








选自Berkeley Lab
机器之心编译
参与:李诗萌、刘晓坤
机器学习模型通常依赖于大量训练数据,所以在很多领域中难以施展拳脚。近日,伯克利实验室 CAMERA 的研究人员开发了非常高效的卷积神经网络,可以从有限的训练数据中分析实验科学图像,精确地执行图像分割和图像去噪等,并有望扩展到其它实验研究领域中。
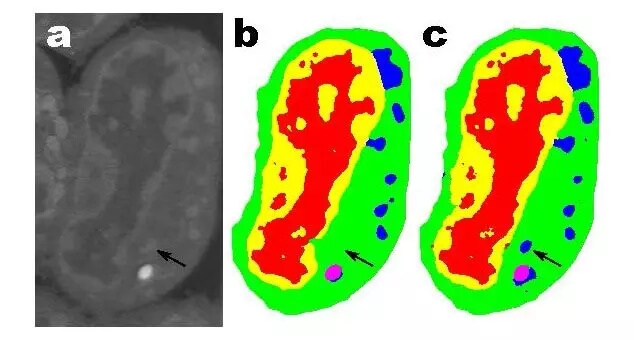
小鼠淋巴母细胞的切片。(a)原始图像;(b)人工切割得到的切片;(c)100 层的 MS-D 网络的输出(数据来自 A.Ekman, C. Larabell, National Center for X-ray Tomography)
能源部劳伦斯伯克利国家实验室(Berkeley Lab)的数学家们开发了一种针对实验性成像数据的新的机器学习方法。这种新方法不像典型的机器学习方法一样需要数万或数十万张图像用于训练——它可以在使用更少的图像的同时,更快地进行学习。
伯克利实验室的 CAMERA(能源高级数学研究与应用中心,Center for Advanced Mathematics for Energy Research Applications)的 Daniël Pelt 和 James Sethian 开发了一种新算法,他们将这种算法称为「多尺度密集卷积神经网络」(MS-D,Mixed-Scale Dense Convolution Neural Network)。这种新方法与传统方法相比,需要的参数更少,收敛得也更快,而且可以基于相当小的训练集进行「学习」。这种方法已用于从细胞图像中提取生物结构,还打算为多个研究领域提供新的数据分析的计算工具。
随着实验设备可以更快地产生更高分辨率的图像,科学家们可能难以通过人工方式对产生数据进行管理和分析。2014 年,Sethian 在伯克利实验室成立了 CAMERA。CAMERA 是一个集成了许多交叉学科的中心,成立目的在于开发美国能源部科学用户设备办公室的实验探索所需的基础数学方法。CAMERA 是该实验室计算研究部门的一部分。
Sethian 同时也是 UC Berkeley 的数学教授,他认为:「在科学应用中,需要大量人力对实验图像进行注释和标记——可能需要几周才能得到一些批注过的图像。我们的目标是开发一项可以通过很小的数据集进行学习的新技术。」
该算法的相关论文发表于 2017 年 12 月 26 日的美国国家科学院院刊上(见文末)。
Pelt 是荷兰数学与计算科学研究所下属的计算成像小组的成员,他介绍说:「这项突破源于我们意识到,不同图像尺度的特征提取的缩放运算,可以用能处理多个尺度的数学卷积的一层所代替。」
为了得到更广泛的应用,Olivia Jain 和 Simon Mo 领导的伯克利团队建立了门户网站「图像数据标记引擎(SlideCAM,Segmenting Labeled Image Data Engine)」
该算法还可用于理解生物细胞内部结构,这一应用也非常有前景。使用 Pelt 和 Sethian 的 MS-D 方法,仅需要七个细胞的数据,就可确定该细胞的内部结构。
国家 X 射线断层成像中心主任、加利福尼亚大学旧金山医学院的教授 Carolyn Larabell 说:「我们实验室中的主要工作是了解细胞的形态结构是如何影响和控制细胞行为的。我们花费无数小时手动分割细胞,以提取细胞结构并识别细胞间的差异,如识别健康细胞和病变细胞间的差异。新算法可能彻底改变我们对疾病的认知能力,而这种算法也是绘制人类细胞图谱的主要工具,绘制人类细胞图谱是扎克伯格和他的夫人赞助的一项全球合作项目,旨在绘制出健康人体中所有的细胞。」
国家 X 射线断层成像中心位于 ALS(Advanced Light Source,先进光源实验室),伯克利实验室的美国能源部科学用户设备办公室。
从更少数据中获得更多科学
图像无处不在。智能手机和传感器已经产生了大量的图片,这些图片中已经有很多标明了图片内容的相关信息。通过庞大的交叉参考图像的数据库,卷积神经网络和其他机器学习算法已经彻底改变了我们快速识别自然图像的能力(类似于曾经见过和分类过的图像)。
这些方法需要数以百万标记过的图像数据,需要使用超级计算机花费大量的时间进行训练,还需要调整一系列隐藏的内部参数进行「学习」。但是如果没有那么多标记过的图像呢?在许多领域,想要这样的数据集都是一个奢侈的愿望。生物学家记录下细胞图像,手动标记出细胞的边界和结构:对他们而言,为得到一个完整独立的细胞的三维结构而花费好几周是一件稀松平常的事情。材料学家利用断层重建技术对岩石和材料进行对比,手动对不同区域进行标记,辨认出裂缝、断口和空隙。不同但重要的结构间的差异往往都会非常小,而数据中的噪声会将特征掩饰起来,并会使最好的算法以及人类产生混淆。
对于传统的机器学习方法而言,这些珍贵的手工标记的图像远远不够。为了迎接这一挑战,CAMERA 的数学家们用非常有限的数据解决了这一问题。为了用更低的成本获得更高的收益,他们的目标是建立一组高效的数学「算符」,可以大规模减少参数数量。这些数学算符可能会与关键的约束条件结合,以帮助计算机对图像进行识别,例如要求形状和模式在科学上合理。
多尺度密集卷积神经网络
机器学习在图像问题上的应用大多使用的是深层卷积神经网络(DCNNs,deep convolutional neural networks)。在 DCNN 中,输入图和中间图在许多连续的层中进行卷积,使得网络可以学到高度非线性特征。为了在困难的图像处理问题中得到精确的结果,DCNN 通常会依赖一些其他操作,这些操作包括但不限于对图像进行缩放以在不同尺度上提取特征。为了训练更深层更强大的网络,通常会需要添加更多的层类型和连接。最终,DCNN 会使用大量的中间图和可训练的参数(一般会超过一亿)来解决复杂的问题。
相反,新的「MS-D」网络架构避免了这些复杂的问题。它用扩张卷积替代缩放操作以捕捉不同空间范围的特征,在单个层中执行多个尺度的特征提取运算,并将所有的中间图密集地连接起来。新算法只需要很少的中间图和参数就能得到精准的结果,既不需要调整超参数也无需额外的层和连接进行训练。
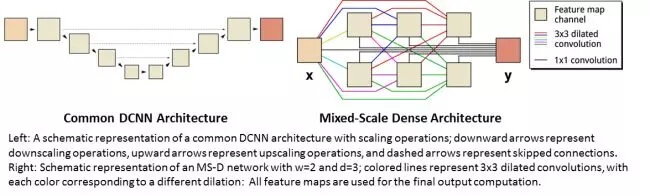
左图:一般的 DCNN 架构。具有缩放操作的普通 DCNN 架构的简图;向下的箭头代表缩小操作,向上的箭头代表放大操作,短箭头代表跳过连接。右图:MS-D 架构。W = 2、d = 3 的 MS-D 网络的草图。带颜色的线表示 3*3 的扩张卷积,每一个颜色都代表不同的扩张操作;所有的特征映射都用于最终的计算输出。
从低分辨率数据中获得高精确度的结果
另一项挑战在于如何从低分辨率的输入产生高分辨率的输出。任何一个试图将一张小照片放大的人都会发现,随着照片越来越大,图片会变的越来越模糊,因此要完成这一挑战听起来几乎是不可能的。但是用 MS-D 网络处理少量的训练图像确实可以取得一些实际的进展。例如,对纤维增强的微型复合材料的层析重建过程进行降噪。在文献中提到的实验,使用 1024 个 x 射线投影重建的图像得到的图像噪声相对较低。再使用 128 个投影重建,来获得同一个对象的噪声图像。训练的输入是有噪声的图像,在训练中将无噪声的图像作为目标输出。经过训练的网络可以高效地使用有噪声的输入重建高分辨率的输出图。

纤维增强的微星复合材料的断层图,使用 1024 个投影重建得到(a), 使用 128 个投影重建得到(b)。用(b)作为 MS-D 网络的输入得到的输出是(c)。每张图红色方框标出的小区域放大后呈现在每幅图的右下角。
新的应用
Pelt 和 Sethian 正在将他们的方法应用于许多新的领域,例如对来自同步加速器光源的图像进行快速实时的分析,以及生物领域的重建问题,例如细胞和大脑的映射。
Pelt 认为:「这些新方法都很令人振奋,因为它们让机器学习解决更广泛的成像问题成为可能。通过减少需要的训练图的数量以及增加可处理图像的尺寸,这个新的网络架构可在许多研究领域解决更重要的问题。」
劳伦斯伯克利国家实验室致力于通过推进可持续能源、保护人类健康、创造新材料以及揭示宇宙起源与命运,解决世界面临最紧迫的问题。成立于 1931 年的伯克利实验室已获得 13 项诺贝尔奖。实验室由加利福尼亚大学管理,由美国能源部科学办公室负责。
论文:A mixed-scale dense convolutional neural network for image analysis(多尺度密集卷积神经网络用于图像分析)

论文链接:http://docs.wixstatic.com/ugd/cc66e4_bb1cd44c5f354517bb3f7b8c1db45cc4.pdf
摘要:在最近的工作中,深度卷积神经网络已成功解决了许多图像处理问题。当下使用的网络架构通常会在标准架构中添加额外的操作和连接,以训练更深层的网络。为了在实际应用中得到更高的准确率,就需要更多的可训练参数。在此,我们介绍的网络架构,是在不同的图像尺度中通过扩张卷积以捕捉特征,并将所有特征图密集连接。新架构可以在使用少量参数和使用一组操作的前提下,提高结果的准确率,使得网络更易在实际中实施、训练和应用,且可适用于不同的问题。我们在几个分割问题中对现有架构和新架构进行了比较,结果表明本文提出的架构可以在使用更少参数、更大程度地避免与训练数据过拟合的情况下,获得准确率更高的结果。
原文链接:http://newscenter.lbl.gov/2018/02/21/new-berkeley-lab-algorithms-create-minimalist-machine-learning-that-analyzes-images-from-very-little-information/

 友情链接
友情链接