








在技术上,语音识别的障碍已经被破除,那么下一个需要突破的是什么?
我相信大多数人对语音助手已经不陌生了。很多人也已经和 iOS 中的语音助手 Siri 进行过对话,不论是逗它玩还是真的需要它的帮助。
对 Siri 来说,要听懂你说的是什么并不难,但真的要和它进行一场对话的话,你一定会感到怪怪的。抛开它是否能正确的回答你的问题不说,它回复你的声音就会让你明显感觉到自己并不是在和一个人聊天。
的确,在语音识别这件事上,国内外顶尖的公司都已经能做到95%左右的准确识别率。但在语音生成上,几乎没有公司能让机器人说的话跟人说出来的话一样,即便是一些简单的词组,你也一耳就能听出是机器合成的还是真人播报。
但随着人们越来越多的使用语音交互,如何让电脑的声音听起来更具人性化,已经成为了摆在很多软件公司和程序员面前的大挑战。
据《纽约时报》报道,IBM 曾在世纪之交花了18个月的时间让机器人沃森(Watson)可以说话,但尽管沃森已经非常聪明,它说话的本领仍然很差。因为听起来根本不像人声。

Michael Picheny,IBM 实验室资深经理。图片来自《纽约时报》
现在电脑语音都是用机器合成的(除了部分天气预报和导航提示是完全人工录制),合成最终语音的真人语音数据库通常非常庞大,数据库里有某个单词的真人发音,以及这个单词不同语调的发音,甚至这个单词的部分发音。一位配音者通常需要花至少10个小时才能完成一个语音数据库的录入。
尽管语音数据库已经非常庞大,但是在合成语音的时候,仍然无法做到接近真人发声。其中最大的难点是让合成音带有人类的感情。卡内基梅隆大学语言技术研究院的计算机科学家 Alan Black 告诉《纽约时报》,他们并没有办法告诉语音合成器说,这段话要带有感情的去朗读。
当然,设计者也经常强调他们并不希望用合成语音来骗人说这是真人语音。但他们仍然希望机器和人的语音交互能更加自然,更像人和人之间的交流。
事实上,如果机器发音和真人发音过于接近,会让人感到很不舒服。日本机器人科学家森政弘曾在1970年发表了一篇题为《恐怖谷》的文章,核心就是说,当机器人和人的相似程度过于接近的时候,机器人身上的一点点小瑕疵,都会让人感到不安。
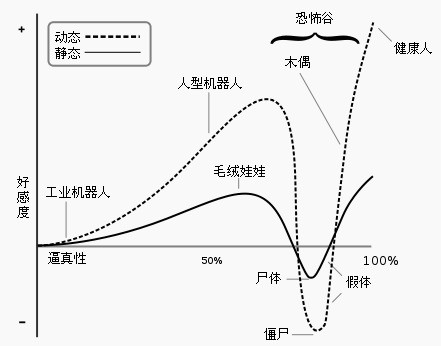
根据森政弘的假设,随着人类物体的拟人程度增加,人类对它的情感反应呈现增-减-增的曲线。恐怖谷就是随着械器人到达“接近人类”的相似度时,人类好感度突然下降至反感的范围。“活动的类人体”比“静止的类人体”变动的幅度更大。图片来自维基百科
ToyTalk 是一家为儿童玩具制作人声的公司,其 CEO Brian Langner 就表示,当机器能做对一些事情的时候,人们会认为它能做对任何事。所以在他的产品里,他会让机器故意犯一点错。毕竟他做的是玩具,犯点错让人们一笑也没什么不好的。
现在的问题是,经过了那么多科学家的努力,在合成语音这件事上,我们还无需担心“恐怖谷”的到来。
为了让沃森能“好好说话”,IBM 招募了25位配音演员,经过大量的实验和调整,他们终于合成了一个听起来让人感到比较舒服的声音——虽然人们还是很明显能听出这不是真人在说话。
如果语音交互要有大发展的话,合成语音必须要让人听起来更舒服。不然的话,这种交互只能说是语音输入,机器执行,人类和机器之间并没有真正的交流。
题图来自 老陈博客
来源:PingWest中文网

 友情链接
友情链接