








公众号/将门创投
编译:T.R.
食物是我们每天必不可少的能量补给,也是很多吃货小伙伴的快乐源泉。计算机视觉的发展,对于食物的分析和推荐为我们的餐桌提供了新的可能。拍一张照片就可以从这一餐的食物中分析出食材的营养成分和卡路里的多少,帮助我们监控每日能量和营养的摄入,并对膳食进行管理。
除了分析和记录,计算机辅助食物分析还能对食材的属性进行分析并对烹饪后的食物色、香、味进行预测,不同烹饪方法下食材在最终菜品下呈现的样式。但食物的烹调方式多种多样、在不同菜品中呈现的样子也各不相同,更别说各种无法直接看到的调味料了。如此复杂的视觉任务需要大量的数据来对算法进行训练,但数据的缺乏阻碍了这一领域的发展。
为了更好地推动这一领域的进步以解决计算机食物分析的挑战,来自罗格斯大学和三星AI中心的研究人员们提出了一种新的食物合成方法,从食材原料的名字直接合成菜品的图像,为食物分析和预测提出了新的可能。
对于食物图像的生成,研究人员们进行了诸多有益的探索。虽然基于CycleGAN的方法实现了对食物的风格迁移,但是目前还没有能够从不同的食材配料中直接生成食物图像的方法。
食物图像合成不仅引入了包括食材属性、加工方法、烹调方式的复杂性,同时多样性的菜品还极度依赖烹调的过程,生成模型必须能捕捉信息中隐含的关键点才能重建出有效的菜品。
在这篇文章中,研究人员结合基于注意力的菜谱相关模型和StackGAN来从食材中生成对应的菜品图像,随后利用了循环连续约束来进一步提高了生成图像的质量、并有效改进了改变原料后生成的菜品效果。

为了寻找到更为合适的编码来表示食材与食物图像间的关系,研究人员使用了基于注意力的联合模型来训练得到隐空间的编码方法。这一模型一共包含了三部分,分别是食材编码器、联合食物隐空间和美食图像编码器。
整个网络的目的是将食材信息从文字中抽取出来并送入对应的编码隐空间中去,而对应的食物图像也进行编码映射到隐空间中,并最大化食材信息编码和对应图像编码的余弦相似性。

食材原料编码器的目的在于将菜谱中的食材转化为共享隐含空间中的特征。这一部分的目标是寻找出食材间隐含的关系,甚至将佐料这样不明显的配料信息也挖掘出来。
研究人员通过独特编码的食材嵌入到低维向量空间中,并作为序列输入到双边的LSTM中进行训练,每一层的隐空间输出都作为对应食材的特征,并在最后利用注意力机制将这些特征融合起来,基于加权方法融合所有的隐含状态,最终映射共享食物隐含空间中的高维食材特征p(1024维)。
图像编码器的目的是将食物图像转换为食物空间中的特征,利用Resent50作为主干网络,并利用UPMC-Food-101对模型进行精调最后利用平均池化后的激活(2048维),映射到食物空间中去得到隐变量q(1024维)。
通过对两种模态数据在共享隐空间中的训练后,得到了有效的食材特征表示p,我们就可以基于这一有效的特征利用GAN来合成逼真、有效稳定的食物图像了。
为了将输入的食材单转换为对应菜品的图像,研究人员基于StackGAN-v2来生成菜品图像。这一模型包含了三个分支,每一分支都负责生成某种分辨率下的图像,也对应着自己独立的判别器(对应高、中、低分辨率的生成图像)。
菜谱中的食材数据首先被编码成共享隐空间中的向量p+,随后利用条件增强网络Fca来估计外观因子相关的分布p(c|p+)。将c与噪声z同时输入到第一个分支中进行低分辨率图像生成。通过F0生成隐含特征,并通过T0生成对应的图像。此时前一个分支的隐含特征将作为下一个分支的输入来生成更高分辨率的图像。
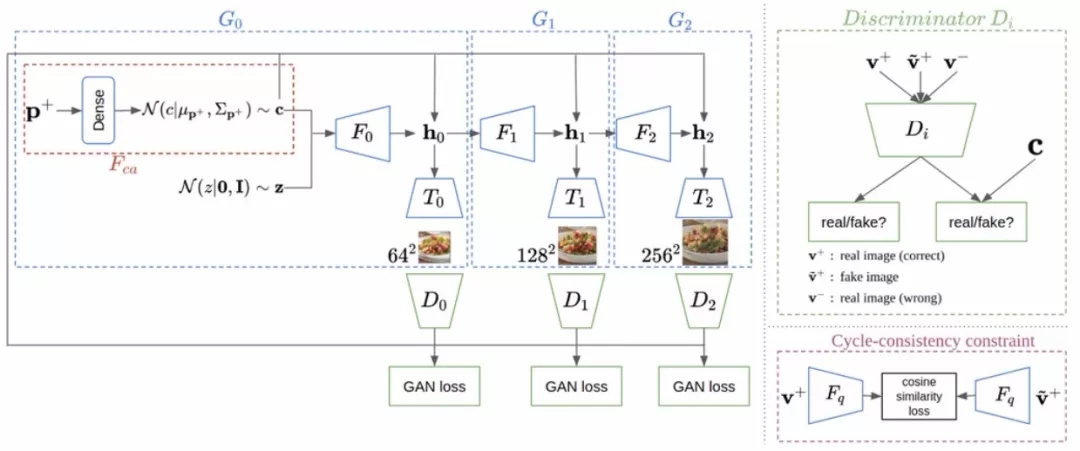
生成模型包含了三个生成器和判别器,用于生成高中低三种不同分辨率的图像。
模型中的判别器需要同时完成三个功能,首先需要正确识别出对应菜品真实图像,同时也需要能够区分出真实/错误对应的菜品图像,还需要识别出模型生成的伪造图像。这样就能训练网络生成出与训练数据中食材对应菜品图像更为接近的结果。
为了检验基于注意力的联合模型对于特征的抽取能力,研究人员首先进行了基于菜谱食材的对应图像检索实验。在实验中研究人员基于Recipe1M数据集进行训练,并抽取了其中1989种常见食材,并使用拥有多张菜品图和多种食材的菜谱。
在实验中主要利用了中位检索排序(median retrieval rank, MedR, 越小越好)和top k召回率(recall at top K, R@K,召回越大越好)来对结果进行度量。从下表中可以看到研究人员提出的方法将MedR下降了很多,同时提升了R@K。

下图展示了菜谱中的食材检索出的top5对应图像。可以看到检索出的图像都属于同一类,证明了模型对于原材料的理解和特征抽取具有泛化性。

随后研究人员针对沙拉、饼干和松饼等三类西方常见的食物进行训练和合成,并利用感知分数和Frechet感知距离来作为评测指标。下图可以看到本文提出的方法合成出的食物特别逼真,同时也真实反映了食材的构成。

对于同样的食材输出,模型生成的菜品图像表现也很稳定:

最后研究人员还分析了隐含特征空间中的线性插值情况,在两个不同的菜谱间进行差值可以看到一盘菜渐渐变成了另一盘了!

有了这样的模型,下次买菜回来不知如何下手的时候,要不要先问问AI这些食材将会变成什么样的美食呢?说不定它合成出的食物图像将会启发你在厨房的想象力呢!enjoy~~~
如果想了解更详细的论文,请参见:
https://arxiv.org/pdf/1905.13149.pdf
ref:
triplet loss:http://blog.csdn.net/u013082989/article/details/83537370
facenet:https://arxiv.org/abs/1503.03832
imagefrom:https://dribbble.com/shots/5684158-Holiday-Traditional-Turkey-Dinner
https://dribbble.com/shots/6308970-Cheat-meal-plans
https://dribbble.com/shots/5716771-A-meal

 友情链接
友情链接