








公众号/机器之心
选自Towards Data Science
作者:Jeff Hale
机器之心编译
参与:高璇、路
本文整理了多个求职网站的信息,对雇主最希望数据科学家具备的技能进行了分析,并提供了一些建议。
数据科学家需要涉猎很多——机器学习、计算机科学、统计学、数学、数据可视化、通信和深度学习。这些领域中有几十种语言、框架和技术可供数据科学家学习。那么要想成为雇主需要的数据科学家,他们应该如何安排学习内容呢?
我搜索了招聘网站,想找到数据科学家最需要的技能。我分别研究了通用的数据科学技能和特定的语言、工具。2018 年 10 月 10 日,我在 LinkedIn、Indeed、SimplyHired、Monster 和 AngelList 上搜索了招聘信息。下表展示了每个网站列出的数据科学家职位数量。

我读了许多招聘要求和调查,以找到最常用的技能。像「管理」这样的词会在不同背景的招聘信息中不断提及,因此不列入比较范围。
所有的搜索都是以「数据科学家」「[关键字]」格式展开的。使用精确匹配搜索虽然减少了搜索结果的数量,但确保了结果与数据科学家的职位相关,且对所有搜索关键词产生类似的影响。
AngelList 提供的是具备数据科学家职位需求的公司数量,而不是职位数量。所以 AngelList 被排除在这两种分析之外,因为它的搜索算法是一种「OR」的逻辑搜索,无法变为「AND」。如果你搜索「数据科学家」「TensorFlow」这类只会在数据科学家职位上找到的词,AngelList 表现得很好。但如果关键词是「数据科学家」「react.js」,搜索结果中会出现太多不具备数据科学家职位需求的公司。
Glassdoor 也不在分析范围之内。该网站表示,在美国有 26263 个「数据科学家」职位,但它显示的职位数据不超过 900 个。此外,Glassdoor 上的数据科学家职位数量也不太可能是任何其他主流平台的三倍。
最终使用 LinkedIn 上的 400 多个职位信息用于对通用技能的分析,200 多个职位信息用于对特定技能的分析。当然有一些职位可能重复用于两种分析。结果记录在 Google 表格中(https://docs.google.com/spreadsheets/d/1df7QTgdAOItQJadLoMHlIZH3AsQ2j2_yoyvHOpsy9qU/edit?usp=sharing)。
我下载了 .csv 文件并将它们导入 JupyterLab。然后计算出事件发生的百分比,并针对招聘网站的数量进行平均运算。
我还将运算结果与 2017 年上半年 Glassdoor 对数据科学家职位要求的研究进行了比较。结合KDNuggets 的调查信息来看,有些技能变得越来越重要,有一些则变得无足轻重。我稍后会谈到这些。
有关交互式图表和其他分析,请参阅我的 Kaggle Kernel(https://www.kaggle.com/discdiver/the-most-in-demand-skills-for-data-scientists/)。我利用 Plotly 做了可视化。截至本文写作时,使用 Plotly 与 JupyterLab 会有些争议,在 Kaggle Kernel 末尾和 Plotly 文档会有说明。
通用技能
以下是雇主最希望数据科学家具备的通用技能。
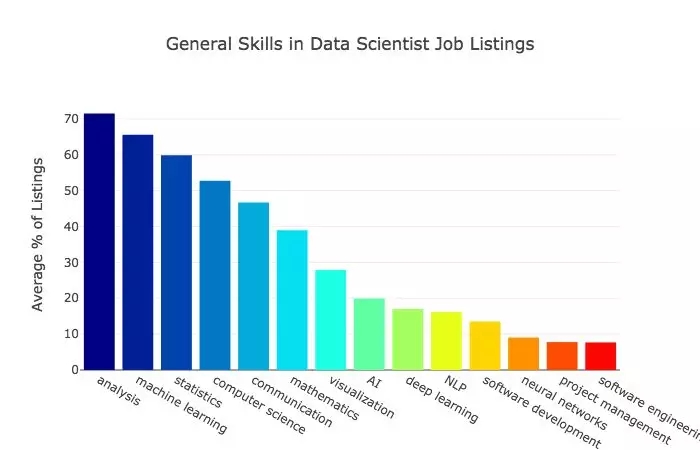
结果表明,分析和机器学习是数据科学家工作的核心。洞察数据是数据科学的一项基本功能。机器学习就是创造能够预测性能的系统,这在现在是非常需要的。
数据科学需要统计和计算机科学技能。统计学、计算机科学和数学都是大学课程,这可能是这几个词出现频率高的原因。
有趣的是,几乎一半的职位要求中都提到了「沟通」。数据科学家需要具备与他人交流和合作的能力。
人工智能和深度学习并不像其他词出现地那么频繁,虽然它们是机器学习的子集。深度学习被用于越来越多的机器学习任务,取代了曾经的算法。例如,现在针对大多数自然语言处理问题的最佳机器学习算法是深度学习算法。我预计未来人们将更明确地追寻深度学习技能,机器学习与深度学习的意义将更加接近。
雇主希望数据科学家使用哪些特定的软件工具呢?下面我们来解决这个问题。
技术技能
下表是雇主希望数据科学家必备的前 20 种特定语言、库和技术工具。
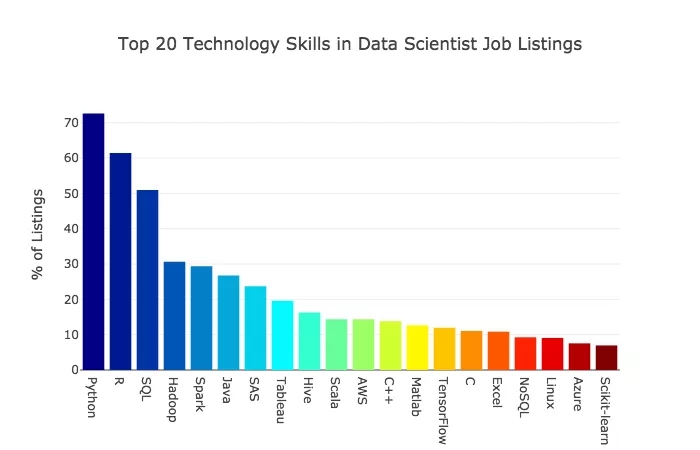
我们简单看看最普遍的技术技能。
Python 是最受欢迎的语言。这个开源语言已经广为流行了,它对初学者十分友好,有许多支持资源。绝大多数新的数据科学工具都与之兼容。Python 是数据科学家的主要语言。
R 和 Python 很接近。它曾经是数据科学的主要语言,目前它的需求量仍然很大。这种开源语言的基础是统计学,所以它仍然很受统计学家的欢迎。
对于每个数据科学家来说,Python 或 R 语言是必不可少的。
SQL 也很受欢迎。SQL 表示结构化查询语言(Structured Query Language),是与关系数据库交互的主要方式。在数据科学领域,SQL 有时会被低估,但如果你打算进入职场,这是一块很有价值的「敲门砖」。
接下来是 Hadoop 和 Spark,这两款开源工具都来自 Apache,面向大数据。
Apache Hadoop 是一个开源软件平台,利用商用硬件计算机集群进行分布式存储和分布式处理。
Apache Spark 是一个基于内存的快速数据处理引擎,具有简明而富有表达性的开发 API,允许数据工作人员高效地执行流、机器学习或 SQL 工作,这些工作负载需要对数据集进行快速迭代访问。
这些工具的教程和 Medium 网站文章远远低于其他工具。我认为具备这些技能的求职者比会 Python、R 和 SQL 的少得多。如果你具备使用 Hadoop 和 Spark 的经验,那么你在竞争中会获得优势。
然后是 Java 和 SAS。我很吃惊这些语言排名会这么高。这两种语言背后都有大公司支持,而且至少有一些免费产品。但在数据科学社区中,Java 和 SAS 通常很少受到关注。
接下来是 Tableau。这个分析平台和可视化工具功能强大、易于使用,并且越来越流行。它有一个免费的公开版本,但是如果想保证数据的隐私性,需要付费。
如果不熟悉 Tableau,那么在在线教育网站上学习速成课程是很值得考虑的,比如 https://www.udemy.com/tableau10/。
下表更完整地展示了需求最多的语言、框架和其他数据科学软件工具。

前后对比
GlassDoor 曾分析了 2017 年 1 月至 7 月数据科学家最常用的 10 种软件技能。以下是 GlassDoor 网站上出现这些词汇的频率与 LinkedIn、SimplyHired 和 Monster 在 2018 年 10 月的平均频率的对比。
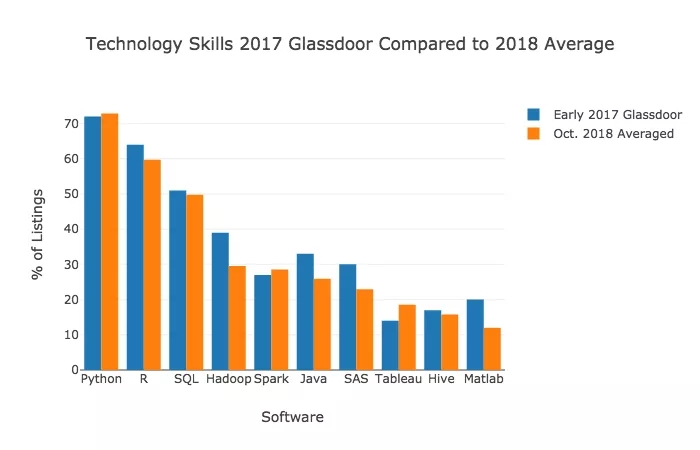
结果相当一致。我的分析和 GlassDoor 的研究结果都显示 Python、R 和 SQL 是最受雇主欢迎的语言。top 9 技术技能也基本一致,只是顺序略有不同。
结果表明,与 2017 年上半年相比,R、Hadoop、Java、SAS、MatLab 的需求有所减少,Tableau 的需求有所增加。以 KDnuggets developer survey 的调查结果作为补充,这一结果在我预期之中。KDnuggets 调查显示,R、Hadoop、Java 和 SAS 都有明显下降趋势,Tableau 呈现明显上升趋势。
建议
根据这些分析的结果,我将向现在和以后有志于从事数据科学工作的人提供一些通用建议,关于如何使自己被市场广泛接受。
证明你可以做数据分析,并专注于真正熟练地掌握机器学习。
锻炼沟通技巧。推荐阅读《Make to Stick》一书,它帮助你产生更具影响力的想法。也可以通过 Hemmingway Editor 来提高写作水平。
掌握深度学习框架。精通深度学习框架在精通机器学习中的占比越来越大。有关深度学习框架在使用、热点和流行度方面的比较,请参阅文章:2018 年最热门的深度学习框架?这份科学的排行榜可以告诉你。
如果你在学习 Python 和 R 之间犹豫,选择 Python。如果你对 Python 不感冒了,就考虑学习 R,如果你对 R 语言也有所了解,你肯定会更有市场。
当雇主在寻找具有 Python 技能的数据科学家时,他们也期望应聘者了解常用的 Python 数据科学库:numpy、panda、scikit-learn 和 matplotlib。如果你想学习这组工具,可利用以下资源:
如果你想开始深度学习,我建议先从 Keras 或 fastai 开始,然后再转向 TensorFlow 或 PyTorch。Francois Chollet 的《Deep Learning with Python》是学习 Keras 的很好的资源。
此外,我建议你了解兴趣所在,尽管在决定分配学习时间时要考虑很多因素。
如果你正在找工作或在求职网站上发布职位空缺,关键词很重要。在每个网站上,「数据科学」返回的结果几乎是「数据科学家」结果的三倍。如果你要找的是数据科学家的工作,你最好还是搜索「数据科学家」。
建议制作一个在线作品集,尽可能展示你对这些必备技能的熟练程度。我还建议通过 LinkedIn 个人资料展示你的技能。
希望本文对大家有所帮助。

 友情链接
友情链接