








公众号/将门创投
来源:Mit MediaLab 编译:Kathy
MIT的研究人员正在使用新的机器学习技术, 通过减少治疗胶质母细胞瘤过程中毒性化疗和放疗的剂量,来提高患者的生活质量。而胶质母细胞瘤是一种最严重的脑癌。
胶质母细胞瘤是一种出现在大脑或脊髓中的恶性肿瘤,成人的预后不超过五年。患者必须忍受每月放疗和服用多种药物的联合治疗法。医学专业人员通常在安全范围内给予最大药物剂量以尽可能缩小肿瘤。但是这些药效强烈的副作用会使患者非常虚弱。
在斯坦福大学2018年医学健康机器学习大会上发表的一篇论文中,麻省理工学院Media实验室的研究人员详细介绍了一个模型,该模型可以使给药方案毒性更小,但仍然有效。该模型以“自主学习”机器学习技术为动力,研究目前使用的治疗方案,并反复调整剂量。最终,找到一个最佳的治疗方案,可以尽可能降低毒性和剂量,而且仍然能够将肿瘤缩小到与传统治疗方案相当的程度。
在对50名患者的模拟试验中,机器学习模型设计了治疗周期,几乎把所有的药物剂量都降低了四分之一或一半,同时保持相同的效用使肿瘤缩小。多数情况下,它忽略了总剂量的限制,用一年给药两次替代每月给药。
负责这项研究的Media实验室的项目负责人(PI)Pratik Shah说:“我们坚持的目标是,一方面必须缩小肿瘤的大小,但同时也希望确保病人的生活质量,不让剂量毒性造成严重的疾病和有害副作用。”论文的第一作者是Media实验室的研究员格Gregory Yauney。
鼓励好的选择

在这一研究中研究人员使用了一种被称为强化学习(Reinforced Learning,RL )的技术,该方法受到行为心理学的启发,在这种方法中,模型会偏爱那些可以带来较好预期结果的行为。该技术利用人工智能“代理”,在不可预知的复杂环境中完成“动作”,以达到期望的“结果”。每当它完成一个动作时,代理会收到一个“奖励”或“惩罚”,这取决于该动作是否朝着结果进行。然后,代理相应地调整其动作以实现预期的结果。
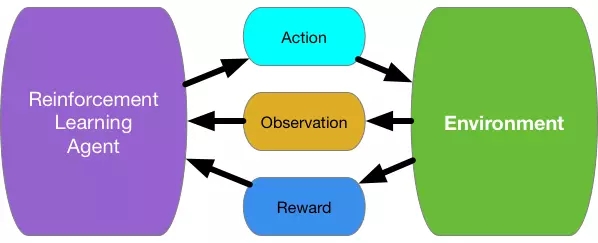
奖励和惩罚基本上被标记为正数和负数,比如+ 1或- 1。除其他因素外,所得的分数取决于所采取的行动,根据结果的成功或失败的概率计算得分。代理本质上是试图根据奖励和惩罚值,从数值上优化所有动作,在给定的任务中取得最大的结果分数。
这种方法被Deep Mind用来训练计算机程序,该程序在2016年因击败了世界上最好的人类玩家之一而一举成名。它还被用来训练无人驾驶汽车的行驶策略,例如并入车流或停车,在这个程序里,车辆会反复练习,调整路线,直到正确。
研究人员将RL模型用于胶质母细胞瘤的治疗,该治疗方案为替莫唑胺( TMZ ),普鲁卡因、洛莫司汀和长春新碱( PVC )的联合服药疗法,给药时间长达数周或数月。
该模型梳理了传统的给药方案。这些方案在临床上已经使用了几十年,并且基于动物试验和各种临床试验制定。肿瘤学家使用这些既定的方案根据体重来预测患者的给药剂量。当模型探索该方案时,在每个计划的给药间隔里,比如每月一次,会先决定其中的一个动作。首先,它可以启动或停止一个剂量。如果确定给药,会决定是否需要给足所有剂量,或者仅仅一部分剂量就足够了。在每一个动作中,都会查验另一个临床模型——通常用于预测肿瘤因治疗而带来的体积变化——来看看这个动作是否会缩小平均肿瘤直径。如果是的话,这个模型会得到奖励。
然而,研究人员还必须确保该模型不仅仅为了最大疗效而给出最大的剂量。任何时候模型选择给予全部剂量时,它就会受到惩罚,因此它会选择更少、更小的剂量。 “如果我们想做的只是缩小平均肿瘤直径,放任它采取任何它想采取的行动,它将不负责任地给药“,Shah说,“相反,我们需要减少那些一味的缩小肿瘤体积而产生的有害行为。”
Shah说,这是在论文中首次描述的非传统的RL模型,它将行动(剂量)的潜在负面后果与结果(肿瘤减小)进行权衡。传统的RL模型致力于单一结果,例如为了赢得一场比赛,将采取一切使结果最大化的行动。这个模型在每一个动作中都有灵活性,它可以找到一种剂量,这种剂量不一定能独立的最大限度地减少肿瘤体积,但能在最大限度地减少肿瘤体积和低毒性之间达到完美的平衡。他补充说,这种技术在医学和临床试验中有多种应用,在这些领域,治疗方法应该被规范,以防止有害的副作用产生。
最佳方案
研究人员在50名病人身上训练了这个模型,这些病人是从先前接受过传统治疗方法的胶质母细胞瘤病人的大型数据库中随机挑选出来的。对于每个病人,该模型进行了大约20,000次试错测试。训练完成后,该模型学习最佳方案的参数。当应用于新的病人时,使用这些参数,并根据研究人员要求的各种限制来制定新的方案。
研究人员随后在50名新的模拟患者身上测试了该模型,并将结果与那些使用了TMZ和PVC的常规治疗方案的病人进行了比较。当没有剂量惩罚时,该模型设计了和人类专家几乎相同的方案。然而,考虑小剂量和大剂量的惩罚时,它大大降低了剂量的频率和效力,同时也减少了肿瘤的大小。
研究人员还设计了一个模型来单独治疗每个病人,也可以对一组病人进行治疗,并取得了类似的结果。按照已有的方法整个患者群体都是使用了相同的给药方案,但是肿瘤的大小、病史、基因谱和生物标记物的差异都会影响患者的治疗方案。Shah说,在传统的临床试验设计和其他治疗中,这些变量没有被考虑在内,这通常会导致在大范围病人中对治疗效果反应不佳。
“我们不断的优化模型,来给不同的患者给出个性化的用药方案。模型可以给这个人四分之一剂量,给那个人一半剂量,或许那个病人不需要服药了。这是这项工作中最激动人心的部分,通过使用非正统的机器学习架构进行一人试验来产生精确的基于药物的治疗。”Shahs说。
研究人员表示,该模型比传统的靠眼睛观察来给药、观察患者反应然后做出相应调整的方法有了重大飞跃。人不具备机器查看大量数据后所获得的深度感知,所以人类来处理的的话,过程是缓慢、乏味且不精确的。让计算机在数据中寻找模式(让人来做的话会花费大量时间来筛选),并使用这些模式来寻找最佳剂量。”
这项工作可能会引起美国食品和药物管理局(FDA)的特别兴趣,FDA正在寻找利用数据和人工智能开发健康技术的方法。法规仍然需要建立,但是毫无疑问,在短时间内,FDA会想出如何适当地审查这些“技术”,以便它们可以用于日常的临床项目。”关于人工智能用于预测给药剂量的其他报道,可以参见我们公众号里以前的一篇推送,关于器官移植患者接受免疫制剂给药剂量的报道>>在实现了检查病、开药方后,AI还将告诉你该如何吃药—解读最佳药物组合和给药计量
一些参考
Researcher: https://www.pratiks.info
paper: http://web.media.mit.edu/~pratiks/mlhc_2018/reinforcement_learning_with_action_derived_rewards_for_chemotherapy_and_clinical_trial_dosing_regimen_selection.pdf
conference: https://www.mlforhc.org/

 友情链接
友情链接