








公众号/小象
源 | kdnuggets 译 | 吕旭光
最近学完了一门很有用的深度学习课程,我就一直想整理出他贯穿课程的一些精髓。
其中很棒的一条是探索机器学习算法/模型的一般性方法。
整体上,我把它总结在了下面的流程图里面。
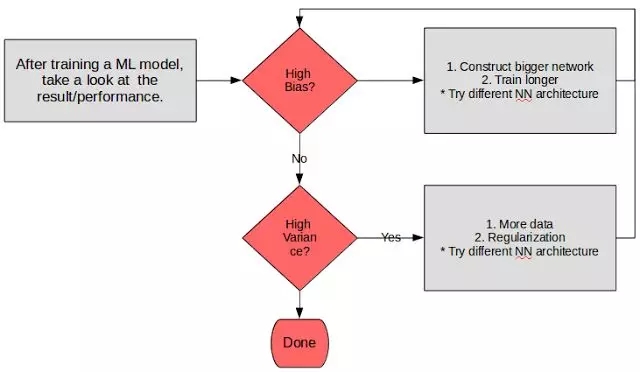
深度学习的基本方法
什么是偏差(bias)和方差(variance)?下面这个图解很具有代表性,相信我们中的大多数人都能看懂。
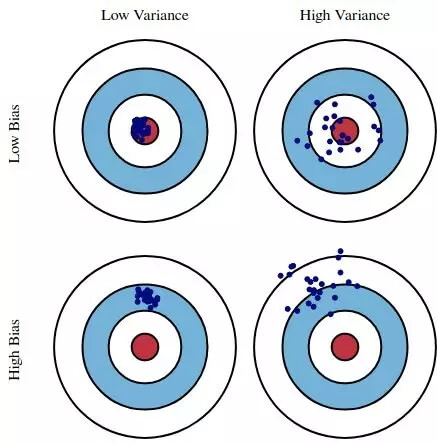
图解偏差和方差
我们怎么知道训练结果具有高偏差(highbias)或者高方差(high variance)?
要判断训练结果是否有高偏差,我们可以看一下模型在训练集(training set)上的性能表现(performance)。训练集上性能较差标志着模型拟合效果不佳,表明我们可以尝试使用一个更大的网络来更好地拟合模型。
对于高方差的情况,我们可以看一下验证集(validationset)(吴恩达称作dev set)上的性能。验证集的性能较差(而在训练集上表现尚佳)标志着我们的模型具有高方差,在处理验证集的时候就会不够灵活。这表示两种可能—-要么就是我们的验证准备不充分(这种情况可能是类不平衡),要么就是我们的模型泛化性不够好。因此修正这个问题的做法是加入更多的数据并使用正则化技术来让我们的模型更健壮。
回过头看,我当时学习机器学习的时候,始终相信偏差和方差是一种权衡—-你可以提高两者中的一个,但必须以牺牲另一个为代价。
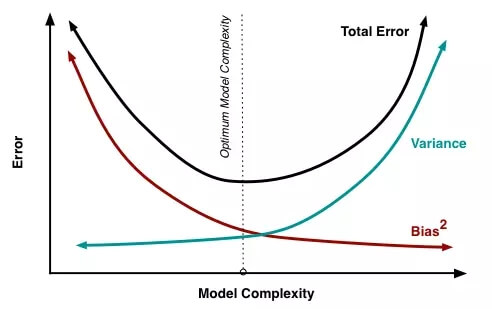
偏差和方差影响着总的误差
然而在大数据和深度学习时代,吴恩达提出:权衡可以成为过去式了。
为什么这么说?
借助深度学习,我们有了一个能拟合各种数据的系统,方法是通过构建一个足够大的网络来学习数据。这就是大数据的神奇之处—-因为我们需要足够多的数据才能训练我们的模型。事实上,在这种情况下,可以看到深度学习能超越任何机器学习模型
各种模型的准确性vs数据量对比
因此,如果模型在训练集上准确性较低,我们可以给神经网络增加更多节点。
如果因为高方差导致模型在验证集上的性能不佳,则要添加更多数据。
不过需要强调的一点是我们的模型也需要适当的正则化,并使上述假设成立。
这是否意味着深度学习是所有“预测问题”的万能钥匙?我将论证:或许不是。
首先也是最重要的,我们来看第一项被提议的措施—-构建更大的网络。大的网络需要更强的算力,包括使用多个GPU来加快处理速度。据我所知,没有太多企业明智到真的会购买GPU作为它们的“分析解决方案栈”的一部分(多数企业可能会把钱花在购买超大内存的大型服务器上面)。那么构建模型便成问题了,因为会花很久的时间才能训练完一个模型(更不用说重新训练(fine tune)所需的多次迭代了)。
其次,我们来谈谈大数据。
对于想做机器学习的数据科学家来说,仅仅把大数据放在数据湖里面是不够的—-还需要将其分类。
数据分类本身就是一个很大的问题,这催生了许多提供手工数据分类解决方案的公司。尽管如此,它们也只能分类这么多,并且我怀疑是否真的会达到“大数据”的级别。
所以对我来说这时候决策树、SVM等算法可以派上用场了。事实上,我很自信地说,你可能不需要在大多数企业/公司/中小企业面临的大多数问题上使用深度学习(当然,除非你工作的职位会处理大量数据,如图像处理、广告和文本处理等领域)。
回到我之前关于不购买GPU的公司的观点——我觉得这跟它们明不明智没关系——只是因为完全没必要解决这些问题(坦白讲,现在我想了想,内存大了也会更有意义)。差不多就是这样:特定的问题用特定的设备解决(并且能够向财务部门合理解释设备的成本——但这是另一回事了)。
想了解本文中提到的主题的更多详细信息,请查看下面的参考资料:
Understanding the Bias Variance Tradeoff: http://scott.fortmann-roe.com/docs/BiasVariance.html
DeepLearning.ai: Basic Recipe For Machine Learning video:https://www.youtube.com/watch?v=C1N_PDHuJ6Q&index=3&list=PLkDaE6sCZn6Hn0vK8co82zjQtt3T2Nkqc

 友情链接
友情链接