








公众号/大数据文摘
大数据文摘出品
来源:science
编译:一一、Andy
现在的AI看上去越来越智能了,每一代IPhone都不光比上一代 Bigger,还Smarter,能更好识别你的脸、声音和操作习惯。这些都得亏更快的芯片、更多的数据还有更好的算法。
但最近MIT计算机系的毕业生Davis Blalock表示,有些所谓进步仅仅只是微小改进(甚至没有进步),而不是其提出者称的重大创新。Blalock和同事们对比了几十种神经网络剪枝的方法。他说:“分析了五十篇论文,还是很难搞清楚到底是哪里有进展。”
研究评估了81种剪枝算法——一种通过去除不必要连接来提高神经网络效率的算法,几乎所有算法都称其在某方面有很大进步。但这些算法很少被实际进行公平对比,于是当研究人员从各个方面对这些算法进行评估后,却发现没有任何证据表明过去10年中有什么进展。
这份发表在三月MLSys会议上的论文,让Blalock的导师John Guttag也感到十分惊讶,他认为这种技术停滞可能来源于不合理的对比。他说:“其实都是老生常谈吧。如果你无法正确评估,那就很难做得更好。”
最近研究人员开始醒觉,AI某些子领域进展其实非常缓慢。2019年一个对搜索引擎中信息检索算法进行的汇总分析,得出结论“真的里程碑在2009年就出现了”。2019年的另一项研究复现了7个神经网络推荐系统,发现几年前的一个更简单的非神经算法在精调后比其中6种方法都要好,这无疑诠释了何谓“虚幻进展”。
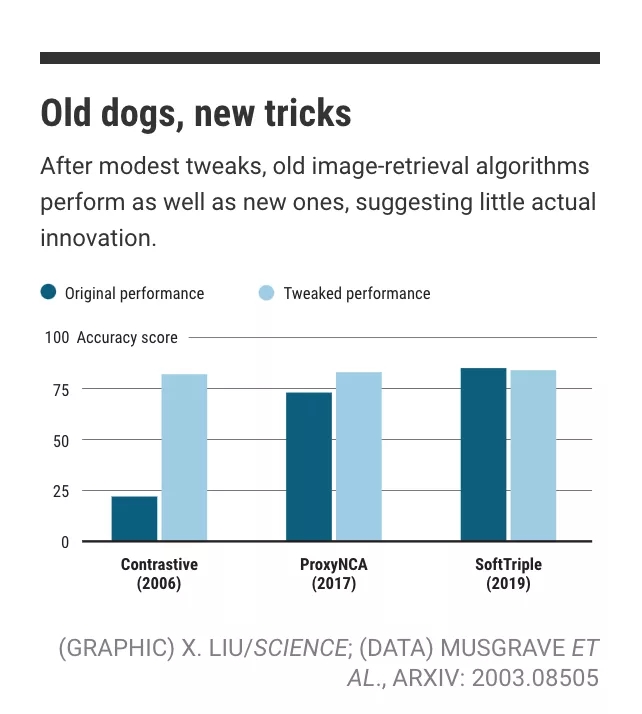
康奈尔大学计算机科学家Kevin Musgrave三月发在ArXiv上的另一篇论文里,研究了损失函数。论文中Musgrave公平地比较了多个损失函数,却发现与开发人员说的相反,其实自2006年后,准确性就没有提高。Musgrave说:“这些夸大宣传一直都有。”
机器学习算法的进步主要来源架构、损失函数以及优化策略(怎么根据反馈更新参数)的根本改进。但Zico Kolter,一位来自 CMU的计算机科学家,表示对于上述任意方面的微小调整其实都能提升模型表现。Zico Kolter主要研究能防御黑客“对抗攻击”的图像识别模型,其中一个很早就提出的对抗训练方法projected gradient descent(PGD),主要通过在真实和虚假数据上进行模型训练实现。其后一些复杂得多的模型表示已超越了该方法。但在2月arXiv上发表的文章中,Kolter和同事们却发现,在使用了一些简单技巧后,几乎所有方法表现都差不多。
新瓶装旧酒?
在微小的调整后,旧的图像检索算法和新的表现一样优秀,这表明新算法只有微小的创新。
“之前都没人注意到这点,真的很让人惊讶。”Leslie Rice(Kolter的PHD学生)说。Kolter表示该发现表明像PGD这样的创新其实很难被超越,也不太容易进行大幅提升。“事实上PGD就是很好用的算法了。”他说,“但很明显的是,人们还是想去找一些过于复杂的方法。”
其他算法的重大进步似乎也都经受住了时间考验。比如1997年的一大突破,被称为长短时记忆(LSTM)的主要用于语言翻译的架构。经过适当训练后,LSTM能达到20年后提出的更先进架构差不多的性能。另一大机器学习突破是2014年的生成对抗网络(GANs),通过“生成和判别”循环来不断增强图像生成能力。2018年一篇论文发现,只要有足够算力,原始的GAN方法也能达到之后方法差不多的性能。
Kolter表示,研究人员更愿意创造一种新算法并对其进行调节直到达到最好表现,而不是改进现有算法。他指出,“后者似乎创新性不够,所以不好写论文”。
Guttag表示,很少有人会为了去发现自己的突破不值一提,而去做很全面的实验对比。因此“进行太过认真的对比反而有风险。”而且还很困难,因为 AI 研究人员使用不同的数据集、调优方法、性能指标还有基准模型。这使得“很难做到一一对应的比较”。
有些过度夸大的表现可以被归因于该领域的爆炸式增长,其论文数量甚至超过了审稿人数量。Blalock说:“这让大家越来越痛苦。”他必须得敦促审稿人坚持进行更好的模型对比,并表示更好工具或许会有帮助。年初,Blalock的合著者,麻省理工学院的研究员Jose Gonzalez Ortiz就发布了名为ShrinkBench的软件,使得比较剪枝算法更容易了。
研究人员指出,即使新方法从根本上不比旧方法好,但它们所实施的调整也可以应用于旧方法。每隔一段时间,当量变积累到一定程度,就会出现一种新算法实施质的突破。Blalock表示,“就好比风险投资组合,尽管一些企业不能成功,但有些却能非常成功。”
相关报道:
https://www.sciencemag.org/news/2020/05/eye-catching-advances-some-ai-fields-are-not-real

 友情链接
友情链接