








公众号/AI 科技大本营
翻译 | AI 科技大本营
参与 | shawn
编辑 | Donna
近期,微软(Microsoft)和阿里巴巴(Alibaba)先后宣布,其人工智能系统在一项阅读理解测试上打败了人类。他们进行的是基于“标准问题回答数据集”(Stanford Question Answering Dataset ,SQuAD)的测试,用于回答维基百科的问题。
这一消息再度引起人们关于“ AI 抢走人类工作”的担忧。AI 系统不仅可以识别图像或音频,还可以快速阅读文本并回答相关问题,准确度已经达到人类水准。

不过,这些智能系统并不总是那么“聪明”。开发深度学习网络和其他 AI 系统的专家发现,一旦尝试检验系统是否拥有真正的认知能力,他们创造的系统几乎全线溃败。例如,在自动驾驶汽车还没有装上压力检测软件之前,汽车完全无法避免一些严重的失误。
据来自 MIT 的研究团队 LabSix 的最新发现,研究人员只需略动“手脚”,就可以让一个基于深度学习的图像识别系统“失明”,比如将人当成狗,或者将乌龟认作步枪。
论文链接:
https://arxiv.org/pdf/1712.07113.pdf
https://arxiv.org/pdf/1707.07397.pdf
团队成员 Anish Athalye 说:“在某些领域,神经网络拥有超越人类的能力。但是奇怪的是,我们仍然可以轻易地骗过它们。”
另外,谷歌的 AI 研究团队——谷歌大脑(Google Brain Team)在去年12月发表的一篇论文中,描述了另一种可以使系统将香蕉识别为烤面包机的方法。
论文链接:https://arxiv.org/abs/1712.09665
▌两种让机器“犯错”的方法
LabSix 的方法是用算法轻微修改图像中每个像素的颜色和亮度。虽然这些修改并不明显,但是却可以使系统将图像中的内容误认为是另一种完全不同的东西。
Athalye 表示,伪装对图像的修改是为了“使其更像是现实中的攻击” 。
“如果你在现实生活中看到有人在路上安了一个让人产生幻觉的路标,你可能会认为那边有问题,然后你会进行调查。更可怕的情况是,你认为你看到的是限速标志,但你的自动驾驶汽车却认为不是。”
谷歌大脑团队则采用了另一种方法。他们创造出了一种可以迷惑深度学习系统并让其无法注意其他对象的特殊图像——对抗图像(adversarial patch)。相比 LabSix 修改像素的方法,这种技术几乎适用于任何场景。
“由于对抗图像只能控制其所处的小圆圈中的像素,因此欺骗分类器的最佳方法是让对抗图像变得非常醒目。传统的对抗攻击是小幅修改某一张图像中的所有像素。而我们的方法是大幅修改对抗图像中的少数几个像素。”谷歌员工 Tom Brown 在一封电子邮件中写道。
对于烤面包机来说,其对抗图像必须可以从其他图像中凸显出来,而不是与其他图像融合在一起。
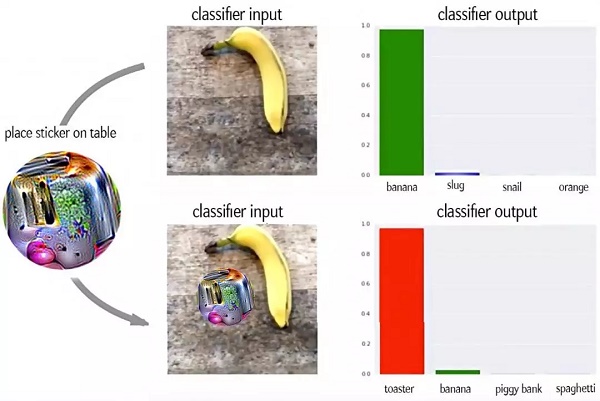
在实验中,研究人员将对抗图像(adversarial patch)——看上去像是可以引起幻觉的烤面包机——放在香蕉图像旁,谷歌图像识别系统将图像中的香蕉误认为是烤面包机。(Adversarial Patch, 作者:Tom Brown 等人, arXiv:1712.09665v1)
为了适应实验室外的环境,对抗图像还必须能够快速适应实际环境中的视觉干扰。
如果用先前一种方式,改变修改过后的图像的方向或亮度,对抗图像方法会变得完全不起作用。如果让系统“从正面看”修改后的猫的图像,它会将其识别为鳄梨酱;如果将图像旋转一些角度,系统又可以再次识别出猫。
相比之下,无论使用任何亮度或任何方向,谷歌的烤面包机对抗图像都可以骗过系统。“创造这种对抗图像难度更高,因为它必须在很多不同的模拟场景中训练对抗图像,找出一个可以适用于所有场景的图像。” Brown 写道。
▌仍然无法理解图像的 AI
Athalye 和 Brown 进行的这项研究的目的都是为了找出人工智能机器识别目前存在的缺陷。Athalye 猜想,对抗攻击可能会让自动驾驶汽车忽视停车标志,也可能让炸弹的X射线图骗过机场包裹检查系统。
其实,这两项研究体现了机器识别的一个更严重的问题,那就是:它可以识别物体,但是无法理解这个物体是什么,有什么用处。
纽约大学心理学教授 Gary Marcus 长期以深度学习领域“打假者”的身份活跃在众人视野中。在 AI 系统阅读理解测试表现出色的新闻出来之后,他就在推特上进行了公开的批评:
“机器在测试中表现出的能力和真正的理解完全搭不上边。SQuAD 测试表明机器可以标出文本中的相关内容,但是它无法理解这些内容。”
Marcus 还表示,机器被骗是因为“它不能全面地理解环境”。它也 “无法真正理解事物之间的因果关系,以及事物之间的相互作用及个中缘由”。
“我们需要开发出一种不同的 AI 架构,它不仅可以进行模式识别,还要拥有解释能力。”
Marcus 建议,研究人员应该从认知心理学中获取灵感,开发拥有更深层次理解能力的软件,而不是用成百上千的示例来训练 AI 系统。
不过,对于我们人类,这种 AI 系统没有出现前,我们还是安全的——至少暂时是安全的。
作者 | Dana Smith
原文| https://www.scientificamerican.com/article/how-to-hack-an-intelligent-machine/

 友情链接
友情链接