








公众号/将门创投
From:Google 编译:T.R
理想情况下,像深度学习等机器学习模型都会被部署到与训练数据相同分布的数据环境中工作,但现实情况却与理想条件大相庭径:相机对焦产生的离焦、传感器的衰减、网络社群流行话题的变迁都会使实际应用时的数据分布与模型训练的数据大不相同,从而引起机器学习中著名的协变漂移(covariate shift)现象。

例如一个用于从X胸透中检测肺炎的深度学习模型在实际使用中精度发生的巨大的变化,究其原因则是由于新的数据来自于训练时未见过的医院数据,数据获取和处理过程的细微不同造成了算法性能的巨大差距。

提醒大家最近一定要出门戴口罩、保护好自己、平安回家啊!
为了深入研究这一问题,来自谷歌的研究人员在NeurIPS上发表了一项对模型在数据集分布漂移情况下不确定性进行评测的工作,细致地分析了前沿的深度学习模型在数据分布漂移和处于分布外数据的作用下的不确定性。
在实验中,研究人员综合考量了图像、文本、在线广告数据等不同模态数。将深度学习模型暴露在漂移不断增加的测试数据下,并仔细分析了这些深度学习模型预测概率的行为。此外在研究中还比较了不同的改善模型不确定性的方法,以寻找在数据分布发生漂移时的最佳策略。
分布外数据
深度学习模型为每一次预测提供了一个概率指标,代表了模型的置信度或不确定度。这使得模型可以对他们不知道的领域或者超出训练数据范围的输入表达不确定性。在协变漂移中,不确定性会随着精度的下降按比例的增加;在更极端的例子中,输入数据根本就不是训练数据中所表示的那样,例如分布外(out-of-distribution,OOD)数据就是一种典型的极端条件。
想象一下如果给一个猫狗分类器输入一张飞机的图像模型会得到什么样的结果?模型是会得出错误的结果还是会为每个分类分配很低的概率呢?在研究人员相关的博客中讨论过这样的OOD问题,而这篇文章的重点则在于探讨当模型面临分布外数据或者分布漂移样本时其预测的不确定性,详细分析模型预测的概率是否能反映出它在类似数据上的预测能力。
不确定性的定量和定性度量
那么一个模型相较于另一个模型具有更好的不确定性表达能力意味着什么呢?这主要由下游任务的细微差别来决定,概率预测的质量有多种定量的方法来进行评测。例如在气象学领域,科学家们针对这一问题进行了深入的研究并发展出了一系列适当的评定标准,概率性的天气预报比较函数应该满足这些评定准则,以便很好的对齐进行校准、同时提高预测的准确性。
在本研究中,研究人员使用了很多适当的评定准则,包括布莱尔分数(Brier Score)和负对数似然(Negative Log Likelihood, NLL)等,同时加入了像期望标定误差(expected calibration error ,ECE)等启发性的指标,来理解不同的机器学习模式是如何在数据集漂移的情况下处理不确定性的。
实验结果
研究人员在不同数据模态上分析了数据集漂移对不确定性造成的影响,数据的形式包括图像、文本、在线广告数据和基因数据等。下图中给出了对图像进行数据漂移操作的例子,研究人员在著名的ImageNet数据上进行了不同的数据变换和扰动,通过16中不同的图像损毁方法和5中强度调整方法来改变其数据分布。

dogs通过改变数据分布来分析模型不确定性的变化行为,例如增强图像扰动的强度、改变图像的对比度、模糊和噪声情况。
基于上面的数据,研究人员详细分析了深度学习模型在数据漂移强度增加的情况下不确定性的变化情况。下图显示了每个图像损坏级别下模型的精度和ECE,并绘制了箱式图对结果进行表示。其中不同的颜色代表了处理不确定性的方法,包括dropout,TemperatureScaling、网络最后一层进行处理以及组合方式。
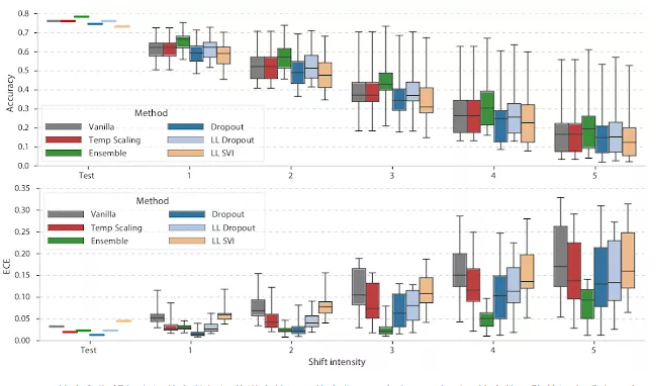
Boxplot 精度和期望标定误差在数据漂移增大情况下的变化,研究人员观察到了精度的下降并没有反应不确定性的增加,这意味着精度和ECE都在数据漂移的情况下恶化了。
在上图中可以看到,随着数据漂移强度增强,在不同图像损坏条件下的精度偏差逐渐增加,整体精度与预期相同都发生了下降。理想情况下这应该反映出模型不确定性的增长,因此期望标定误差不变。然而在较低的ECE图中可以看到这与标定通常遭受到的情况不太一样,同时在布莱尔分数和负对数似然中也观察到了相似的现象,模型的不确定性并没有逐渐增长,而是对错误结果变得更加自信。
Temperature scaling方法进行精度标定
Temperature scaling是一种广泛用于改善标定的方法,作为Platt scaling的变种它利用验证集的表象将训练后的模型预测结果变得更加平滑。在实验中研究人员发现了一个神奇的现象,当这种方法在标准测试数据上改进标定时,常常会使迁移数据上的结果更糟糕。因此,应用这种方法的技术人员应该警惕数据分布的漂移。
但幸运的是,还有一种方法在不确定性下降时更为优雅,这就是Deep ensembles方法,在图中用绿色进行了表示。它可以平均所选模型的预测值,由于每个模型具有不同的初始化状态,通过平均这种简单的策略,就可以显著提高对于数据漂移的鲁棒性。这种方法在实验中超过了其他所有的测试方法。
总结与建议
在这篇文章中,研究人员在多模态数据上对模型不确定性随数据分布漂移的退化进行了详细的研究,虽然不确定性随着数据分布的漂移不断恶化,但还是有有效的方法处理这一问题。在训练模型时不确定性需要科研人员和工程人员予以重视,必须对不确定性进行分析和处理:
1. 在分布内的测试集上改善标定和精度通常无法有效的改善漂移数据上的结果;
2. 实验表明deep ensembles方法是应对数据漂移最鲁棒的方法,通常来说很小的集成组合数(例如5)就足以实现鲁棒的额结果,集成的有效性为改善其他方法提供了可能的方向;
3. 为了推动这一领域的研究,研究人员开放了所有的研究代码和数据,希望能为深度学习预测不确定性的研究做出贡献。
如果想要了解更多细节,请参看论文:
https://arxiv.org/pdf/1906.02530.pdf
也可以在下面的链接找到代码:
https://github.com/google-research/google-research/tree/master/uq_benchmark_2019
ref:
covariate shife:
https://blog.csdn.net/LilyNothing/article/details/56284788
https://zhuanlan.zhihu.com/p/26352087
https://blog.csdn.net/guoyuhaoaaa/article/details/80236500
https://www.cnblogs.com/bonelee/p/8528722.html
DeepEnsembles for uncertainty:
https://arxiv.org/pdf/1612.01474.pdf
Corruptions ImageNet:
https://github.com/hendrycks/robustness
boxplot:https://blog.csdn.net/qq_39179446/article/details/80081509
https://www.mathworks.com/help/stats/boxplot.html;jsessionid=18bb9c2bca288f70de09f3134fff
TemperatureScaling:http://blog.sina.com.cn/s/blog_6e3db55f0102y1wc.html

 友情链接
友情链接