








选自arXiv
作者:Alexandre Attia、Sharone Dayan
公众号/机器之心 编译 参与:Panda、黄小天、蒋思源
模仿学习(Imitation Learning)背后的原理是是通过隐含地给学习器关于这个世界的先验信息,就能执行、学习人类行为。在模仿学习任务中,智能体(agent)为了学习到策略从而尽可能像人类专家那样执行一种行为,它会寻找一种最佳的方式来使用由该专家示范的训练集(输入-输出对)。
当智能体学习人类行为时,虽然我们也需要使用模仿学习,但实时的行为模拟成本会非常高。与之相反,吴恩达提出的学徒学习(Apprenticeship learning)执行的是存粹的贪婪/利用(exploitative)策略,并使用强化学习方法遍历所有的(状态和行为)轨迹(trajectories)来学习近优化策略。
它需要极难的计略(maneuvers),而且几乎不可能从未观察到的状态还原。模仿学习能够处理这些未探索到的状态,所以可为自动驾驶这样的许多任务提供更可靠的通用框架。在此论文中,作者首先介绍了相关的通用框架,然后展示了一些主要的模仿学习算法和保证收敛的方法。最后,作者们在现实应用上实验了 DAgger 方法,并给出了结果。
论文:Global overview of Imitation Learning

论文地址:https://arxiv.org/abs/1801.06503
摘要:模仿学习是学习器尝试模仿专家级行为从而获取最佳表现的一系列任务。近期,该领域提出了数种算法。在此论文中,我们旨在给出这些算法的整体回顾,展示他们的主要特征并在性能和缺点上做出对比。
3. 顶尖算法和收敛保证
从示范中学习(LfD,Learning from Demonstration)是一个从专家给出的轨迹中学习复杂行为的实践框架,即使非常少或者不准确。我们在下面列出并对比了模型学习中最常用到的一些算法,且在自动驾驶汽车上进行实验对比这些模型算法间的不同。下面这些算法的理论证明和直观定理展示在附录部分。
3.1 监督学习
解决模仿学习的首个方法是监督学习。我们有一个由专家给出的训练轨迹集合,其中单个训练轨迹包含观察结果的序列专家行为的序列。监督式模仿学习的背后动机是训练一个分类器基于观察来模仿专家的行为。
这是一种被动的方法,目的是通过被动的观察全部轨迹学习到一种目标策略。监督式模仿学习的目标是在专家的驱动下于所有状态上训练一个策略,而专家只有在求解该目标时才提供信息。此外,我们需要假不同轨迹中的专家行为是独立同分布的。
这种方法的主要问题是它不能从失败中学习。假设该模型在某个时间步骤衍生出最优化的轨迹,那就无法返回到专家看到过的状态了,因此就会生成错误。总的来说,该朴素算法难以泛化到未知场景,下面的这种方法改正了这种问题。
3.2 前馈训练
前馈训练算法是 2012 年由 Ross 和 Bagnell 提出,它在每个时间步 t(t 属于全部时间步 T)上训练一种策略 π_t。即在每个 t 上,选择机器学习策略 π_t 以模仿专家策略 π*。这种迭代性训练在以下算法 1 中有详细描述:

在最糟糕的情况中,我们与经典监督式学习有相同的收敛,但总体讲,收敛是次线性的(sublinear),并且专家策略成功恢复了模型策略的错误。因此,前馈训练算法应该比之前算法表现更好。
但是,前馈训练法的一个主要缺点是它需要迭代所有的 T 周期,其中时间范围 T 可以相当大。因此,假设策略是不稳定的,算法将在实际应用中(T 过大或未定义)变得不切实际。后续的一些算法克服了这一问题。
3.3 基于搜索的结构预测(SEARN)
SEARN 的想法来自 Daumé III et al. (2009) [3],其并没有学习一些全局模型与搜索(一般模型的标准设置),而是简单地学习一个分类器以最优地搜索每一个决策。算法通过在每一步上遵循专家行动开始,迭代地收集示范并利用它们训练新策略。根据之前所有训练策略以及专家行动的混合,它通过采取行动编译了新的 episodes。最后,它慢慢地学习遵循混合策略并停止依赖专家以决定其要采取的行动。
简言之,该算法试图学习一个分类器,引导我们通过搜索空间。它的运作是通过保持当前策略以试图使用它生成新的训练数据,进而学习一个新策略(新分类器)。当学习了一个新分类器之后,我们用旧分类器进行插值。这一迭代如图 2 所示。

然而,这一基于搜索的结构预测可能过于乐观,并在实践中面临挑战,这主要因为其初始化方法不同于最优策略。下面我们将详细描述克服这一问题的其他方法。
3.4 随机混合迭代学习(SMILe)
SMILe 同样由 Ross 和 Bagnell (2010)[2] 提出,以纠正前馈训练算法中的一些困难问题。它是一个基于 SEARN 的随机混合算法,利用其优点可以使实现更加简单,而且与专家的交互要求也较低。它在多次迭代中训练一个随机静态策略,接着利用训练策略的「几何」随机混合。
具体而言,我们从一个完全遵循专家行动的策略π_0 开始。在每次迭代中,我们训练一个策略π_i 以在以前的策略π_i-1 诱导的轨迹下模仿专家。接着,我们将新的训练策略添加到先前的几何折扣因子α(1 − α)^(i−1) 的策略混合中。因此,新的策略π_i 是 i 策略的混合,其中使用专家行动的概率为 (1 − α)^ i。算法 3 描述了 SMILe 算法。

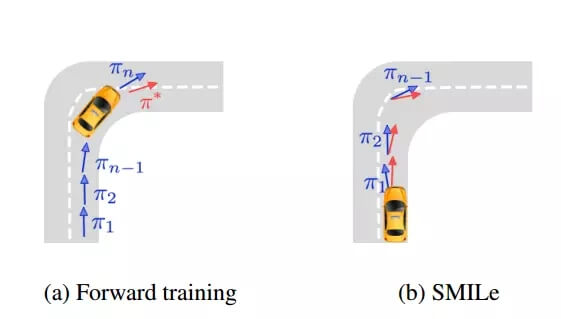
图 1:前馈训练和 SMILe 算法在自动驾驶汽车上的对比
这一方法的主要优势是我们可以随时中断过程,以便不考虑太大或未定义的时间范围。不幸的是,由于其随机政策,模型并不稳定。
3.5 基于归约(Reduction)的主动模拟学习(RAIL)
Ross et al. (2011) [4] 提出的 RAIL 背后的原理是对独立同分布 (i.i.d) 主动学习器 L_a 执行一个包含 T 次调用的序列。我们注意到在 T 次调用全部发出之前就很可能能够很好地找到一个有用的静态策略,这有助于缓解前向循环的缺陷。实际上,这种主动学习器可以在一个时间点范围内提出查询请求,我们预计在之前的迭代中学习到的策略可能能够在整个范围内都取得不俗的表现。
具体而言,RAIL 会以显著不同的方式执行 T 次迭代:在每次迭代中都学习一个新的可以应用于所有时间步骤的静态策略。该模型的 t+1 次迭代会根据之前策略的状态分布学习一个新策略,这个新策略会在预测专家动作上实现较低的误差率。算法 4 给出了 RAIL 算法的描述。

RAIL 是一种理想化的算法,其目的是用于实现理论目标的分析。但是,主要由于在早期迭代中使用了未标注的状态分布(可以与 d_π∗ 有很大的差异),这种算法在实际应用上可能有很多低效的地方。
3.6 数据集聚合(Dagger)
3.6.1 DAgger
Ross 和 Bagnell 在 2010 年提出了 DAgger [5] 算法来解决从示范中学习的问题。DAgger 是一种迭代式的策略训练算法,使用了一种归约到在线(reduction to online)的学习方法。在每次迭代中,我们都在该学习器所遇到过的所有状态上重新训练主要分类器。DAgger 的主要优势是使用了专家(expert)来教学习器如何从过去的错误中恢复过来。这是一种基于 Follow-The-Leader 算法(每一次迭代都是一个在线学习示例)的主动式方法(我们需要读取专家本身)。
我们从完全由专家教授的第一个策略 π_0 开始,运行 π_0,看学习器访问了什么配置。我们生成一个新的数据集,其中包含有关如何从 π_0 的错误中恢复的信息。因为我们希望同时有来自 π_0 和 π_1 的信息,所以我们联合使用起始的仅有专家的轨迹和新生成的轨迹来训练 π_1。我们在每次迭代过程中都重复这一过程。我们选择在验证测试上表现最好的策略。

SEARN [3] 和 DAgger 之间的主要算法差异是每次迭代过程中分类器的学习以及将它们组合成一个策略方面。DAgger 可以组合在所有迭代中获得的训练信号,与之相反,SEARN 仅在第 i 次迭代上训练,即不聚合数据集。SEARN 是第一种实用的方法,之后是 DAgger。DAgger 对复杂问题和简单问题都适用;当收集的数据越多时,它的效果就越好,但仅需少量迭代就有效果。所以对手写识别和自动驾驶等很多应用而言,DAgger 都很有用。
3.6.2 DAgger by coaching
使用 DAgger 时,策略空间可能与学习策略空间相距甚远,这会限制学习能力,也可能无法根据状态推断得到信息。为了防止出现这种情况,HHH Daumé III 等人在 2012 年提出了 DAgger by coaching 算法 [6]。使用这一算法,我们可以执行易于学习的动作,即在学习器的学习能力范围内。当动作太难时,教练(coach)会降低目标然后渐进地教授。
算法 5 描述了 DAgger 算法和 DAgger by coaching 算法。
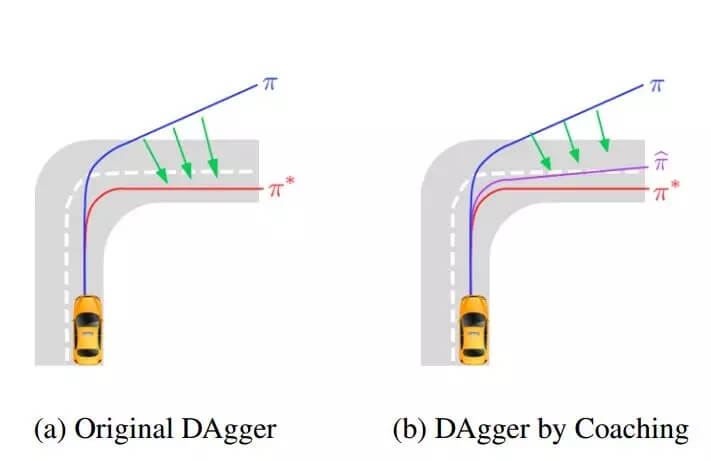
图 2:在自动驾驶汽车任务上的 DAgger 算法图示

图 3:在手写字符识别任务上的 DAgger、SMILe、SEARN 和监督式方法的表现比较。基准只是一个独立预测每个字符的支持向量机(SVM)。α=1(相当于纯策略迭代方法)和 α=0.8 的 SEARN 和 DAgger 在这一任务上表现更好(来自 DAgger 原论文 [5])。
3.7 使用示范的近似策略迭代(APID)
对于之前的算法,我们都假设专家能表现出最优行为并且它们的示范是充分足够的。在真实世界中,这些假设并不总是有效的;为了解决这一艰难问题,我们将专家数据和交互数据结合到了一起(即混合 LfD 和 RL)。因此,APID(2013)[7] 尤其关注专家示范很少或不是最优的情况。这是一种使用近似策略迭代(API)方法正则化过的 LfD,其关键思想是使用专家的建议来定义线性约束,这些线性约束可以引导 API 所执行的优化。
具体来说,我们设置一个 API 的环境,然后使用专家提供的额外信息(尽管这些信息很少或不准确)。V^π 和 Q^π 表示 π 的价值函数和动作-价值函数,V∗ 和 Q∗ 表示最优策略 π∗ 的价值函数和动作-价值函数。我们有一个交互数据集  分别对应一个专家示例集合 ,也就是一个包含 n 个示例的(状态,动作)对样本分别对应于一个包含 m 个示例的(状态、示范动作)对。为了编码专家的次优性,我们为动作-价值最优策略增加了一个变量,以允许偶尔违反约束条件。最后,我们得到一个有约束的优化问题。在这种方法中,我们不必获取确切的 Bellman 算子 T^π,只需要样本即可,由此我们可以使用 Projected Bellman 误差。
分别对应一个专家示例集合 ,也就是一个包含 n 个示例的(状态,动作)对样本分别对应于一个包含 m 个示例的(状态、示范动作)对。为了编码专家的次优性,我们为动作-价值最优策略增加了一个变量,以允许偶尔违反约束条件。最后,我们得到一个有约束的优化问题。在这种方法中,我们不必获取确切的 Bellman 算子 T^π,只需要样本即可,由此我们可以使用 Projected Bellman 误差。
3.8 聚合值以进行模拟(AggreVaTe)
Ross 和 Bagnell (2014) [8] 提出的 AggreVaTe 是 DAgger 算法的一种扩展,可以学习选择动作以最小化专家的 cost-to-go(总成本),而不是最小化模拟其动作的 0-1 分类损失。第一次迭代中,我们通过观察执行该任务的专家来被动地收集数据。在每个轨迹中,在一个一致的随机时间 t,我们探索状态 s 中的动作 a,并观察执行该动作后专家的 cost-to-go Q。
我们使用表示在状态 s 执行动作 a 的期望未来 cost-to-go,之后再执行 t-1 个步骤的策略 π。
和 DAgger 算法完全一样,AggreVaTe 通过与学习器交互来收集数据,方式如下:
下图是对此算法的完整描述:


 友情链接
友情链接