








公众号/将门创投
From:SenseTime 编译:T.R
面部图像操作是计算机视觉和计算机图形学里十分重要的研究方向,包括自动表情生成和面部风格迁移方向都离不开它的身影,也成为了美妆app里重要的AI技术。面部操作主要分为语义和几何两个方向,但目前的方法大多局限于一系列预定义属性的操作方法,限制了用户随心所欲变换人脸属性的自由。
为了克服目前系统缺乏自由操作的缺陷,来自商汤、港中文和港大的研究人员们提出了一种支持用户自由交互、多样性操作的新方法MaskGAM,它利用人脸的语义掩膜作为人脸操作和人脸信息的有效中介,在mask空间中进行的操作代替了直接在像素空间中对图像进行的操作,使得生成的结果具有更丰富的多样性,也为用户提供了更加直观的方式来对面部的各个属性进行修饰和编辑。

MaskGAN主要有两方面的构成,一方面是负责学习从语义掩膜到输出图像间映射的稠密映射网络(DenseMappingNetwork,DMN),另一部分是负责为用户对源图像掩膜进行建模的编辑行为模拟训练部分(Editing Behavior Simulated Training)。
稠密映射网络DMN 由一个生成器主干网络和一个空间注意力风格编码器构成。空间注意力编码器利用图像和对应的语义掩膜作为输入,并将得到的空间注意力特征编码送入图像生成主干网络,随后图像生成网络基于空间注意力特征和语义掩膜编码的特征生成对应的面部图像。这一稠密映射网络可以学习出用户编辑掩膜与目标图像间的细粒度风格映射。
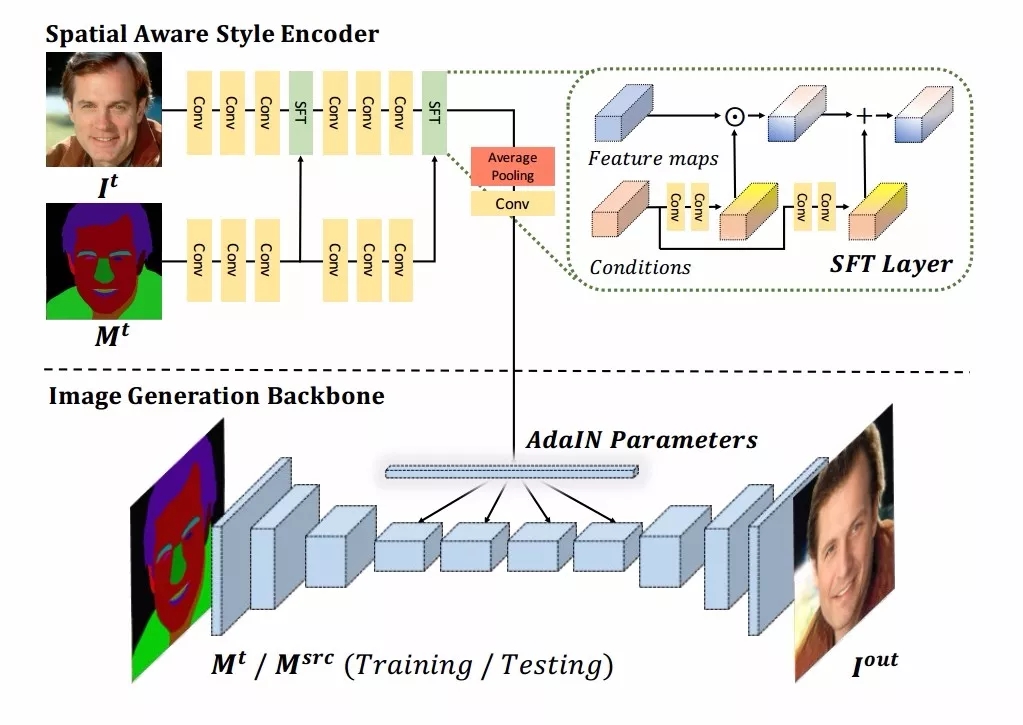
DMN采用了Pix2PixHD 作为主干网络,并增加了空间注意力编码器来融合目标图像与掩膜间信息。随后生成器将这一部分的信息融合生成出逼真的真实图像。
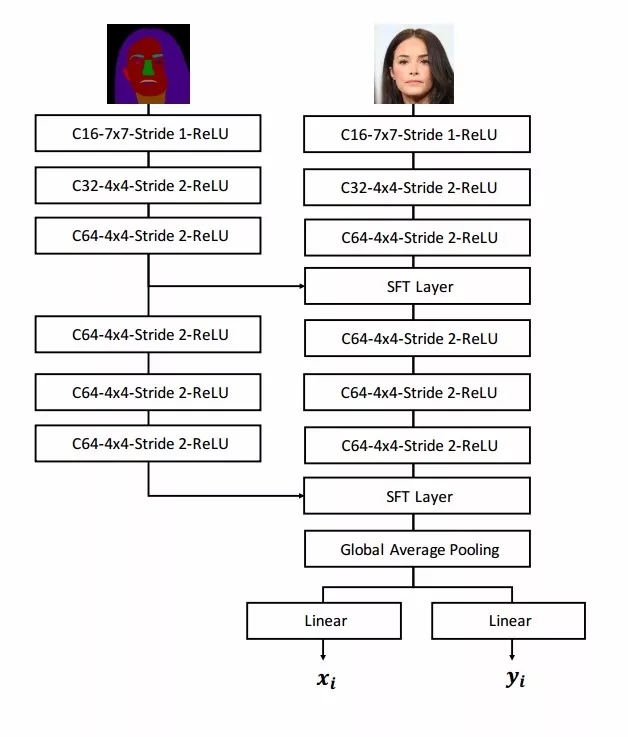
空间注意力特征编码器和对应的空间特征转换层SFT
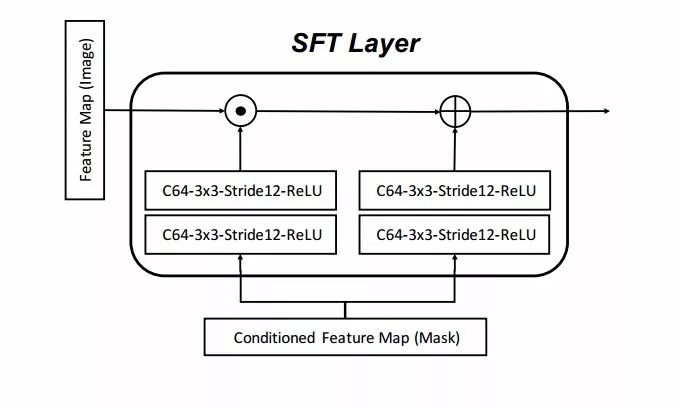
在编码器中,研究人员采用了空间特征转移层来将学习出仿射变换参数,并给予参数来对特征图进行逐通道和空间调制,最终得到包含空间注意力风格的仿射参数信息。随后研究人员使用自适应实例归一化来将得到的空间注意力信息转移到主干网络上。
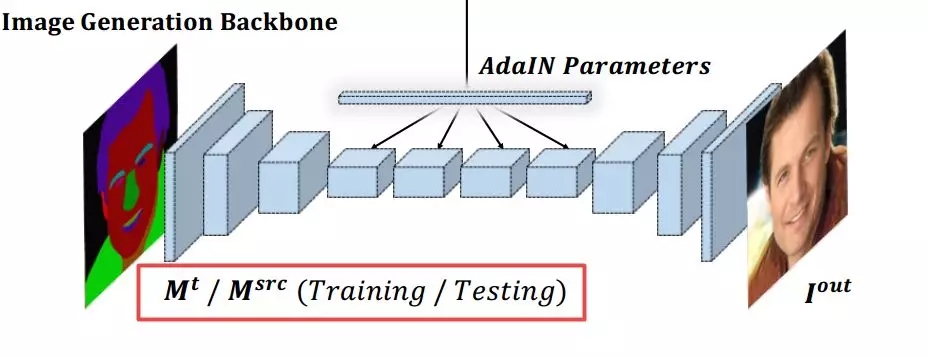
最终生成器部分的解码器在输入掩膜以及掩膜与图像构成的空间信息编码下共同生成最终的图像。空间注意力可以有效地将目标图像的风格通过目标掩膜的信息传递给源图掩膜与输出间的映射关系。
值得注意的是,在训练时使用的掩膜来自于目标图像,而在实际时主干网络的掩膜则是源图像(或用户编辑后的源图掩膜)。
而编辑行为模拟训练部分则用于为用户的编辑行为建模,使得生成模型对于各式各样的编辑具有更好的鲁棒性。它主要由先前得到的稠密映射网络DMN、预训练的MaskVAE、以及alpha 通道的融合子网络共同构成。
其中MaskVAE 由编码器-解码器构成,主要负责几何结构先验的流型建模;而alpha融合子网络主要用于融合图像来帮助网络保持操作过程中的连续性。通过这些子模块的联合训练将为生成模型在面对多样性的用户编辑、输入时提供更好的鲁棒性。
MaskVAE与自编码器很类似,主要用于处理结构的先验信息,其损失函数包括了重建语义掩膜的逐像素损失和在隐空间中控制语义标签平滑的KL散度项。MaskVAE可以对语义标签进行平滑的转换,在隐空间中的线性插值结果如下图所示。

整个变分自编码器通过下面的结构来进行训练,并最小化重建误差。
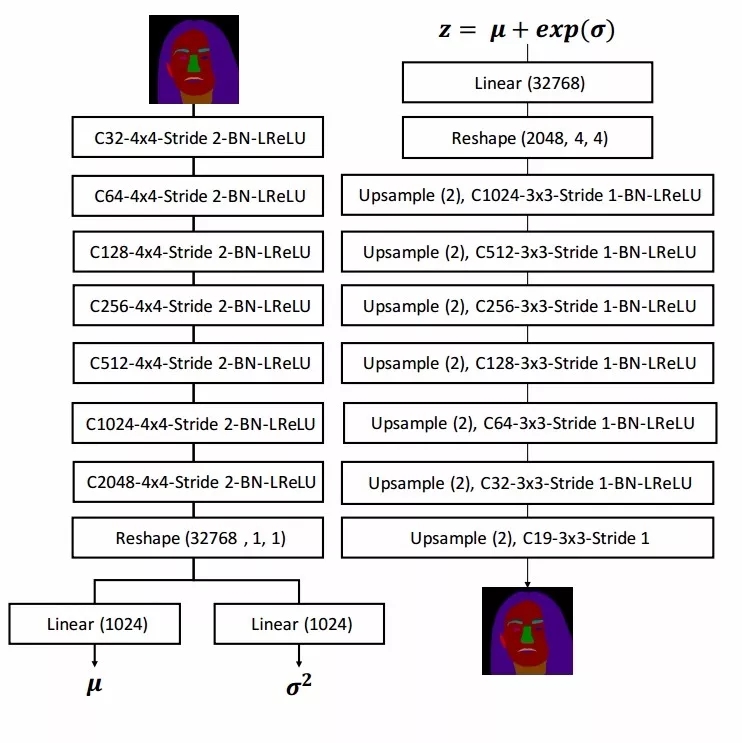
训练好的MaskVAE在整个方法流程中的主要目的是为输入掩膜分别生成内插和外插新掩膜,为后续的融合提供条件。
AlphaBlender的主要作用是保证图像操作的连续性,它可以维持融合结果与目标结果检测连续性。研究人员通过深度学习AlphaBlender来学习出融合参数合成最终图像。融合模型在训练过程中与与两个DMN进行联合优化。这一部分的模型被定义为融合生成器GB。
模型的训练过程一共分为两个阶段,分别是对于稠密映射网络的预训练和针对用户编辑行为模拟的增强训练以提高生成器鲁棒性。
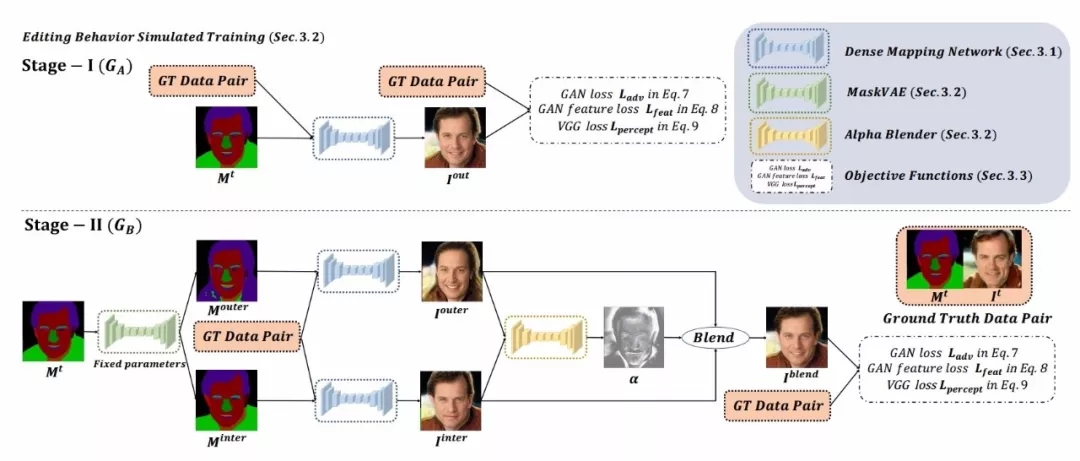
第一阶段的训练。首先需要利用基准图像It 和对应的掩膜Mt 训练稠密映射网络,使得模型学会从掩膜到图像的映射过程。随后利用预训练的映射模型DMN、MaskVAE,以及联合训练和AlphaBlender来实现。

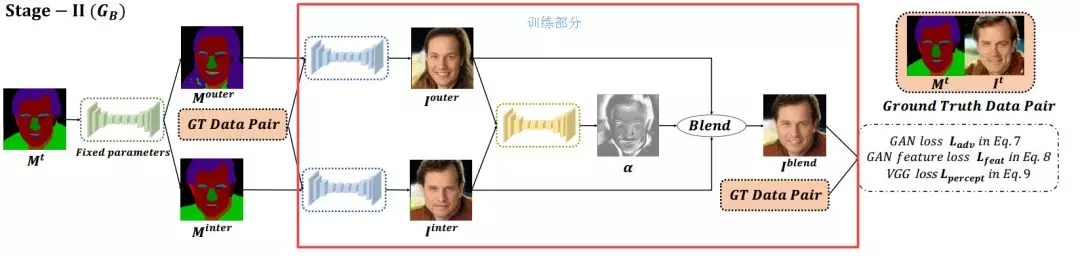
第二阶段的训练。一张输入的掩膜通过MaskVAE (在隐空间中)经过内插和外插得到了两张不同的掩膜,而后与对应的GT 图像与掩膜分别送入到两个稠密映射网络中生成出外插图像和内插图像;将两幅图像再输入到Blender模型中学习出融合参数的权重图,将图像进行最后的融合生成结果。在第二阶段的训练中,MaskVAE 的参数固定,而两个DMN 生成器和Blender 权重网络进行联合优化。
最终整个模型将通过多目标学习来进行联合优化,其目标函数包含了生成器的对抗损失、特征匹配损失和感知损失等,联合优化损失函数如下图所示。
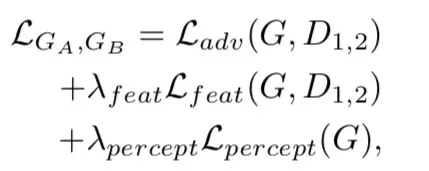
CelebAMask-HQ
为了为人脸语义分割和属性操作打下更好的研究基础,研究人员在CelebA-HQ的基础上构建了包含30000张高分辨率512×512的人脸图片,包含了面部19类详细的信息标注。针对被部分遮挡的面部区域,标注员还进行了推断补全了语义标签。与先前的Helen 数据集相比,图像的数量扩大十多倍,同时标签的数量了也增加了近两倍。

最后研究人员从语义、几何、分布以及人类感知等方面对比了MaskGAN 和先前的算法,显示了在人脸属性迁移和风格复制任务上的性能差异。下面这张图显示了MaskGAN对于人脸特定属性(如笑容)的迁移能力,在视觉感知和几何层面都很强。

MaskGAN对于风格复制也可以很好胜任,相比于先前的方法它可以对于性别和妆容有更强的迁移能力。

此外还可以通过修改图像的语义掩膜来为图中的人物添加配饰、眼镜,改变发型、脸型和各种面部属性。

消融性分析显示,对于稠密映射网络,空间注意力风格编码器可以通过先验信息保持模型不受用于对mask修改的过度影响,同时也提高了从目标图像风格迁移的准确性。
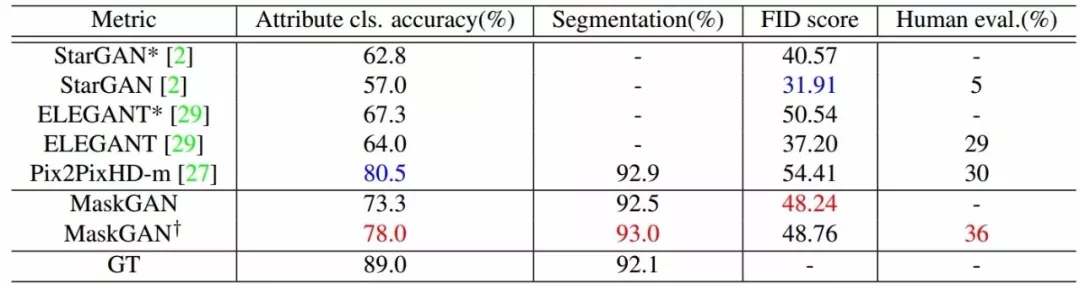
而对于编辑行为模拟训练来说,有效地改善了模型对于人脸属性保持的鲁棒性,使得人类感知得分得到了大幅提升。下表中带十字的结果为增加了编辑行为模拟训练的增强结果。

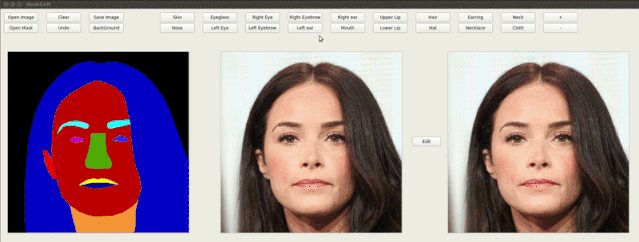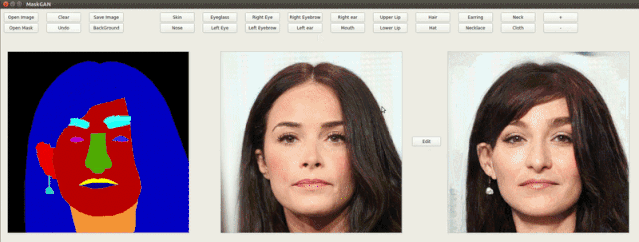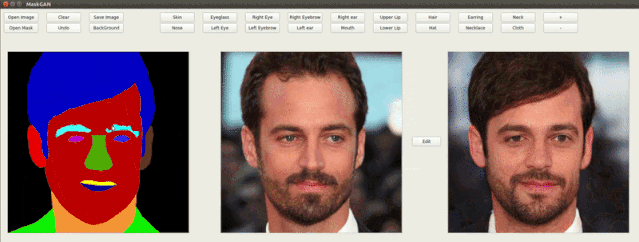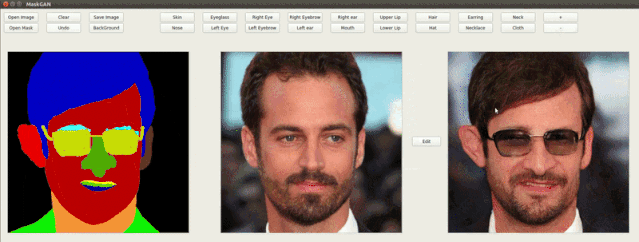
在作者的demo演示中可以看到,随意修改语义mask就可以改变生成图像的脸型、发型、面部各个部分的属性,还能添加耳环、改变眼睛,生成结果十分自然。

 友情链接
友情链接