








公众号/机器之心
Petuum 专栏
作者:Luona Yang、Xiaodan Liang、Eric Xing机器之心编译
参与:Panda
不久之前,机器之心推出了介绍 AI 创业公司 Petuum 在医疗领域的一系列研发成果的文集。而除了医疗领域,Petuum 也在自动驾驶等多个领域启动了研发项目。本系列我们将介绍 Petuum 在自动驾驶研发方向的一系列成果。我们在此以[用于端到端公路驾驶的无监督真实域到虚拟域的域统一]这一开创性论文来开始这一系列。
在获取用于训练自动驾驶系统的数据时,常见的做法是使用对抗生成模型(GAN)根据来自模拟器的虚拟图像生成接近真实的图像。在这篇论文中,Petuum 团队则反其道而行之,直接以真实驾驶图像为起点,利用无监督去除其中对驾驶行为预测无关的细节而使之简化为虚拟域中的精炼规范表征,并据此预测车辆指令,形成一种更加高效准确的全新的训练方案。
引言
开发基于视觉的自动驾驶系统是一个长期以来一直存在的研究问题 [27, 24, 10, 9]。在已经提出来的各种解决方案中,将单个正面相机的图像映射成汽车控制命令的端到端驾驶模型得到了很多研究关注 [5, 33, 18],因为这没有繁琐的特征工程过程。研究者们进行了很多尝试,试图通过利用中间表征来提升单纯的端到端模型的表现(如图 1 所示)。例如,[33] 将语义分割作为次要任务来提升模型的表现,而 [8] 则首次训练了一个检测器来检测周围的车辆,之后再进行驾驶决策。但是,当我们迈向更大的规模时,收集驾驶数据和标注中间表征的成本可能会高得不切实际。
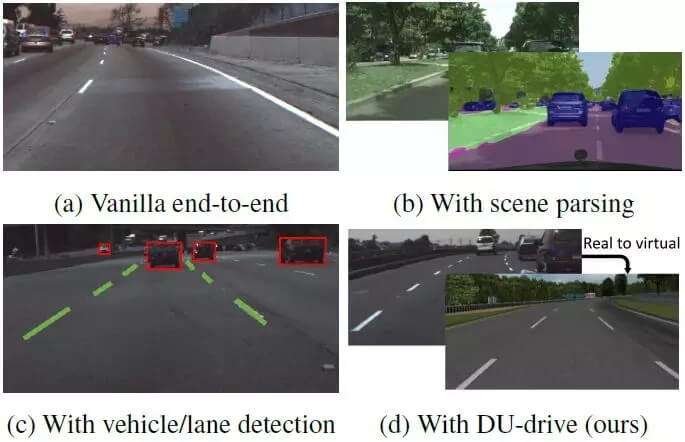
图 1:研究者们已经提出了很多种用于基于视觉的驾驶模型的方法。但单纯的端到端模型 (a) 是不可解释的,且只有次优的表现,另外场景解析 (b) 或目标检测 (c) 还需要成本高昂的有标注数据。我们的方法 (d) 能将来自不同数据集的真实图像统一成它们在没有多余细节的虚拟域中的规范表征,这能够提升车辆指令预测任务的表现。
此外,由于真实世界很复杂,驾驶场景的一般图像和中间表征中包含了很多多余的细节。这些细节中很多都是带来麻烦的信息,它们要么与预测任务无关,要么就根本没帮助。比如,在公路上驾驶的典型人类驾驶员不会根据前一辆车的品牌或道路之外的景观而改变自己的行为。在完美的情况下,模型应该只通过观察人类驾驶数据就能学习到关键的信息,但由于深度神经网络本质上是黑箱的,所以我们难以分析模型是否是根据正确的信号做出预测的。[6] 对神经网络的激活进行了可视化,结果表明其模型不仅学习了车道标记等对驾驶至关重要的信息,而且还学到了非典型车辆类别等不需要的特征。[18] 给出了经过因果过滤(causal filtering)优化的注意图(attention map)结果,其中似乎包含了相当多随机的注意点。我们很难证明学习这样的信息对驾驶有帮助,而且我们相信从驾驶图像中有效地提取最少充分信息(minimal sufficient information)的能力对提升预测任务的表现而言至关重要。
相对而言,来自模拟器的驾驶数据当然能避免这两个问题。一方面,只需简单地设置一个机器人汽车,我们就可以轻松获得无限量的标注了控制信号的驾驶数据。另一方面,我们可以控制该虚拟世界的视觉外观,还能通过最小化多余的细节来构建一个规范的驾驶环境。
这促使我们开发了一个可以有效地将真实驾驶图像变换成它们在虚拟域中的规范表征的系统,从而有助于执行车辆指令预测任务。很多已有的研究工作利用虚拟数据的方式是使用生成对抗网络(GAN)将虚拟图像变换成看起来很真实的图像 [12],同时在辅助目标的帮助下保持标注的完整 [34,7]。我们的方法虽然也是基于 GAN,但却有几方面的不同之处。首先,我们的目的是将真实图像变换成它们在虚拟域中的规范表征,而不是反过来。我们所说的规范表征(canonical representation)是指从背景中分离出了对该预测任务而言最少充分信息的像素级表征。因为任何图像都只能有一个规范表征,所以我们不会在生成过程中引入任何噪声变量。其次,我们不会试图直接保留标注,因为我们不清楚到底是图像中的哪些信号确定了车辆指令。相反,我们提出了一种全新的联合训练方案,可以将对预测而言关键的信息逐渐地提取到生成器中,这还能使训练稳定化以及防止驾驶关键信息的模式崩溃(mode collapse)。
我们的工作有三大全新的贡献。第一,我们引入了一种无监督的真实域到虚拟域统一框架,可以将真实驾驶图像变换成它们在虚拟域中的规范表征,然后可以据此预测车辆指令。第二,我们开发了一种全新的训练方案,该方案不仅能将对预测而言关键的信息逐渐地提取到生成器中,还能选择性地防止 GAN 的模式崩溃。第三,我们给出的实验结果证明了为端到端驾驶任务在虚拟域中使用统一的规范表征的优越性。
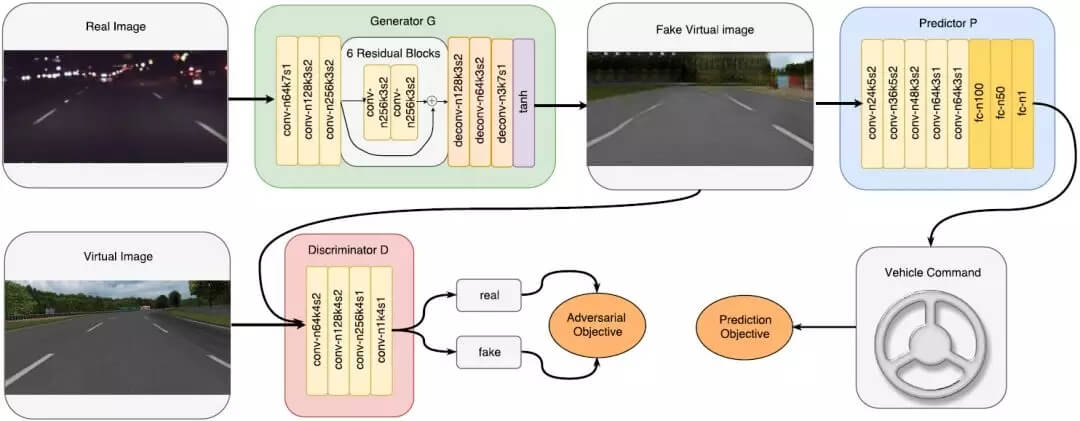
图 2:DU-Drive 的模型架构。其中生成器网络 G 将输入的真实图像变换成假的虚拟图像,然后预测器网络 P 根据这些虚拟图像预测车辆指令。判别器网络 D 的目标是区分假的虚拟图像和真实的虚拟图像。这里的对抗目标和预测目标都能促进生成器 G 生成最有助于预测任务的虚拟表征。为了简单起见,这里省略了实例归一化和每个卷积层/全连接层之后的激活层。(n 表示过滤器的数量,k 表示核大小,s 表示步幅大小)
网络设计和学习目标
DU-Drive 的学习目标。给定真实域中一个标注了车辆指令的驾驶图像数据集和虚拟域中一个相似的数据集,我们的目标是将真实图像变换成其在虚拟域中的规范形式,然后再在变换后的假虚拟图像上运行预测算法。我们的模型与条件 GAN [22] 密切相关,其中生成器和判别器都有一个条件因子(conditional factor)作为输入;但仍有两个细微的差异。其一,在我们的模型中,判别器并不依赖于该条件因子。其二,我们的生成器的输入中不包含任何噪声向量。不同于将简单的虚拟图像映射成信息丰富的真实图像(可能存在多种可行方案),将真实图像映射成仅包含足以完成预测任务的最少充分信息的规范形式的方式应该是唯一的。因此,我们可以移除传统 GAN 中的噪声项,使用确定性的生成网络作为我们的生成器。
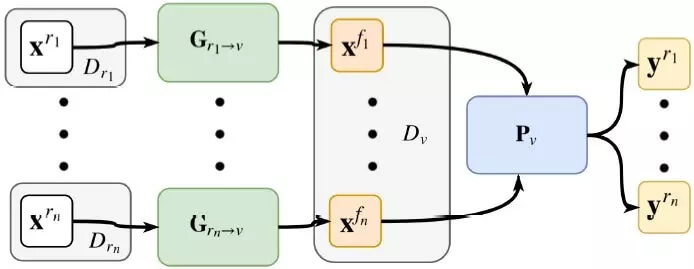
图 3:通过 DU-Drive 实现的域统一(domain unification)。对于每个真实域,都独立地训练一个生成器来将真实图像变换成统一的虚拟域中的假虚拟图像。然后训练一个单张图像到车辆指令的预测器来在多个真实域上进行预测。

图 4:我们的工作所用的样本数据。从上到下:TORCS 模拟器得到的虚拟数据,来自 comma.ai 的真实驾驶数据,来自 Udacity 挑战赛的真实驾驶数据。

图 5:DU-Drive 的图像生成结果。可以看到,对驾驶行为不重要的信息(比如白天/黑夜光照条件和道路边界外的景观)被统一处理了。有意思的是,这些场景中的车辆也被移除了;考虑到我们的实验只是在预测转向角度,所以仔细想想这种处理方式实际上是合理的。另一方面,车道标记等对驾驶而言关键的信息得到了很好的保留。

图 7:条件 GAN 的图像生成结果。背景和前景都遭遇了模式崩溃,车道标记没有得到保留。

图 8:CycleGAN 的图像生成结果。上排:真实的源图像和生成的假虚拟图像。下排:虚拟的源图像和生成的假真实图像。
论文:用于端到端公路驾驶的无监督真实域到虚拟域的域统一(Unsupervised Real-to-Virtual Domain Unification for End-to-End Highway Driving)

论文链接:https://arxiv.org/abs/1801.03458
在基于视觉的自动驾驶的范围内,单纯的端到端模型是不可解释的且只有次优的表现,而居中的感知模型需要分割掩码或检测边界框等额外的中间表征,在我们向更大的规模发展时,其标注成本可能会高得无法实现。
原始图像和现有的中间表征还充满了与车辆指令预测无关的麻烦细节(比如前面车辆的风格或道路之外的景观)。更重要的是,之前的所有研究都无法应对臭名昭著的域转移(domain shift)问题——如果我们要将收集自不同来源的数据融合到一起,那就会极大地阻碍模型的泛化能力。
在这项研究中,我们通过利用收集自驾驶模拟器的虚拟数据而解决了上述限制;我们还提出了 DU-drive,这是一种用于端到端驾驶任务的无监督真实域到虚拟域的域统一框架。它可以将真实驾驶数据变换成其在虚拟域中的规范表征,然后可以据此预测车辆控制指令。我们的框架有几个优点:1)可以将收集自不同源分布的驾驶数据映射进一个统一的域;2)可以利用可以免费获取的有标注的虚拟数据;3)可以学习到驾驶图像中专用于车辆指令预测的可解释的规范表征。我们在两个公开的公路驾驶数据集上进行了大量实验,结果清楚地表明了 DU-drive 的表现优越性和解释能力。

 友情链接
友情链接