








公众号/将门创投
rom: GoogleAI 编译: T.R

卷积网络的部署通常在固定资源的情况下进行,如果想要提高精度就需要更多的资源来部署更大、更深的网络。实际应用中,人们可以把ResNet-18拓展到ResNet-200增加层数提高精度,谷歌近期提出的GPipe也利用提升规模的方法在ImageNet上实现了84.3%的top-1精度。
Gpipe模型与ResNet不同规模的模型
对于扩大模型的规模,通常的做法是增加卷积网络的深度或宽度,或者利用更大的输入分辨率来训练和测评。虽然能够大幅度提升精度,但需要复杂的手工调校来进行优化。
那么我们能不能找到一种更为通用的方法来使扩大CNNs的规模以得到更好的精度和速度呢?谷歌在今年的ICML会议上给出了一种可行的解决方案。
研究中提出了一种名为EfficientNet,通过简单高效地混合系数来结构化地扩大CNNs的规模。与先前提高网络维度参数不同,这种新的方法不会去调整宽度、深度和分辨率,而是利用固定的规模系数集均匀化地对每个维度进行扩增。
基于这种规模化方法和自动机器学习,研究人员开发出了新的网络家族EfficientNets,不仅在精度上超过了前辈,更在效率上有了10倍的提升。
研究人员首先系统地分析了不同维度上的规模化对于模型的影响。

分别对于不同的维度进行规模化后,研究人员发现对于网络宽度、深度和图像分辨率等所有维度的平衡下对于模型的表现提升最好。所以混合而不是单一的改变模型的规模是提升性能的较好选择。
混合规模化方法的第一步是进行栅格搜索,在固定资源限制的条件下寻找不同规模维度下的关系。这将为不同的维度寻找适宜的规模化系数来实现最好的效果。随后利用这些搜索到的系数来对基准网络进行扩充,在给定的计算资源和模型大小下实现目标模型。
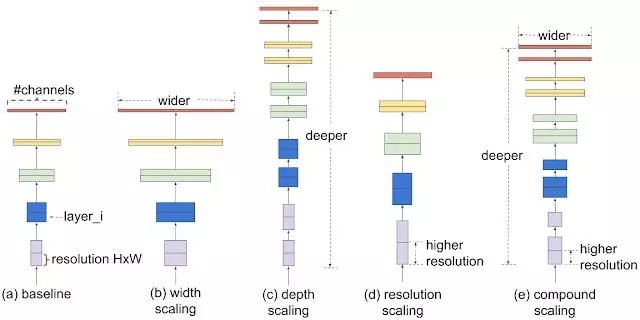
实验表明这种混合规模化方法比mobileNet(+1.4%)和ResNet(+0.7%)都有提升。
前述的模型在规模化的时候依然高度依赖于基础网络模型。所以为了更好的提高模型的表现,研究人员提出了新型基准网络模型。利用自动机器学习框架来进行神经架构搜索,同时优化了精度和效率(FLOPS)。
最终的架构类似MobileNetV2和MnasNet,使用了移动反转瓶颈卷积结构(mobile inverted bottleneck),但在规模上有些许扩大。基于这一基础网络,研究人员利用不同的扩充方式得到了规模化的网络家族EfficientNets。
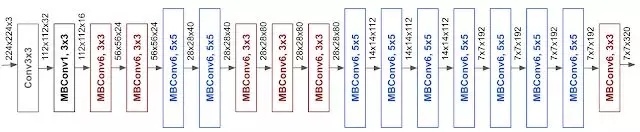
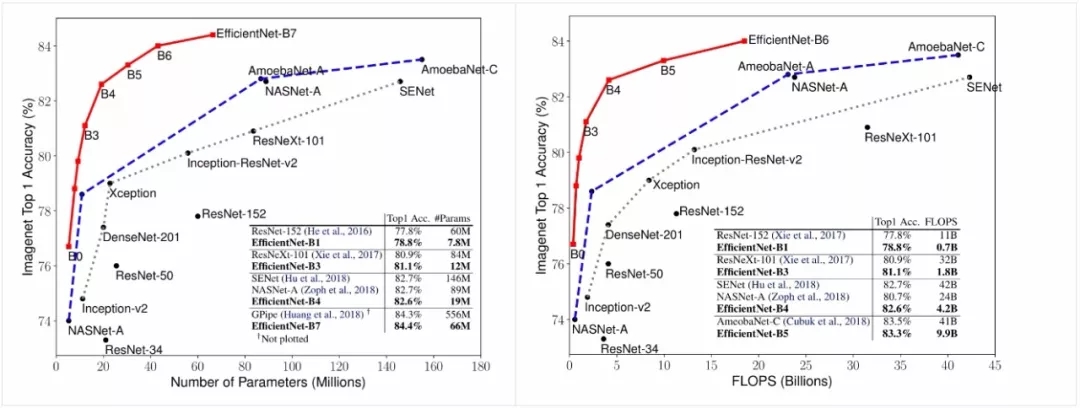
为了测试模型的性能,研究人员在ImageNet上对现有的先进模型与EfficientNet进行了比较,结果表明EfficientNet在精度和效率上都超过了现有的模型,甚至在相同精度下将模型参数和操作减小了一个数量级。
在下图中可以看到,在左上角的高精度区域,B7型EfficientNet在ImageNet上达到了84.4%的top-1精度和97.1%的top-5精度,但与先前的GPipe相比在CPU上的运行使用的参数减小了8.4倍同时速度提升了6.1倍。与广泛使用的ResNet-50相比,相同参数的情况下提升了6.3%的top-1精度。
此外,为了验证模型的其他数据集上的表现,研究人员还将模型迁移到了CIFAR-100和Flowers上,EfficientNet在参数减少一个数量级(21x)的情况下在8个测试数据集中的5个上取得了最好的精度,证明了这一方法具有稳定的泛化能力。
这种新的模型有望成为计算机视觉任务的新基准,研究人员开源了所有的代码,同时可以看在这里找到基于TPU的加速实现:
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
在这里还有在TPU上训练模型的详细教程:
https://cloud.google.com/tpu/docs/tutorials/efficientnet
在论文里找到更多的细节:
https://arxiv.org/pdf/1905.11946.pdf
ref:
https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
https://cloud.google.com/tpu/docs/tutorials/efficientnet
https://arxiv.org/pdf/1905.11946.pdf
picfrom:https://dribbble.com/shots/4908992-investment-increase

 友情链接
友情链接