








公众号/ScienceAI(ID:Philosophyai)
编译/绿萝
我们的大脑,一个包裹在骨性头骨内的三磅重的组织,如何从感觉中产生知觉是一个长期存在的谜。大量证据和数十年的持续研究表明,大脑不能像拼拼图一样,简单地组合感官信息来感知周围环境。大脑可以根据进入我们眼睛的光线构建场景,即使传入的信息嘈杂和模糊,这一事实也证明了这一点。
因此,许多神经科学家开始将大脑视为「预测机器」。通过预测处理,大脑使用其对世界的先验知识,对传入的感官信息的原因作出推断或产生假设。这些假设——而不是感官输入本身——会在我们的头脑中产生感知。输入越模糊,对先验知识的依赖就越大。
荷兰 Radboud 大学预测大脑实验室(Predictive Brain Lab)的神经科学家弗洛里斯·德·兰格(Floris de Lange)说:「预测处理框架的美妙之处在于,它具有非常大的(有时批评家可能会说太大)的能力来解释许多不同系统中的许多不同现象。」
然而,越来越多的神经科学证据支持这一想法主要是间接的,并且可以接受其他解释。「如果你研究人类的认知神经科学和神经成像,[有] 很多证据——但超级隐含的、间接的证据,」Radboud 大学的蒂姆·基茨曼(Tim Kietzmann)说,他的研究是机器学习和神经科学的跨学科领域。
因此,研究人员正在转向计算模型来理解和测试预测大脑的想法。计算神经科学家构建了人工神经网络,其设计灵感来自生物神经元的行为,可以学习对传入的信息进行预测。这些模型展示了一些不可思议的能力,似乎模仿了真实大脑的能力。这些模型的一些实验甚至暗示大脑必须进化为预测机器以满足能量限制。
随着计算模型的激增,研究活体动物的神经科学家也越来越相信大脑学会推断感觉输入的原因。虽然大脑如何做到这一点的确切细节仍然模糊不清,但大刀阔斧的描绘正变得越来越清晰。
知觉中的无意识推理
乍一看,预测处理似乎是一种违反直觉的复杂感知机制,但科学家们转向预测处理的历史由来已久。甚至在一千年前,穆斯林阿拉伯天文学家和数学家 Hasan Ibn Al-Haytham 在他的《光学》(Book of Optics)一书中强调了它的一种形式,来解释视觉的各个方面。这个想法在 19 世纪 60 年代获得了力量,当时德国物理学家兼医生赫尔曼·冯·亥姆霍兹 (Hermann von Helmholtz) 认为,大脑会推断其传入的感官输入的外部原因,而不是根据这些输入「自下而上」构建其感知。
Helmholtz 阐述了「无意识推理」的概念来解释双稳态或多稳态感知,其中图像可以以不止一种方式被感知。例如,这发生在众所周知的模糊图像中,我们可以将其视为鸭子或兔子:我们的感知在两个动物图像之间不断翻转。在这种情况下,Helmholtz 断言,由于在视网膜上形成的图像不会改变,因此这种感知必然是关于感官数据原因的自上而下的无意识推理过程的结果。
在 20 世纪,认知心理学家继续建立这样的案例,即感知是一个积极构建的过程,它利用自下而上的感官和自上而下的概念输入。这项努力最终在 1980 年发表了一篇有影响力的论文「Perceptions as Hypotheses」,由已故的理查德·兰顿·格雷戈里 (Richard Langton Gregory)撰写,该论文认为,知觉、错觉本质上是大脑对感官印象原因的错误猜测。与此同时,计算机视觉科学家们在努力使用自下而上的重建,使计算机能够在没有内部「生成」模型供参考的情况下进行观察。

论文地址:https://www.jstor.org/stable/2395424
「试图在没有生成模型的情况下理解数据注定会失败——人们所能做的就是对数据中的模式做出陈述,」伦敦大学计算神经科学家 Karl Friston 说。
但是,尽管预测处理的接受度不断提高,但关于如何在大脑中实现的问题仍然存在。一种流行的模型,称为预测编码,主张大脑中信息处理级别的层次结构。最高级代表最抽象、最高级的知识(例如,对前方阴影中的蛇的感知)。该层通过向下发送信号来预测下一层的神经活动。下层将其实际活动与上面的预测进行比较。如果出现不匹配,该层会生成一个向上流动的错误信号,以便更高层可以更新其内部表示。
这个过程对于每对连续的层同时发生,一直到最底层,它接收实际的感官输入。从世界接收到的信息与预期之间的任何差异都会导致错误信号,并在层次结构上产生涟漪效应。最高层最终更新了它的假设(它毕竟不是一条蛇,只是地上盘绕的绳索)。
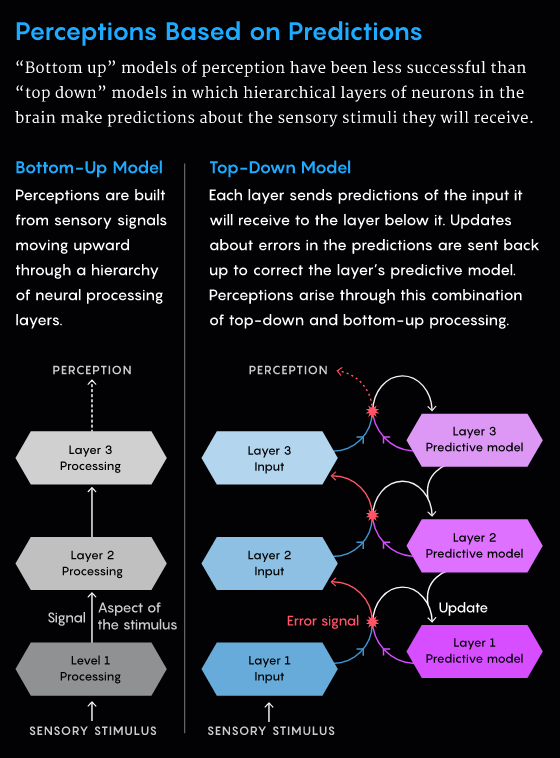
「总的来说,预测编码的想法,特别是当它应用于皮层时,大脑基本上有两个神经元群,」de Lange 说:一个编码当前关于被感知的最佳预测,另一个是在预测中发出错误信号。
1999 年,计算机科学家 Rajesh Rao 和 Dana Ballard(当时分别在索尔克生物研究所和罗彻斯特大学工作)建立了一个强大的预测编码计算模型,该模型具有明确用于预测和纠错的神经元。他们模拟了灵长类大脑视觉处理系统中通路的一部分,该系统由负责识别面部和物体的分层组织区域组成。他们表明该模型可以概括灵长类动物视觉系统的一些不寻常行为。

论文地址:https://www.nature.com/articles/nn0199_79
然而,这项工作是在现代深度神经网络出现之前完成的,现代深度神经网络具有一个输入层、一个输出层和夹在两者之间的多个隐藏层。到 2012 年,神经科学家开始使用深度神经网络来模拟灵长类动物腹侧视觉流。但几乎所有这些模型都是前馈网络,其中信息仅从输入流向输出。「大脑显然不是纯粹的前馈机器,」de Lange 说。「大脑中有很多反馈,大约与前馈 [信号] 一样多。」
因此,神经科学家转向了另一种类型的模型,称为循环神经网络(RNN)。纽约西奈山伊坎医学院的计算神经科学家兼助理教授 Kanaka Rajan 表示,这些特征使它们成为模拟大脑的「理想基质」,他的实验室使用 RNN 来了解大脑功能。RNN 的神经元之间同时具有前馈和反馈连接,并且它们具有独立于输入的持续不断的活动。「在很长一段时间内产生这些动态的能力(基本上是永远),让这些网络能够接受训练的能力,」Rajan 说。
预测是节能的
RNN 引起了哈佛大学的 William Lotter 和他的博士论文导师 David Cox 和 Gabriel Kreiman 的注意。2016 年,该团队展示了一个 RNN,它学会了预测视频序列中的下一帧。他们将其称为 PredNet(「我会因为没有足够的创造力来想出更好的东西而受到责备,」Lotter 说)。该团队按照预测编码的原则将 RNN 设计为四层的层次结构,每一层都预测来自下层的预期输入,在不匹配时,向上发送错误信号。

论文地址:https://arxiv.org/abs/1605.08104
然后,他们用安装在汽车上的摄像头拍摄的城市街道视频训练网络。PredNet 学会了连续预测视频中的下一帧。「我们不知道它是否真的有效,」Lotter 说。「我们试了一下,发现它实际上是在做预测。那太酷了。」
下一步是将 PredNet 连接到神经科学。去年在 《Nature Machine Intelligence》上,Lotter 及其同事报告说,PredNet 展示了猴子大脑中对意外刺激做出反应的行为,包括一些难以在简单的前馈网络中复制的行为。

论文地址:https://www.nature.com/articles/s42256-020-0170-9
「这是一项了不起的工作,」Kietzmann 在谈到 PredNet 时说。但是他、Marcel van Gerven 和他们在 Radboud 的同事追求的是更基本的东西:Rao 和 Ballard 模型和 PredNet 都明确地结合了人工神经元进行预测和纠错,以及导致正确的自上而下预测,以抑制错误神经元的机制。但如果这些没有明确指定呢?「我们想知道是否真的需要所有这些 [烘焙] 架构限制,或者我们是否会采用更简单的方法。」Kietzmann 说。
Kietzmann 和 van Gerven 想到的是,神经交流在能量上是昂贵的(大脑是身体中能量最密集的器官)。因此,节约能源的需要可能会限制生物体中任何进化神经网络的行为。
研究人员决定看看是否有任何预测编码的计算机制可能出现在 RNN 中,这些 RNN 必须使用尽可能少的能量来完成任务。他们认为,他们网络中人工神经元之间的连接强度(也称为权重)可以作为突触传递的代理,这是生物神经元中大部分能量使用的原因。「如果你减少人工单位之间的重量,那就意味着你用更少的能量进行交流,」Kietzmann 说。「我们认为这是最小化突触传递。」

然后,该团队在多个连续数字序列上以升序、环绕顺序训练 RNN:1234567890、3456789012、6789012345 等。每个数字都以 28 x 28 像素图像的形式显示给网络。RNN 学习了一个内部模型,可以从序列中的任何随机位置开始预测下一个数字是什么。但是网络被迫以最小可能的单位之间的权重来做到这一点,类似于生物神经系统中的低水平神经活动。
在这些条件下,RNN 学会了预测序列中的下一个数字。它的一些人工神经元充当「预测单元」,代表预期输入的模型。其他神经元充当「错误单元」,当预测单元尚未学会正确预测下一个数字时,这些神经元最为活跃。当预测单元开始正确时,这些错误单元变得柔和。至关重要的是,网络采用这种架构是因为它被迫最大限度地减少能源使用。「它只是学会了人们通常明确地在系统中建立的那种抑制,」Kietzmann 说。「我们的系统开箱即用,作为紧急事情要做,是节能的。」

论文地址:https://www.biorxiv.org/content/10.1101/2021.02.16.430904v1
结论是,最小化能源使用的神经网络最终会实现某种预测处理——证明生物大脑可能也在做同样的事情。
Rajan 称 Kietzmann 的工作是「一个非常巧妙的例子,说明了自上而下的约束(如能量最小化)如何间接导致特定功能(如预测编码)。」这促使她怀疑 RNN 中特定错误和预测单元的出现,是否可能是由于只有网络边缘的神经元接收输入的意外后果。如果输入分布在整个网络中,「我下意识的猜测是,你不会发现错误单位和预测单位之间的分离,但你仍然会发现预测活动,」她说。
大脑行为的统一框架
尽管这些来自计算研究的见解看起来很有说服力,但最终,只有来自活体大脑的证据才能说服神经科学家相信大脑中的预测处理。为此,麦吉尔大学和魁北克人工智能研究所 Mila 的神经科学家和计算机科学家 Blake Richards 及其同事提出了一些明确的假设,即大脑在学习预测意外事件时应该看到什么。
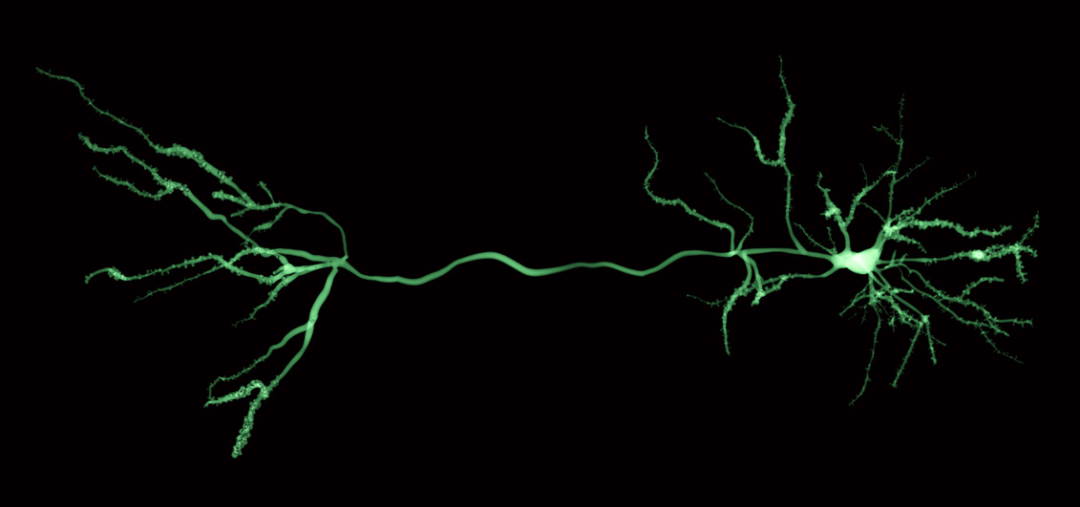
大脑中的金字塔神经元似乎在解剖学上适合预测处理,因为它们可以分别整合来自相邻神经元的「自下而上」信号和来自更远神经元的「自上而下」信号。
为了验证他们的假设,他们求助于西雅图艾伦脑科学研究所的研究人员,他们在老鼠身上进行了实验,同时监测了老鼠大脑的神经活动。特别有趣的是,大脑新皮质中的某些锥体神经元,它们被认为在解剖学上适合预测处理。它们可以接收来自附近神经元的局部自下而上的感觉信号(通过输入到它们的细胞体)和来自更远的神经元(通过它们的顶端树突)的自上而下的预测信号。
向小鼠展示了许多 Gabor 斑块序列,这些斑块由明暗条纹组成。每个序列中的所有四个补丁都具有大致相同的方向,小鼠开始期待这一点。(「一定很无聊,光看这些序列,」Richards 说。)然后研究人员插入了一个意想不到的事件:第四个 Gabor 补丁随机旋转到不同的方向。这些动物最初很惊讶,但随着时间的推移,他们也开始期待惊喜的元素。在此期间,研究人员一直在观察小鼠大脑中的活动。
他们发现,许多神经元对预期和意外刺激的反应不同。至关重要的是,这种差异在测试第一天的局部自下而上的信号中很强,但在第二天和第三天逐渐减弱。在预测处理的背景下,这表明随着刺激变得不那么令人惊讶,新形成的自上而下的期望开始抑制对传入感官信息的反应。
与此同时,顶端树突发生了相反的情况:它们对意外刺激的反应差异随着时间的推移而增加。神经回路似乎正在学习更好地表示令人惊讶事件的特性,以便在下一次做出更好的预测。
Richards 说:「这项研究为新皮层正在发生诸如预测学习或预测编码之类的事情提供了进一步的支持。」
的确,对神经元活动或动物行为的个体观察有时可以用其他一些大脑模型来解释。例如,神经元对相同输入的反应减弱,而不是被解释为错误单元的抑制,可能仅仅是由于适应过程。但随后「你会得到关于不同现象的解释的完整电话簿,」 de Lange 说。
另一方面,预测处理提供了一个统一的框架来一次性解释许多现象,因此它作为一种关于大脑如何工作的理论很有吸引力。「我认为目前的证据非常令人信服,」Richards 说。「实际上,我愿意为这个要求投入大量资金。」
参考内容:https://www.quantamagazine.org/to-be-energy-efficient-brains-predict-their-perceptions-20211115/

 友情链接
友情链接