








公众号/将门创投
From:Google; 编译:T.R
据统计,截至7月27日,美国新冠肺炎感染病例已超过427万,全球疫情形式仍十分严峻。对人群进行大规模的传染病筛查已成为非常重要和基础的防疫问题。然而,大海捞针,何其难也!为了提速超大规模感染筛查,来自谷歌的研究人员提出了一种基于贝叶斯方法的序列群体检测方法,能够大幅减少感染筛查所需测试,为类似于COVID-19的大流行检测提供了有效且快速可靠的检测方法。
今天的故事要从二战时候说起。当时大量的士兵被征召走上前线,但为了避免病原体进入军队,医生需要快速筛查出新兵中带有感染源的人。如何高效快速地进行检测成为了医生们头疼的问题。一个年轻的统计学家Robert Dorfman为这个困难提出了一个简单但十分有效的解决方案(他日后也成为了哈佛大学的经济学教授)。他在一篇开创性的论文中阐述了一种两阶段的方法来大幅减少精确定位感染目标所需的检测次数。首先将采集的独立样本分组,取出每个样本的一部分混合成为一组测试样本,直接对一组测试样本的测试代替了对每个样本的测试。如果这一组测试结果呈阴性,意味着整组样本都没有感染;如果呈阳性,意味着其中至少有一个病例需要进一步检验。在感染人数较少的情况下,这种方法可以大幅度削减所需的检测数量。

左图显示了16个样本中只有一个人感染;右图显示了Dorfman方法,将样本四个一组进行组合。第一阶段需要四次检测来寻找阳性组,第二阶段则从阳性组内最多四次检测出病例。最多八次的检测至少减少了一半的检测需求。
Dorfman的研究启发了后人在统计和计算机领域的广泛研究,包括信息论、组合学、压缩感知以及许多相关的研究问题,尤其在个体感染概率的计算上促进了二分法和相关知识的充分应用。时至今日,这一领域已经生发出多个子问题并形成了系统的研究体系。一些算法通过裁剪适用于检测结果可靠的无噪声问题,而另一些算法则针对真实情况中存在误检漏检的噪声问题进行研究。此外还提出了一些适应性策略,基于观察到的测试结果给出候选组(包括Dorfman在内已经提出了针对阳性组内个体进行二次检测);另外一部分则依然应用事先已知的非适应性条件设置来进行处理。
谷歌的研究人员最近提出了一种基于贝叶斯方法的序列群体检测方法,自适应地处理包含检测噪声的情况,通过对于历史测试数据的观测来决定后续需要检测分组,其目标在于尽可能可靠快速地进行群体感染筛查。大规模的仿真实验表明这种方法相对于适应和自适应基线模型可以得到更好的结果,在疾病流行程度较低的情况下更为高效,特别适合于在资源受限的情况下进行大规模筛查,同时也为类似于COVID-19的大流行检测提供有效的快速的可靠检测方法。
非渐进情况下的噪声和自适应群组检测
群组测试策略是一种可以从n个个体中预测携带病原体患者的算法。为了高效实现这一目标,需要提供如何将个体组合成群组的策略。假设实验室每个时间段可以执行k次检测,这一策略将构建出k*n的混合矩阵来定义这些群组。当获取检测结果后,就可以决定哪些样本需要进一步检测,或者区分出阳性和阴性患者。
在这一研究中,研究人员设定了一种符合真实检测情况的算法,检测中包含很多噪声情况(感染样本的阳性检测率低于100%,而非感染样本返回阴性)。
利用贝叶斯优化实验设计
更少检测应对更多人群筛查
研究人员提出了一种侦探式的策略,首先基于已有测试和先验信息来提出多个关于感染和非感染的假设。
(a). 基于这些假设我们的感染侦探将侦查出称为第二波群组的群体来尽可能多的证实或者证伪假设;
(b). 而后进一步重复流程a直到可行的假设足够小,以便识别器可以精确地去除其中的模糊性得到结果。
a. 给定人群数量n时,感染状态是一个长度为n的二进制向量,用0/1来描述非感染/感染者。在确定的完整测试状态下,人群的感染状态是确定的,而群组测试的目的在于用尽可能少的测试来识别出人群的感染状态。在给定感染率和当前测量结果等先验信息后,研究人员认为只有一小部分感染状态假设是合理的。
所以无需在2^n个可能的状态上进行评估(人群数量很大时,状态空间会变得非常非常巨大),而是直接利用序列蒙特卡洛采样器(Sequential Monte Carlo, SMC)在合理的加速上进行采样。虽然需要非常大的计算(GPU上需要运行几分钟),但即使针对较大的样本数量SMC方法也具有可追溯性,算法侦探将生成一个包含上千个相关假设的可拓展列表,可以更好地解释当前的观测结果。
b. 在获得假设的相关表格后,算法侦探将进一步收集额外的证据。如果下一个迭代可以进行k次检测,那么算法策略将会利用贝叶斯优化实验设计计算出k个新群组。如果k=1那么仅仅只有一个新的群组进行下一步检测。这意味着这一组检测结果在不确定性方面具有明显的优势,在当前假设下其返回阳性的概率接近50%。进行分析调查的目的在于最大化信息增益(surprise factor)而不是仅仅保持现有的结果。
为了更为普遍地处理k>1的情况,研究人员利用假设分布于“虚拟群组”的互信息来为surprise factor进行打分。同时计算出在新测试群组情况下利用这些假设得到的AUC(area under the ROC curve)结果。利用贪心算法最大化这两个群组指标GMI_MAX和GAUC_MAX(最大化互信息MI和AUC)。下图显示了采样器和选择器的构造,由实验室测试结果和策略构成。
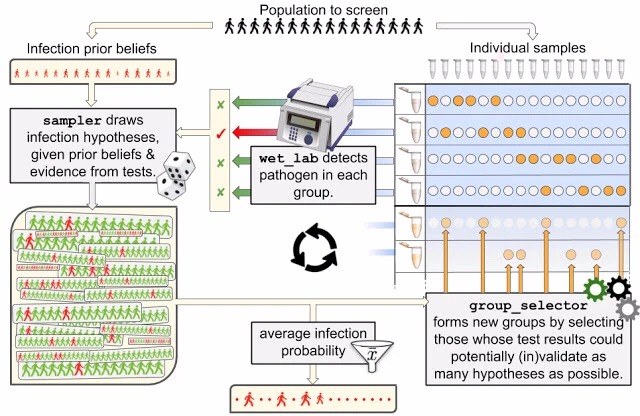
群组测试框架描述了测试环境和测试结果,用于从上千个合理的假设中采样出针对所有个体的感染状态。假设进一步被用于优化过程的群组选择器中来选择出最符合特征结果的假设,从而缩小真实感染状态的搜索范围。确认后群组会进行二次检验来完成闭环。在流程的任意阶段,采样器获取的假设可以平均到每个病人的平均感染概率,基于这些概率可以分析出某个个体是否被感染。
基准测试
研究人员在不同感染率和测试噪声的情况下对两种策略GMIMAX和GAUCMAX进行了测试,下图显示了策略的结果。可以看到在图的右上角这两种策略的灵敏度和准确性都大幅提高。
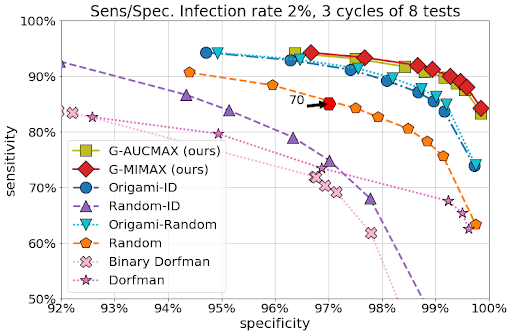
在70个个体构成的群体中进行了5000次模拟,感染率为2%。并根据PCR扩增仪的指标设置了最大群组数量为10,灵敏度和准确率为85%/975。
结论
对人群进行大规模的传染病筛查是非常重要和基础的防疫问题,特别当目前面对COVID-19的情况下更是如此。多年前Dorfman设计的简单算法已经被多个机构广泛采用,而本文提出的算法进一步提升策略的性能。研究人员首次从概率的角度,基于现有的测试结果构建假设的范式,无缝衔接各种有效的先验知识,包括流调或问卷等信息。这使得算法可以更好地筛选出更符合先验信息和目前监测结果的假设。此外这种方法可以充分利用假设构建新的群组来收集额外信息,不断收窄目标状态的范围,以尽可能小的代价获得准确的监测结果。
虽然世界范围内疫情远未结束,但科学和技术为我们提供了更有效的铠甲和武器。
愿世界美好,疫病祛散。
更多技术细节请参看论文,想要仿真的小伙伴可以上手代码把玩:
paper:https://arxiv.org/abs/2004.12508
code:https://github.com/google-research/google-research/tree/master/grouptesting
ref:
group testing:
https://en.wikipedia.org/wiki/Group_testing#History_and_development
Bayesian experimental design:
https://en.wikipedia.org/wiki/Bayesian_experimental_design
pic from:
https://dribbble.com/shots/6998323-Hospital-motion

 友情链接
友情链接