








公众号/AI前线
作者|The Next Platform
译者|无明
编辑|Debra
AI 前线导读:在今天上午刚刚结束的日本 GTC 大会上,英伟达终于发布了推理专用 GPU Tesla T4 加速器。Tesla T4 基于“图灵”GPU 架构,该架构于今年夏天早些时候推出,用于 GeForce RTX 和 Quadro RTX 卡,可通过机器学习算法增强动态射线跟踪。Tesla T4 上的芯片包含了 2560 个 CUDA 内核,具有 32 位单精度和 16 位半精度浮点数学单元(FP32 和 FP16)以及 8 位和 4 位整数数学单元(INT8 和 INT4)。性能达到了单精度 8.1teraflops,而使用新的 INT8 八位整数格式可达到 130teraops,相比上一代 P4 效率得到了很大的提升。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)在过去六年中,机器学习领域的关注点都集中在神经网络的训练以及 GPU 加速器如何从根本上提高网络的准确性上,这要归功于 GPU 大内存带宽和并行计算能力。现在,机器学习行业正趋于平衡,越来越多的关注点转移到了推理上,也就是使用训练模型基于新数据做一些有用的事情。
推理对于 Nvidia 来说绝对不陌生,尽管它之前一直致力于创建机器学习训练平台。如果你要训练神经网络,一定要在新数据上运行,所以不可避免地要进行推理。
Nvidia 的第一个基于 GPU 的推理引擎是 Tesla M4(基于“麦克斯韦”GM106 GPU,主要支持单精度浮点数学运算)和 Tesla M40(基于 GM204 GPU,主要用于机器学习训练,也不支持双精度)。这两个设备于 2015 年 11 月问世,当时的神经网络的复杂度要低得多。Tesla M4 的单精度性能可以达到 2.2 teraflops,并且提供了 50 瓦或 75 瓦热封套版本。Tesla M4 拥有 1024 个 CUDA 内核和 8 GB GDDR5 帧缓冲内存,内存带宽达到了 88 GB/ 秒。这比 Xeon CPU 的内存要少得多,但与典型的双插槽 Xeon 系统能够提供的内存带宽相当,并且在推理方面提供了足够的并行计算来打败 X86 系统。但 Xeon 服务器已经存在于数据中心中,所以公司在很大程度上仍然需要依赖它们。

两年前,当 Nvidia 推出专门针对机器学习推理的 Tesla P4 和 P40 加速器时,它在市场上占有一席之地并对这部分市场进行了更为认真的尝试。当时我们还创造了所谓的 Buck 定律,它假定世界上生成的数据在其生命周期内都需要进行千兆次的计算。这个说法当然不是很精确的,提出这个说法的是 NvidiaTesla 数据中心业务部副总裁兼总经理 Ian Buck。这个说法其实是涵盖了各种工作负载,并不仅限于机器学习训练和推理。Nvidia 在构建用于 HPC 和 AI 工作负载的 GPU 计算的 Tesla 硬件和 CUDA 软件方面做了很出色的工作,并且正在扩展到其他领域,例如 GPU 加速数据库以及传统的虚拟桌面和部分虚拟工作站。
推理引擎被嵌入到各种各样的系统中,因为机器学习现在已经成为应用程序栈的一部分。这一切都始于超大规模的公司,他们拥有足够的数据进行机器学习,而 GPU 又提供了足够的内存带宽和并行计算能力让机器学习训练算法发挥作用。Facebook 每天的视频浏览量超过 10 亿,背后有机器学习推荐引擎和搜索引擎在推动,而谷歌和 Bing 每天由语音识别驱动的搜索超过 10 亿次。网页浏览量和搜索量每天带来超过 1 万亿次广告展示。微软是公开承认正在使用 GPU 加速视觉搜索的超大规模公司之一。
两年前的 Tesla P4 加速器将 GPU 推理提升了一个档次,在同样的 50 瓦和 75 瓦热封套中包含了 2560 个核心,性能达到了单精度 5.5teraflops,而使用新的 INT8 八位整数格式可达到 22 teraops。Tesla P4 配备 8 GB GDDR5 内存,并提供超过两倍的内存带宽,以平衡两倍于 192 GB/ 秒的计算量。
Tesla P4 加速器是一个不错的推理设备,并已经被用在很多工作负载上。Buck 不能随意透露推理业务的实际收入,特别是 Tesla P4 的实际收入,但他通过 The Next Platform 分享了推理工作类型的收入细分:

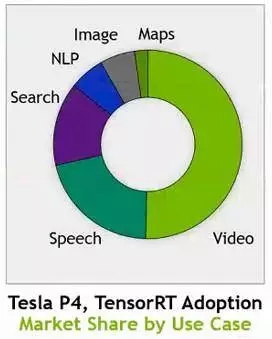
目前,视频识别推理正在推动其中一半的业务,语音处理大约占四分之一。搜索也很重要。这个饼图无疑会随着时间的推移而改变。Buck 补充说,Tesla 的推理收入流已经成为“业务的重要组成部分”。
今天,在日本 GPU 技术大会上宣布的 Tesla T4 加速器正在将 GPU 推理推向新的高度。
机器学习软件栈正在发生快速的变化,很多芯片制造商正在寻找推理方面的机会,Buck 声称这个市场在未来五年可以达到 200 亿美元的规模。(这意味着在五年之后,机器学习推理将推动 200 亿美元的基础设施销售,而不仅仅是与基础设施相关的芯片销售。)重点是,正如英特尔所说的那样,两年前 95%的机器学习推理已经部署在了 X86 服务器上,这些服务器并没有使用加速器或其他类型的处理器。但仍然有大量数据需要进行推理,无论它们是在我们的智能手机中,在网络边缘,还是在数据中心中,它们都要求系统能够进行更有效地推理。FPGA 也在这里起到一定的作用,很多专用的 ASIC 也是如此—— Graphcore 在这方面表现突出,Wave Computing 也起到很大的作用,Brainchip 采用了非常不一样的尖峰神经网络方法。
Tesla T4 基于“图灵”GPU 架构,该架构于今年夏天早些时候推出,用于 GeForce RTX 和 Quadro RTX 卡,可通过机器学习算法增强动态射线跟踪。与专注于 HPC 和机器学习训练的“Volta” GV100 GPU 一样,Tesla T4 加速器使用的图灵 GT104 GPU 由台湾半导体制造公司使用 12 纳米制造工艺进行蚀刻。它拥有 136 亿个晶体管,接近 Pascal GP100 GPU 的 153 亿个晶体管,但仍落后于 GV100 GPU 的 211 亿个晶体管。这是 GT104 GPU 上的一个内核照片:

GT104 芯片提供了专用的 RT 内核来执行射线跟踪,但这对推理并没有太大帮助,即使推理引擎反过来对射线跟踪很有用。Tesla T4 上的芯片包含了 2560 个 CUDA 内核,具有 32 位单精度和 16 位半精度浮点数学单元(FP32 和 FP16)以及 8 位和 4 位整数数学单元(INT8 和 INT4)。Volta GV100 上的 FP64 数学单元不在图灵架构中,但如果真的想在 Tesla T4 上进行机器学习训练,并且没有使用需要 FP64 的框架,那么按照 Buck 的说法,这样是可行的——但这并不是这个设备的设计考虑点,因为它在内存容量和带宽方面有所限制。具体而言,Tesla T4 配备了用于计算的 16 GB GDDR6 帧缓冲内存,并提供 320 GB/ 秒的内存带宽。GT104 GPU 有 320 Tensor Core,可用于执行机器学习中常用的矩阵运算。(Tensor Cores 一趟可以处理带有 FP16 输入和 FP32 输出的 4x4x4 矩阵。)
这比 Volta GV100 GPU 的配置要低得多,后者包含了 5376 个 32 位整数内核、5376 个 32 位浮点内核,2688 个 64 位内核、672 个 Tensor 内核和 336 个跨 84 个流式多处理器(SM)的纹理单元。在生产 GV100 时,84 个 SM 中只有 80 个被激活,这样才能保证足够的良品率,因为要启用所有 84 个 SM 就很难获得完美的芯片。GT104 GPU 的不同之处在于它支持 INT8 和 INT4 格式的张量核心单元,这会让数据量翻倍或翻两倍,也会让整数单元的处理吞吐量加倍或翻两倍。以下是 Tesla P4 和 T4 加速器在推理工作负载上的峰值相对性能表现,具体取决于数据的位数和处理方式:
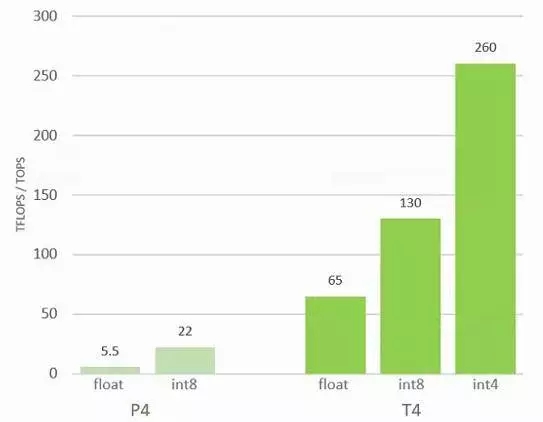
Buck 告诉 The Next Platform,“我们采用了 Volta Tensor Core,并专门针对推理将其演化为图灵芯片。如果使用 INT8,FP16 的基本性能可以加倍,我们已经为此对软件进行了优化。如果使用 INT4,可以将性能再翻番。我们的一些研究人员已经发布了他们的工作成果,即使只使用四个位,他们也可以通过极小、高效和快速的模型来保持高精度。我们甚至可以使用 INT1,但这还只是一个研究课题。”
Nvidia 认为,随着机器学习被嵌入到应用程序技术栈中以及人类有限的耐心,延迟成为最重要的关注点,将 GPU 添加到推理技术栈中可以从根本上减少推理所需的时间。与之前仅使用 CPU 的方法相比,微软通过 GPU 加速视频识别算法,将视觉搜索的延迟减少了 60 倍。专注于实时视频分析的初创公司 Valossa 试图推理出人们的情绪,其推理速度也提高了 12 倍。SAP 有一个用于分析品牌影响力的软件系统,可在视频中查找公司的 logo,分析它们在屏幕上的显示时间、它们的大小等等,该软件系统在使用 GPU 进行推理之后,性能提高了 40 倍。
另外,延迟并非只针对单个推理工作负载。很多工作负载使用了不同的框架,而且还有很多来自不同神经网络的带有不同风格的推理模型需要处理。
为了说明这一点,Buck 以语言搜索为例,说明在 CPU 上完成这些是多么的痛苦。首先必须运行自动语音识别,这部分使用了百度的 DeepSpeech2 神经网络,它需要大约 1000 毫秒来处理“Where is the best ramen shop nearby?”这句话。接下来,应用程序必须理解搜索请求的上下文,这需要用到自然语言处理。Nvidia 选择了谷歌的 GNMT 神经网络,只需 35 毫秒即可完成。然后,GNMT 的输出被传给推荐引擎,这一步使用了 Deep Recommender,大概需要 800 毫秒。接下来,推荐系统的输出被传给文本到语音生成器,这一步使用了 DeepMind(被谷歌收购)的 Wavenet,这需要 159 毫秒。把所有时间加起来,大概是 1994 毫秒。差不多两秒钟,人们造就等得不耐烦了,所以肯定会跑到其他网站去了。
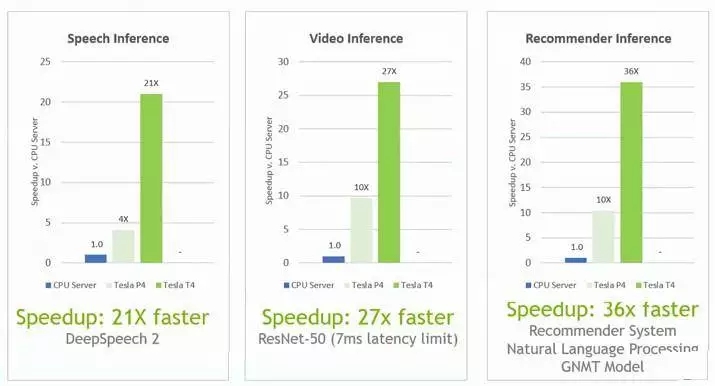
如果推理想要变得高效,就必须变得更快,如果想要在 GPU 上普及,就必须变得更便宜。所以,Nvidia 将 Tesla P4 和 T4 加速器安在配备了一对英特尔 18 核 Xeon SP-6140 Gold 处理器(运行频率为 2.3 GHz,单个售价约为 2450 美元)的服务器上。Tesla T4 让 Xeons 处理器对相形见绌。Nvidia 没有给出 Tesla T4 的定价,但据我们所知,Tesla P4 零售价约为 3000 美元。因此,如果 Tesla T4 的价位与 Tesla P4 差不多,并且推理性能是 Xeon SP 处理器对(一对售价约为 5000 美元)的 21 倍至 36 倍,那么从价格和性能的比率上看,Tesla T4 是 Xeon SP 处理器的 35 倍至 60 倍。英特尔拥有更多内核的处理器,但它们的价格上涨速度超过了它们的性能,这会削弱它的优势。
Tesla T4 将于第四季度上市,谷歌表示将会在自家的云平台上使用这些设备,就像上一代 Tesla P4 加速器一样。看着 Tesla T4 机架被加到谷歌 TPU 3 加速器机架上以进行推理工作,这将是一件非常有趣的事情。
英文原文:
https://www.nextplatform.com/2018/09/12/nvidia-takes-on-the-inference-hordes-with-turing-gpus/

 友情链接
友情链接