








公众号/机器之心
选自arXiv
作者:Peilun Li、Xiaodan Liang、Daoyuan Jia、Eric P. Xing
通过人工方式来标注真实世界数据是一件费时又费力的事。在自动驾驶训练数据的获取上,颇具真实感的视频游戏获取能够提供帮助。但视频游戏的渲染效果往往和真实世界的情况有所差异,Petuum 和 CMU 近日发布的一项研究论文试图解决这一问题;他们提出的一种「形义」(相对于自然语言处理中的「语义」)感知型 Grad-GAN 可以在虚拟到真实的城市场景生成上达到相当逼真和精细的结果。相关研究的代码也已经在 GitHub 上公布:
https://github.com/Peilun-Li/SG-GAN。
受大规模有标注数据集的推动,深度学习模型近来已经在多种任务(比如分类和检测)上实现了非常出色的视觉感知表现 [14,19,20,31]。但是,由于各种场景中的像素方面的标注不足,更细粒度的任务仍然还有很大的提升空间。
高质量的标注往往具有难以实现的难度,需要海量的人力工作才能得到,比如 Cityscapes 数据集 [7] 报告称人工标注单张图像的耗时超过 90 分钟。此外,之前的 domain adaption 研究 [18] 表明,在有限的和有偏差的数据集上学习到的模型往往难以很好地泛化到其它不同领域的数据集上。
缓解这个数据问题的一种可选解决方案是寻找一种自动化的数据生成方法。无需依靠成本高昂的人力劳动来标注真实世界数据,近来计算机图形学领域的研究进展 [23,32,33] 让自动或半自动地从视频游戏中获取图像以及它们对应的形义标签成为了可能,比如《侠盗猎车手 5》(GTA V)——这是一个基于洛杉矶的现实性开放世界游戏。在虚拟世界中,我们可以不受限制地轻松收集各种有标签数据,规模能比人类标注的真实世界数据大几个数量级。
但是,由于常见的严重的域转移问题(domain shift problem [29]),利用真实世界的知识来帮助解决真实世界的感知任务并不是一种容易实现的技术。由于渲染和物体模拟技术的限制,从虚拟世界收集的图像往往会得到与从真实世界收集的图像不一致的分布,如图 1 所示。
因此我们希望构建虚拟世界数据和真实世界数据之间的桥梁,以便将两者共有的形义知识用于感知。之前的域适应方法可以概括为两个方向:最小化源特征分布和目标特征分布之间的差异 [12,15,16,17,18,36];或通过对抗学习 [24,26,27,34,42,44] 或特征组合 [10,11,22,25,37] 明确确保这两个数据分布彼此接近。一方面,对于每个特定任务,这些基于特征的适应方法需要监督源域和目标域,这不是广泛适用的。
另一方面,尽管通过生成对抗网络(GAN)得到了出色的适应表现 [13],但已有的模型只能将源图像的整体颜色和纹理迁移到目标图像,而不会考虑每个形义区域的关键特征(比如道路与汽车),从而得到非常模糊和扭曲的结果。生成对抗网络中有一个鉴别器和一个生成器,其中鉴别器的训练目标是将虚假图像与真实图像区分开,生成器的目标是生成看起来真实的图像以欺骗鉴别器。当生成的图像模糊或扭曲时,细粒度细节的损失会严重阻碍它们对下游的视觉感知任务的促进作用。
图 1:真实世界图像和虚拟世界图像的视觉比较。(a)采样自 Cityscapes 数据集 [7] 的真实世界图像;(b)采样自 GTA-V 数据集 [33] 的虚拟世界图像
我们在本论文中提出了一种全新的形义感知型 GradGAN(SG-GAN:Semantic-aware GradGAN),其目标是为虚拟世界图像中不同的形义区域迁移个性化的风格(比如颜色、纹理,以逼近真实世界分布。我们的 SG-GAN 是一种基于图像的适应方法,不仅能够保留源域中关键的形义和结构信息,而且还能使每个形义区域接近它们对应的真实世界分布。
除了之前的 GAN 中所用的传统对抗目标,我们提出了两个用于实现上述目标的主要贡献。第一,我们引入了一种新的对梯度敏感的目标来优化生成器,这强调了虚拟图像和适应后的图像的形义边界一致性(semantic boundary consistency)。它可以规范化生成器,从而为每个形义区域渲染不同的颜色/纹理,以保持形义边界,这可以缓解常见的模糊问题。
第二,之前的研究成果往往学习的是整张图像的鉴别器,以便验证所有区域的逼真度,这会使原图像中所有像素的颜色/纹理容易坍缩成一种单调模式。我们这里认为每个形义区域的外观分布应该被有目的地区分对待。比如说,在真实世界中的道路区域往往具有粗糙的沥青混凝土纹理,而车辆区域往往很光滑而且反光。不同于最终检查全局特征图的标准鉴别器,我们实现了一种新的形义感知型鉴别器,可以以一种形义方面的方式来评估图像适应的质量。这种可感知形义鉴别器能学习不同的鉴别参数,从而可以根据每个形义标签来检查区域。这就是 SG-GAN 与已有的 GAN 的不同之处,让其成为了可以为不同形义区域个性化纹理渲染并得到具有更精细细节的适应图像的可控架构。
我们在适应 GTA-V 虚拟图像上进行了大量定性和定量实验,结果表明我们的 SG-GAN 可以在不改变形义信息的情况下成功生成逼真的图像。为了进一步证明适应图像的质量,我们使用适应后的图像训练了形义分割模型并在公开的 Cityscapes 数据集上对它们进行了评估。相对于为形义分割使用原始的虚拟数据,适应后的图像带来了显著的表现提升,这很好地表明了我们的 SG-GAN 在可感知形义的虚拟到真实场景适应方面的优越性。
形义感知型 Grad-GAN
我们提出的 SG-GAN 的目标是在保留不同内容的关键形义特征的同时执行虚拟到真实的域适应。SG-GAN 使用了生成对抗网络(GAN),并且相比于传统的 GAN 模型有两大改进,即一种在生成器上的新的软梯度敏感型目标和一种全新的形义感知型鉴别器。
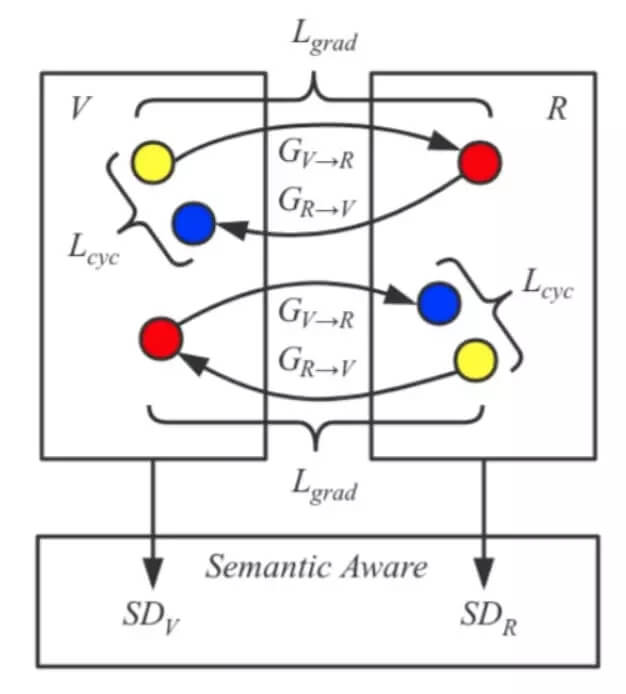
图 2:我们提出的形义感知型 Grad-GAN(SG-GAN)的示意图。V 和 R 框中的黄点分别表示未配对的虚拟世界图像和真实世界图像。两个对称的生成器 G_v→r, G_r→v 的学习目标是根据彼此执行场景适应。除了周期一致性损失(cycle consistency loss [44]),为了确保原始图像及其适应后图像的形义边界是一致的,我们在生成器上加上了一个新的软梯度敏感型目标 L_grad。两个形义感知型鉴别器 SD_v 和 SD_r 是联合进行优化的,以分别检验适应后真实世界图像和虚拟世界图像的逼真度。
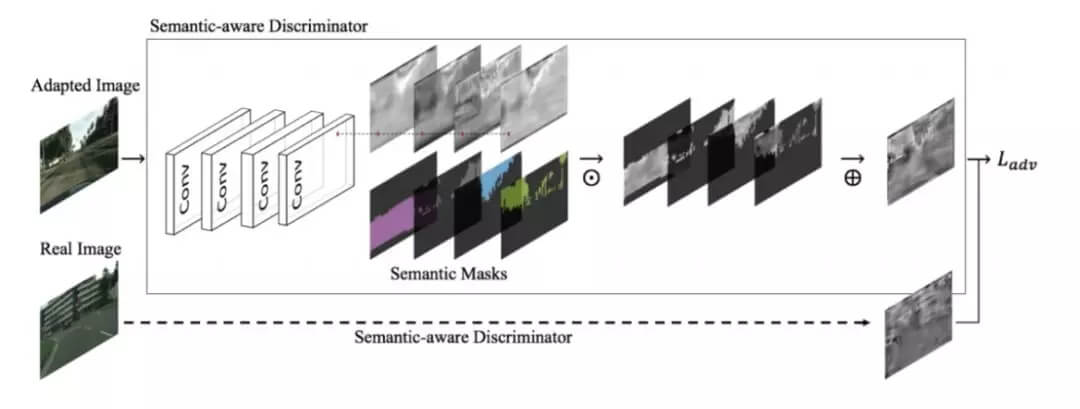
图 3:形义感知型鉴别器示意图。其以真实图像或适应后的图像为输入,然后使用一个对抗目标进行优化。每个输入首先会通过几个卷积层,然后得到的特征图会以元素的方式与形义掩码相乘,然后再求和得到单个通道的输出。这种耦合后的输出会被用于优化对抗损失,如等式 1 所示。图中的 ⊙ 表示元素上的乘法运算,⊕ 表示信道维度上的求和运算。为了更好的可视化,被采样的特征图被重新调整为 [0,255]。
实验

图 4:当前最佳方法与我们方法的变体的视觉比较

图 5:用于展示 L_grad 目标的有效性的放大 4 倍的适应后图像

表 1:在亚马逊 Mechanical Turk(AMT)上的 A/B 测试结果。每个单元格都比较了测试者选出的一种方法适应后的图像比另一种方法适应后的图像更逼真的比例,格式为「方法 A 的比例 – 方法 B 的比例」

图 6:展示形义感知型鉴别器 SD 的效果的有效性比较。(a)是输入的虚拟世界图像;(b)是(e)和(f)之间的绝对差;(c)是(a)和(e)之间的绝对差;(d)是(a)和(f)之间的绝对差;(e)是 SG-GAN-25K 生成的适应图像;(f)是无 SD 变体生成的适应图像;(g)是(e)放大 4 倍的细节;(h)是(f)放大 4 倍的细节。注意,通过比较(b)、(c)、(d),可以看到 SD 有助于为不同的形义类别实现更多色调和纹理变化。(g)和(h)的比较表明了 SD 生成更精细细节的能力,比如远处的交通灯和光滑的天空。

表 2:在 Cityscapes 500 张图像的验证集上得到的形义分割分数(%)比较
论文:用于虚拟到真实城市场景适应的形义感知型 Grad-GAN(Semantic-aware Grad-GAN for Virtual-to-Real Urban Scene Adaption)

论文链接:https://arxiv.org/abs/1801.01726
视觉任务(比如分割)上的最近进展很大程度上取决于通过繁杂的人力劳动获得的大规模真实世界图像标注的可用性。此外,由于在有限和有偏差标注上训练的模型的泛化能力很糟糕,模型的感知表现往往在新场景下会出现显著的下降。在这项工作中,我们采用了迁移知识的方法——自动渲染虚拟世界中的场景标注以助力真实世界的视觉任务。尽管虚拟世界的标注可能有理想的多样性而且是无限的,但虚拟世界和真实世界之间不同的数据分布使得知识迁移颇具难度。因此,我们提出了一种全新的形义感知型 Grad-GAN(SG-GAN)来执行虚拟到真实的域适应,同时它还有能力保留重要的形义信息。除了之前的工作实现的简单的整体颜色/纹理转换之外,SG-GAN 能成功地为每个形义区域个性化外观适应,从而可以保留它们的关键特征,以便进行更好的识别。相对于传统的 GAN,SG-GAN 有两大主要贡献:1)一种用于保留形义边界的软梯度敏感型目标;2)一种用于验证每个形义区域的个性化适应的逼真度的形义感知型鉴别器。定性和定量实验表明了我们的 SG-GAN 在场景适应上相对于之前最佳的 GAN 的优越性。在 Cityscapes 上的进一步形义分割评估表明,使用 SG-GAN 得到的适应后虚拟图像能在原始虚拟数据基础上实现极大的分割表现提升。我们发布了我们的代码:https://github.com/Peilun-Li/SG-GAN。

 友情链接
友情链接