你正在构建什么样的机器学习系统,你都需要监视你的模型,以确保它们仍然按照你认为的方式工作。让我们来看一些有助于发现问题的具体技术。
基础监控
模型性能最基本的方面是它是否收到请求以及它产生结果的速度。如果你不要求,没有哪个模型能给出好的结果。除非你能适时得到它们,否则结果不会好。
为了监控请求是否到达,你需要记录每个传入请求的到达,以及请求到达的机器的名称和准确的时间戳。最好是将这些数据记录到分布式平台上的持久流中,因为如果机器宕机,日志文件可能会消失。另外,最好将请求的到达和完成记录为单独的事件,这样就可以将响应失败与缺少请求区分开来。你可以构建的最简单的监控器是测量请求之间的时间。更进一步的话,是构建一个简单的预测器,根据最近的请求率预测当前的请求率,并使用预测的请求率乘以自上次请求以来的时间。即使是一个简单的线性模型,通常也会提前一个小时预测请求率,误差小于 10%,这使你可以在请求停止时发出警报。通过绘制维基百科“圣诞节”页面的预测流量,我们可以看到这种预测可以多么准确地工作,如图 1 所示。
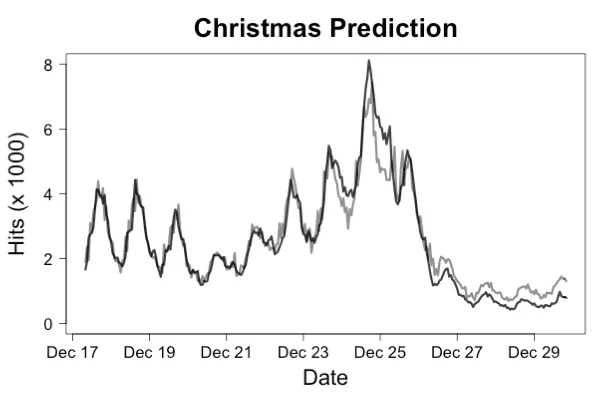
图 1.11 月实际流量(黑线)与预测流量(灰线)对比,流量预测模型基于 11 月份的流量进行训练。尽管圣诞节前后的流量状况与训练期间的流量截然不同,但预测的准确性足以迅速检测出系统故障。
这个预测使用的模型是线性回归,使用最近 4 小时、24 小时前和 48 小时前的流量速率来预测现在的流量。此预测可用于检测请求速率异常,如图 2 所示。
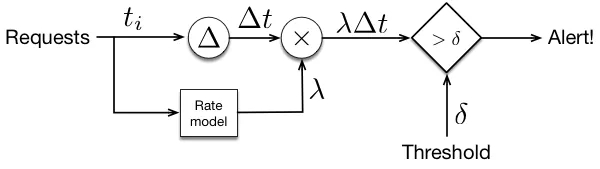
图 2. 请求速率异常检测器的架构。阈值用于确定速率何时低于预测值,因为事件之间的时间将上升到较高的水平。预测速率用于对这个时间进行归一化。
一旦我们清楚了请求的到来,我们就可以查看我们的模型是否能够及时地产生结果。为了实现这一点,我们需要在响应每个请求时记录消耗的时间。这些日志条目应该为原始请求指定惟一的 ID、当前时间、用于计算请求的模型和硬件的详细信息以及消耗的时间。首先,我们可以计算报告中运行时间的分布。对于延迟,最好的方法是使用非均匀直方图。我们可以每 5 分钟计算一个这样的直方图。为了监控性能,我们可以积累相当长的一段时间内的背景数据,并根据这些背景数据的分布绘制最近的结果。图 3 展示了我们可能看到的结果。
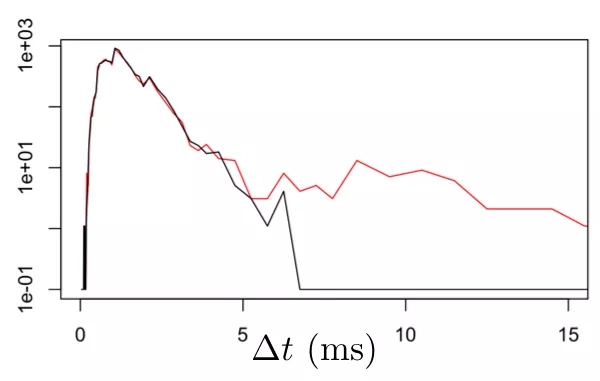
图 3. 以毫秒为单位的正常响应时间(黑线)与大约 1% 的响应明显延迟的响应时间的比较。得益于垂直轴上的对数刻度和不均匀的 bin 大小,可以清楚地看到 99%-ile 延迟的变化。
我们还可以使用更高级的自动化技术以比较相应 bin 中的计数为基础对这些直方图进行比较。一个很好的方法是使用一种叫 G 检验的统计方法。G 检验可以将每个直方图转换成一个单独的分数,描述它相对于长期背景数据的异常程度。如果对直方图中的延迟测量值进行标记,就可以比较单个直方图的慢速部分和快速部分,找出慢速部分中更常见的标记。如果这些标记表示硬件 ID 或模型版本,那么可以将其用于诊断工作。
但这是对的吗?!
到目前为止,无论模型的用途是什么,上面提到的所有方法都有效。但是,这种共性也意味着这些技术无法告诉我们任何与模型实际产生的响应有关的信息。结果好吗?对吗?我们也不知道。到目前为止,我们知道的是,请求在到达,结果正在以从历史来看合理的水平和速度产生。速度和反馈都很好,但是,我们不仅仅需要知道它们什么时候不正常,我们还需要知道它们是否正确地工作。
在某些情况下,特别是在使用营销模型时,对于我们的模型是否做得很好,我们可以在几分钟内获得初步的反馈。然而,在这样做的时候,我们必须非常仔细地比较不同的模型。特别是,我们不能仅仅比较每个模型的转化数量,因为随着时间的推移,当一个广告或商情(offer)展示给用户后,得益于旧有的曝光,会有越来越多的转化。图 4 展示了发生了什么。
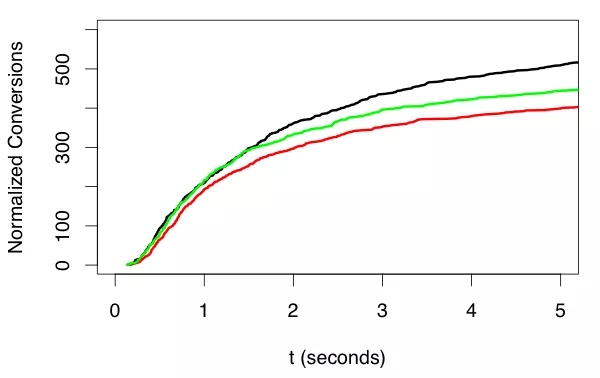
图 4. 转化需要根据原始曝光时间和曝光次数进行规范化。比较也必须在曝光足够长的时间以后进行,从而获得可靠的比较,但等待的时间过长也无济于事。在这里,绿色轨迹一开始看起来是最好的,但是在曝光 2 秒之后,只接收到 60% 的转化,很明显,黑色是最好的,红色是最差的。选择适当的延迟可以最快地对模型进行准确的评估。
问题是,一份商情或广告的每一次曝光都独立于所有其他曝光。如果收到这个曝光的人会做出回应,他们可能会在看到这个曝光后很快做出回应。然而,有些人会比其他人花更长的时间,有些人可能会在很长时间后才做出反应。这意味着,随着时间的推移,任何商情的转化率都会逐渐上升。那么,你要做的第一件事就是根据相应的曝光时间来抵消每次转化。类似地,有些产品会比其他产品获得更多的曝光,所以你也需要根据曝光的次数进行纵向缩放。
当你这样做时,你将看到,由于统计上的差异,你必须稍等一会儿才能断言哪个商情最有效,但是通常不需要等待最终响应数值的 60% 以上。这一点非常重要,因为等待 95% 的曝光比等待 50-60% 的曝光要多花 10 倍的时间。这个技巧也很重要,因为它让我们有一个接近实时的响应率度量。
真相可能需要很长时间
尽管实时的真相反馈可能很好,但在许多用例中这都是不可能的。例如,我们甚至可能不知道一个被发现的欺诈行为已经那样几天了还是几周了。但是,我们仍然可以做一些事情来快速检测问题。
许多模型都会产生某种分数或一组分数。这些通常代表某种概率估计。作为监视器,我们可以做的其中一件最简单的事是查看模型生成的分数分布。如果分布发生了令人惊讶的变化,那么很有可能模型的输入发生了重要的变化,这反映了外部世界或者模型所依赖的系统的一些变化,例如,特征提取在某些方面发生了变化。在这两种情况下,要弄清楚发生了什么事情,发现变化是第一步。
检测这种变化的最佳方法之一是使用一个名为 t-digest 的系统。你不能用我们讲过的日志直方图来表示延迟分布,因为分数不像延迟那样有很好理解的特征。t-digest 使用起来成本有点高,但是它几乎可以处理你抛给它的任何东西。然后,该方法每分钟会存储分数分布摘要,或者用模型版本之类的标记。要检查分数分布,你可以累积过去存储的许多摘要来获得参考分布,并将该参考分布与最新的摘要进行比较。
有两种比较分布的流行方法。一种是使用参考分布的十分位数作为 bin 边界,然后使用最新的摘要来估计每个 bin 中有多少个样本。如果分布是相同的,那么每个 bin 中最新数据的样本数量就应该是相同的。这一点可以像以前一样使用 G 检验来验证,以便在分布存在有趣地差异时得到较大的分数。
另一种方法是使用一个称为 Kolmogorov-Smirnov 统计量的值来直接检测参考分布和最新分布之间的差异。在即将发布的 t-digest 版本中有代码可以计算这个统计量,但最重要是,当分布差异很大时,统计量很大,而当分布没有差异时,统计量很小。
没有什么会向你报告
一般来说,我们对模型应该做什么了解得越多,与参考行为的比较越具体,我们就越能快速而可靠地检测到变化。这就是使用金丝雀模型的动机。我们的想法是,像往常一样将每个请求发送到当前的生产模型,但是我们也保留了模型的旧版本,并将每个(或几乎每个)请求发送到这个旧版本。旧模型叫做金丝雀。
因为我们是把完全相同的请求发送给两个模型,而且,因为金丝雀也是一个模型,它所做的事情和我们希望当前模型所做的事情几乎相同,所以我们可以按请求比较两个模型的请求输出,从而对新模型行为是否符合预期有一个非常具体的了解。金丝雀模型和当前的冠军模型之间的平均偏差是判断当前模型是否有问题的一个非常敏感的指标,特别是当我们选择了一个非常稳定(即使不是非常精确)的金丝雀模型。
当我们要派出一个潜在的挑战者来挑战我们当前的冠军时,金丝雀模型也非常方便。如果我们试图量化推出新挑战者取代当前冠军的风险,我们就可以看看挑战者和冠军之间的差异以及金丝雀和冠军之间的差异。特别是,一旦我们有了一个很好的模型并进行增量改进,就不会有新的挑战者和当前冠军有很大的差别,也不会和金丝雀有很大的差别。有差别的地方就是我们面临低准确度风险的地方,也是挑战者有机会脱颖而出的地方。将注意力集中在这些具体的人工检查实例上,通常可以让我们了解挑战者是否准备好与冠军较量。
小 结
本文介绍了一系列用于机器学习模型近实时监控的技术。首先,本文介绍了一些纯粹关注请求速率和响应时间等总体运行特征的监视器。它们通常非常适合在评估请求时检测系统级问题。接下来,我们讨论了如何对搜索结果或营销曝光等情况下的响应进行归一化,从而可以对它们进行比较清晰地对比并对准确性进行近实时地评估。在我们不清楚我们的模型应该输出什么的情况下,我们讨论的方法是通过与模型过去的性能或金丝雀模型进行比较来寻找分数分布的变化。
你可能不会需要实现所有这些监控模型的方法,但是你应该实现其中几个。你永远不知道有什么是隐藏的,直到你看,而你肯定需要知道。
作者简介
Ted Dunning 是 MapR 的首席应用架构师,同时也是 Apache 软件基金会的董事会成员。他在创建成功的初创企业方面有着悠久的历史,在这些企业中,机器学习对公司的价值产生了重大影响。他是数十项专利的发明人,并在继续开发新的算法和架构。
查看英文原文:
https://www.kdnuggets.com/2019/01/monitor-machine-learning-real-time.html

 友情链接
友情链接