








公众号:将门创投
本文经授权转载自SigAI

什么是机器学习?
人工智能的再次兴起让机器学习(Machine Learning)这个名词进入了公众的视野,它成为当前解决很多人工智能问题的核心基石。
机器学习是什么?
如果只用一句话解释这个概念,最简单直观的答案是:机器学习用计算机程序模拟人的学习能力,从实际例子中学习得到知识和经验。
机器学习是人工智能的一个分支,也是人工智能的一种实现方法。它从样本数据中学习得到知识和规律,然后用于实际的推断和决策。它和普通程序的一个显著区别是需要样本数据,是一种数据驱动的方法。
人的绝大部分智能是通过后天训练与学习得到的,而不是天生具有的。新生儿刚出生的时候没有视觉和听觉认知能力,在成长的过程中宝宝从外界环境不断得到信息,对大脑形成刺激,从而建立起认知的能力。要给孩子建立“苹果”、“香蕉”、“熊猫”这样的抽象概念,我们需要给他/她看很多苹果、香蕉的实例或者图片,并反复的告诉他/她这些水果的名字。
经过长期训练之后,终于在孩子的大脑中形成了“苹果”、“香蕉”这些抽象概念和知识,以后他/她就可以将这些概念运用于眼睛看到的世界。
机器学习采用了类似的思路。如果我们要让人工智能程序具有识别图像的能力,首先要收集大量的样本图像,并标明这些图像的类别(这称为样本标注,就像告诉孩子这是一个苹果),是香蕉、苹果,或者其他物体。然后送给算法进行学习(这称为训练),训练完成之后得到一个模型,这个模型是从这些样本中总结归纳得到的知识。接下来,我们就可以用这个模型来对新的图像进行识别了。这种做法代表了机器学习中一类典型的算法,称为有监督的学习。除此之外,还有无监督学习、半监督学习、强化学习等其他类型的算法。
机器学习并不是人工智能一开始就采用的方法。人工智能的发展经历了逻辑推理,知识工程,机器学习三个阶段。
第一阶段的重点是逻辑推理,例如数学定理的证明。这类方法采用符号逻辑来模拟人的智能。
第二阶段的代表是专家系统,这类方法为各个领域的问题建立专家知识库,利用这些知识来完成推理和决策。如果要让人工智能做疾病诊断,那就要把医生的诊断知识建成一个库,然后用这些知识对病人进行判断。
把知识总结出来告诉计算机程序有时候非常困难,例如要告诉计算机怎么识别图像和声音。假设我们要让程序判断下面的图像是否为猫:
判断图像是否为猫的规则该怎么描述?最笨的方法是暴力枚举,即为每张可能的图像对应一个结果(是猫,不是猫),根据这个对应规则进行判定。对于高度和宽度都为256像素的黑白图像,如果每个像素值的值是0-255之间的整数,根据高中学习的排列组合中的乘法原理,所有可能的图像数量为:
这是一个天文数字,以现在计算机的计算和存储能力是无法实现的。事实上我们自己也无法精确的为判断看到的一个物体是否为猫建立一个模型,这就是所谓的只可意会不可言传,但这不妨碍我们能识别猫。
人工知识存在的另一个问题是不具有通用性,可扩展性差。对每个具体问题都要建立起规则和知识库,实现成本非常高。还是以图像识别为例,我们即使建立了怎样判断图像是否为猫的规则,但这种规则不能判断图像是否为狗,因此我们需要为狗也建立一种规则。
授“人”以鱼不如授“人”以渔
与其总结好知识告诉人工智能,还不如让人工智能自己去学习知识。要识别猫的图像,可以采集大量的图像样本,其中一类样本图像为猫,另外的不是猫。然后把这些标明了类别的图像送入机器学习程序中进行训练。训练完成之后得到一个模型,之后就可以根据这个模型来判断图像是不是猫了。对声音识别和其他很多问题也可以用这样的方法。在这里,判断图像是否为猫的模型是机器学习程序自己建立起来的,而不是人工设定的。显然这种方法具有通用性,如果我们把训练样本换成狗的图像,就可以识别狗了。
从图灵奖看机器学习
ACM(美国计算机协会)图灵奖是计算机领域的诺贝尔奖,是计算机科学与工业发展史的缩影。获奖的领域都是计算机科学和工程的重点方向,如操作系统,CPU,网络,数据库,编译器等。截止2017年,人工智能一共获得了6次图灵奖,是获奖最多的领域之一,这6次分别是:
2010 Leslie Valiant(概率图模型)
2010 Leslie Valiant(PAC理论)
1994 Edward Feigenbaum和Raj Reddy
1975 Allen Newell和Herbert A. Simon
1971 John McCarthy
1969 Marvin Minsky
最近两次获奖都是机器学习领域的成果,这也凸显了机器学习当前在人工智能领域的地位。
虽然机器学习这一名词以及其中某些零碎的方法可以追溯到1958年[1]甚至更早,但真正作为一门独立的学科要从1980年算起,在这一年诞生了第一届机器学习的学术会议和期刊。到目前为止,机器学习的发展经历了3个阶段:
1980年代是正式成形期,尚不具备影响力。
1990-2010年代是蓬勃发展期,诞生了众多的理论和算法,真正走向了实用。
2012年之后是深度学习时期,深度学习技术诞生并急速发展,较好的解决了现阶段AI的一些重点问题,并带来了产业界的快速发展。
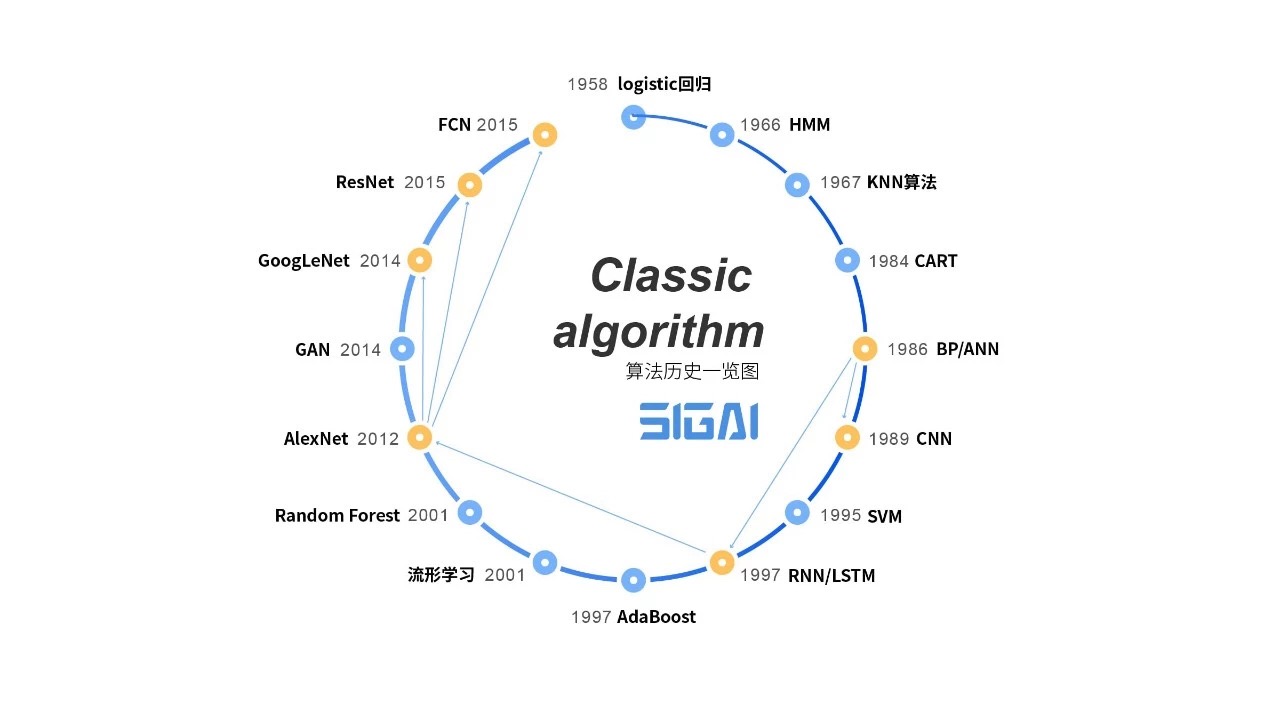
上图展示了过去近40年里机器学习领域诞生的主要算法(重点是有监督学习)
1980s:登上历史舞台
1980年机器学习作为一支独立的力量登上了历史舞台。在这之后的10年里出现了一些重要的方法和理论,典型的代表是:
1984:分类与回归树(CART)[2]
1986:反向传播算法[3]
1989:卷积神经网络[4]
分类与回归树
分类与回归树由Breiman等人在1984年提出,是决策树的一种经典实现,至今它还在很多领域里被使用。决策树是一种基于规则的方法,它由一系列嵌套的规则组成一棵树,完成判断和决策。和之前基于人工规则的方法不同,这里的规则是通过训练得到的,而不是人工总结出来的。
反向传播算法
人工神经网络是对动物神经系统的一种简单模拟,属于仿生方法。从数学的角度看,它是一个多层的复合函数。反向传播算法是神经网络训练时使用的算法,来自于微积分中复合函数求导的链式法则,至今深度学习中各种神经网络的训练使用的还是这种方法。反向传播算法的出现使得多层神经网络真正成为一种可以实现、具有实用价值的算法。在这一时期,神经网络的理论性研究也是热门的问题,神经网络数学上的表达能力的分析和证明大多出现在1980年代末和1990年代初。
从理论上来说,加大神经网络的规模可以解决更复杂的模式识别等问题。但是网络层数的增加会导致梯度消失问题,另外神经网络还面临着局部最优解的问题。训练样本的缺乏,计算能力的限制,都使得神经网络在接下来的20多年里没有太大的进展和出色的表现。
卷积神经网络
早在1989年,LeCun在贝尔实验室就开始使用卷积神经网络识别手写数字,这是当前深度学习中深度卷积神经网络的鼻祖;1998年,LeCun提出了用于字符识别的卷积神经网络LeNet5,并在手写数字识别中取得了较好的结果。卷积神经网络借鉴了动物视觉神经系统的原理,它能够逐层的对输入图像进行抽象和理解。
在这一时期,隐马尔科夫模型(HMM)被成功的应用于语音识别,使得语音识别的方法由规则和模板匹配转向机器学习这条路径。
1990-2012:走向成熟和应用
在这20多年里机器学习的理论和方法得到了完善和充实,可谓是百花齐放的年代。代表性的重要成果有:
1995:支持向量机(SVM)[5]
1997:AdaBoost算法[7]
1997:循环神经网络(RNN)和LSTM[9]
2000:流形学习[8]
2001:随机森林[6]
SVM
SVM基于最大化分类间隔的原则,通过核函数巧妙的将线性不可分问题转化成线性可分问题,并且具有非常好的泛化性能。和神经网络相比,SVM有完善的数学理论作为支撑,训练时求解的问题是凸优化问题,因此不会出现局部极值问题。

Vladimir Vapnik
SVM由Vapnik在1995年提出,在诞生之后的近20年里,它在很多模式识别问题上取得了当时最好的性能,直到被深度学习算法打败。
AdaBoost
AdaBoost和随机森林同属集成学习算法,它们通过将多个弱学习器模型整合可以得到精度非常高的强学习器模型,且计算量非常小。AdaBoost算法在机器视觉领域的目标检测问题上取得了成功,典型的代表是人脸检测问题。2001年,使用级联AdaBoost分类器和Haar特征的算法[14]在人脸检测问题上取得了巨大的进步,是有里程碑意义的成果。此后这一框架成为目标检测的主流方法,直到后来被深度学习取代。
循环神经网络
循环神经网络作为标准前馈型神经网络的发展,具有记忆功能,在语音识别、自然语言处理等序列问题的建模上取得了成功,是当前很多深度学习算法的基础。
流形学习
流形学习作为一种非线性降维技术,直观来看,它假设向量在高维空间中的分布具有一定的几何形状。在2000年出现之后的一段时间内名噪一时,呈现出一片繁荣的景象,但在实际应用方面缺乏成功的建树。
随机森林
随机森林由Breiman在2001年提出,是多棵决策树的集成,在训练时通过对样本进行随机抽样构造出新的数据集训练每一棵决策树。它实现简单,可解释性强,运算量小,在很多实际问题上取得了相当高的精度。时至今日,在很多数据挖掘和分析的比赛中,这类算法还经常成为冠军。
在这一时期机器学习算法真正走向了实际应用。典型的代表是车牌识别,印刷文字识别(OCR),手写文字识别,人脸检测技术(数码相机中用于人脸对焦),搜索引擎中的自然语言处理技术和网页排序,广告点击率预估(CTR),推荐系统,垃圾邮件过滤等。同时也诞生了一些专业的AI公司,如MobilEye,科大讯飞,文安科技,文通科技,IO Image等。
2012:深度学习时代,神经网络卷土重来?
在与SVM的竞争中,神经网络长时间内处于下风,直到2012年局面才被改变。SVM、AdaBoost等所谓的浅层模型并不能很好的解决图像识别,语音识别等复杂的问题,在这些问题上存在严重的过拟合(过拟合的表现是在训练样本集上表现很好,在真正使用时表现很差。就像一个很机械的学生,考试时遇到自己学过的题目都会做,但对新的题目无法举一反三)。为此我们需要更强大的算法,历史又一次选择了神经网络。
由于算法的改进以及大量训练样本的支持,加上计算能力的进步,训练深层、复杂的神经网络成为可能,它们在图像、语音识别等有挑战性的问题上显示出明显的优势。
Deep Thinkers on Deep Learning
Russ Salakhutdinov Head of AI at Apple
Rich Sutton Author of Reinforcement Learning
Geoff Hinton Univ. of Toronto, Google, DL patron saint
Yoshua Bengio Univ. of Montreal and head of MILA
深度学习的起源可以追溯到2006年的一篇文章[10],Hinton等人提出了一种训练深层神经网络的方法,用受限玻尔兹曼机训练多层神经网络的每一层,得到初始权重,然后继续训练整个神经网络。2012年Hinton小组发明的深度卷积神经网络AlexNet[11]首先在图像分类问题上取代成功,随后被用于机器视觉的各种问题上,包括通用目标检测,人脸检测,行人检测,人脸识别,图像分割,图像边缘检测等。在这些问题上,卷积神经网络取得了当前最好的性能。
在另一类称为时间序列分析的问题上,循环神经网络取得了成功。典型的代表是语音识别,自然语言处理,使用深度循环神经网络之后,语音识别的准确率显著提升,直至达到实际应用的要求。
历史选择了深度神经网络作为解决图像、声音识别、围棋等复杂AI问题的方法并非偶然,神经网络在理论上有万能逼近定理(universal approximation)[15]的保证:
只要神经元的数量足够,激活函数满足某些数学性质,至少包含一个隐含层的前馈型神经网络可以逼近闭区间上任意连续函数到任意指定精度。即用神经网络可以模拟出任意复杂的函数。我们要识别的图像、语音数据可以看做是一个向量或者矩阵,识别算法则是这些数据到类别值的一个映射函数。
下面来看深度学习在各个典型领域的进展。人脸检测算法在使用深度卷积神经之后进展迅猛,下面是FDDB数据集上各种算法的ROC曲线(这条曲线越高,算法越准确):

各种人脸检测算法在FDDB上的精度
(来自FDDB官网)
当前最好的结果都是由深度学习算法取得。类似的是人脸识别问题,在LFW数据集上,深度学习算法也独领风骚:

各种人脸识别算法在LFW数据库上的精度(来自LFW官网)
通用目标检测和分割是机器视觉领域非常有挑战性的任务,它要找出图像中各种不同类型的目标(如人,汽车,飞机等),确定它们的大小和位置以及轮廓。由于视角的变化,物体形状和外观的不同,光照的影响,遮挡等因素的存在,这类问题在长时间内没有大的进展。使用深度神经网络的算法在这一问题上也取得了历史性的突破。下表是VOC2012数据集上各种算法的准确率:
Object Detection (TRAIN ON ADDITIONAL DATA)
Object Segmentation (TRAIN ON ADDITIONAL DATA)
在语音识别、自然语言处理等领域,深度学习算法同样取得了可喜的结果。在这些领域的成功,直接推动了语音识别、机器翻译等技术走向实际应用。
在策略、控制类问题上,深度强化学习技术取得了成功,典型的代表是AlphaGo[13]。在各种游戏、自动驾驶等问题上,深度强化学习显示出了接近人类甚至比人类更强大的能力。
以生成对抗网络(GAN)[12]为代表的深度生成框架在数据生成方面取得了惊人的效果,可以创造出逼真的图像,流畅的文章,动听的音乐。为解决数据生成这种“创作”类问题开辟了一条新思路。
人工智能已经成为当前计算机科学领域最炙手可热的方向,在这一点上深度学习功不可没。而从正式诞生到真正大规模应用,机器学习已经走完了近40年的路。但人工智能要走的路还很长,在无监督学习等方向没有大的进展,深度学习还远不是终结者。正是一代又一代学术界和工业界的探索者不懈的努力,才使得人工智能发展到今天的地步,在此文的结尾我们向这些先驱者致敬!
参考文献
[1] Supposedly paraphrased from: Samuel, Arthur (1959). “Some Studies in Machine Learning Using the Game of Checkers”. IBM Journal of Research and Development.
[2] Breiman, L., Friedman, J. Olshen, R. and Stone C. Classification and Regression Trees, Wadsworth, 1984.
[3] David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning internal representations by back-propagating errors. Nature, 323(99): 533-536, 1986.
[4] LeCun, B.Boser, J.S.Denker, D.Henderson, R.E.Howard, W.Hubbard, and L.D.Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989.
[5] Cortes, C. and Vapnik, V. Support vector networks. Machine Learning, 20, 273-297, 1995.
[6] Breiman, Leo (2001). Random Forests. Machine Learning 45 (1), 5-32.
[7] Freund, Y. Boosting a weak learning algorithm by majority. Information and Computation, 1995.
[8] Roweis, Sam T and Saul, Lawrence K. Nonlinear dimensionality reduction by locally linear embedding. Science, 290(5500). 2000: 2323-2326.
[9] S. Hochreiter, J. Schmidhuber. Long short-term memory. Neural computation, 9(8): 1735-1780, 1997.
[10] G.E.Hinton, et al. Reducing the Dimensionality of Data with Neural Networks, Science 313, 504(2006)
[11] Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton. ImageNet Classification with Deep Convolutional Neural Networks.
[12] Goodfellow Ian, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets. Advances in Neural Information Processing Systems, 2014: 2672-2680.
[13] David Silver, et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature, 2016.
[14] P.Viola and M.Jones. Rapid object detection using a boosted cascade of simple features. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition, 2001.
[15] Hornik, K., Stinchcombe, M., and White, H. Multilayer feedforward networks are universal approximators. Neural Networks, 2, 359-366, 1989.
-The End-

 友情链接
友情链接