








公众号/将门创投
来源Bair 编译:T.R
伯克利和谷歌大脑的研究人员近日发表了全新的强化学习算法:柔性致动/评价(soft actor-critic,SAC)。作者表示,作为目前高效的model-free算法,十分适用于真实世界中的机器人任务学习。在这篇文章中,将详细比较SAC与前沿强化学习算法的性能,并利用多个实际任务作为例子来展示最新算法的能力。这一算法还包含完整详细的源码实现供研究者学习和使用。
真实世界中理想的强化学习算法应该具有什么样的特性呢?与虚拟和实验室环境相比,真实情况将为算法带来一系列挑战。包括通信和数据流连续中断、低延时的推理、为避免设备机械损伤需要尽可能平滑连续的运动等,这些都为算法本身及其实现带来了更多的要求。
研究人员通常希望应用在真实世界中的算法具有以下优点:
· 样本效率。在真实世界中学习技能是耗时的任务,对于每一个新任务的学习都需要多次试错,学习一个新技能所需的总时间会十分可观,所以良好的样本复杂度是一个优秀算法的先决条件。
· 对超参数不敏感。真实世界中研究人员希望避免参数调整,而最大化交叉熵的强化学习提供了一个鲁棒的学习框架来最小化超参数调节的需求。
· Off-policy学习。解耦策略(off-policy)学习意味着可以使用其他任务场景收集的数据来学习,例如在准备新任务时只需要调整参数和奖励函数,而解耦策略则允许复用已经收集好的数据来训练算法。
SAC是一个解耦策略(off-policy)和自由模型(model-free)深度强化学习算法。它不仅涵盖了上述优点,同时其样本效率足够在几小时内解决真实世界的机器人学习问题。此外其超参数十分鲁棒,只需要单一的超参数集就可以在不同的模拟环境中获得良好的表现。更为重要的是这一算法的实现还包含了以下特点,为真实世界的机器人学习提供了重要的作用:
· 异步采样;需要足够快的推理来最小化控制环中的延时,同时也希望在执行过程中进行训练。所以在实际情况中数据采样和实际训练应该由独立的线程或进程运行;
· 停止/假设训练;真实硬件中将会面临一系列错误情况,需要考虑数据流连续中断的情况;
· 运动平滑.典型的高斯探索(exploration)将会导致致动器产生抖动,这会对硬件造成不利的影响甚至损伤驱动器和机械结构,所以在实际中研究人员使用了探索的时域相关性来有效缓解这一问题。
SAC基于最大熵强化学习框架,其中的熵增目标如下所示:
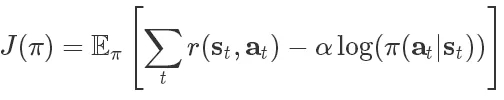
其中s 和a 是状态和行动,期望则包含了策略和来自真实系统的动力学性能。换句话说,优化策略不仅最大化期望(第一项),同时还最大化期望的熵(第二项)。其中的参数α平衡了这两项对于结果的影响,当α为0时上式就退化为传统的预期回报目标函数。研究人员认为可以将上述目标函数视为熵约束的最大化预期回报,通过自动学习α参数来代替超参数。
我们可以从多个角度解释这一目标函数。既可以将熵看作是策略的先验,也可以将其视为正则项,同时也可以看作是探索(最大化熵)和利用(最大化回报)间的平衡。
SAC通过神经网络参数化高斯策略和Q函数来最大化这一目标函数,并利用近似动力学编程来进行优化。基于这一目标函数研究人员推导出了更好的强化学习算法,使其性能更加稳定,并且达到足够高的样本效率来应用到真实机器人中。
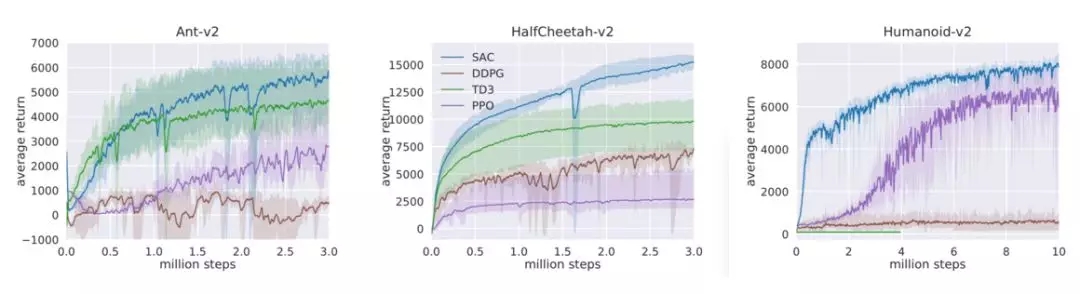
为了评价新型算法的表现,研究人员首先在仿真环境中利用标准的基准任务来对SAC进行了评测,并与深度确定性策略梯度算法(DDPG),孪生延迟深度确定性策略梯度算法(TD3),邻近策略优化(PPO)等算法进行了比较。几种算法在三种基本的模拟移动任务上进行了性能比较,分别是豹,蚂蚁和人形。

下图描述了几个算法在三个不同任务中的表现,其中实线表示算法的平均回报而阴影则描述了算法表现的范围,包含了最好和最坏的表现。SAC算法在下图中由蓝色表示,可以看到它的效果最好。更重要的是在最坏的情况下,它还可以保持较好的表现(这意味着在某些极端糟糕的情况下还能保持鲁棒性)。
为了检验算法在真实世界中的能力,研究人员在不依赖仿真或者试教的情况下从零开始让机器人学习解决三个任务。第一个任务中利用了小型四足机器人米诺陶,它拥有八个直驱致动器。其运动空间由摆角和每条腿的延伸部分构成,将运动映射到期望的电机位置,并利用PD控制器进行跟踪。其观测数据包括电机角度、滚转角度、俯仰角度以及基体的角速度。这一任务中欠驱动的机器人需要精巧地平衡腿部接触力大小来实现移动。没有训练过的机器人将会失去平衡并摔倒,摔倒太多次的试错将会损坏机器人,所以样本效率是算法的关键。下面展示了学习后的算法表现,虽然在平面上对机器人进行的训练,但在测试时的不同崎岖、动态的地形上也获得的较好的结果。这主要来源于SAC学习到了鲁棒的策略,训练时的熵最大化使得策略可以很好地泛化这些地形的扰动而无需额外的训练过程。

第二个项目是利用三指灵巧手来旋转一个阀门的任务。其中机械手有9个自由度,由9个舵机控制。学习出的策略将向PID控制器发送关节的目标角度来实现控制。为了感知到阀的位置,机器人需要机遇下图中右下角的原始RGB图像来获取信息。机器人的目标是将阀带有颜色的一边旋转到下图所示的位置。阀由一个独立的电机控制,并按照均匀分布每次初始化到不同的位置(电机的位置同时也为训练提供了基准)。这将强制策略从原始的RGB中学习到阀当前的朝向。这一任务也由于需要同时感知RGB图像和对九个自由度的控制而增加了难度。

转动阀门的灵巧手
在最后的任务中,研究人员将训练7自由度的Sawyer来堆叠乐高块。策略接收的信号包括关节的角度的速度以及末端执行器的力作为输入,同时输出每个关节的力矩来控制机器人。这个任务中最大的挑战在于需要先准确的对好积木间的位置,随后再用力克服插入的摩擦来安放积木。

SAC算法对于上面三个任务都给出了较快的解决:其中米诺陶全地形行走和Sawyer码积木只用了两个小时的训练时间,而灵巧手拧阀门则使用了20个小时。如果直接把阀门的角度告诉机器人而不是通过图像去学习,则只需要三个小时就能学会。而之前的PPO算法则需要7.4小时才能通过角度学会拧阀门。
SAC算法是深度强化学习实用化的关键一步,虽然在更具挑战的场景和更大规模的情况下使用还需要很多的工作和研究,但SAC给出的结果已经让真实世界中的机器人向期待的目标迈出了关键的一步,这对于强化学习在机器人领域的实用化具有十分重要的意义。
如果小伙伴们想了解更多,请移步项目主页:
https://sites.google.com/view/sac-and-applications
同时,研究人员们还将大部分著名的机器人强化学习算法打包成了一个工具包rlkit,其中就包含了本文的SAC算法。开源不久目前已经在git上收获了384颗星。

可以直接利用conda运行配置环境就可以直接开始愉快的玩耍了。
https://github.com/vitchyr/rlkit
此外还有一个利用PyTorch实现SAC的版本:
https://github.com/rail-berkeley/softlearning
以及:https://github.com/haarnoja/sac
ref:
paper:
https://drive.google.com/file/d/1J8gZXJN0RqH-TkTh4UEikYSy8AqPTy9x/view
turorial and review:
https://arxiv.org/pdf/1805.00909.pdf
lab:
http://rail.eecs.berkeley.edu/people.html
model free\off police:
https://www.zhihu.com/question/57159315
https://www.zhihu.com/question/64369408

 友情链接
友情链接