








公众号/量子位
郑集杨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
随着抗生素的滥用,抗生素耐药性已经成为日趋严重的问题。
据《病理学》一书的统计,全球每年感染病死亡数从上世界60年代约700万人上升到了本世纪的2000万。
科学家们正在努力缓解这个趋势,目前最新的方案是:用算法进行指导,在保持疗效下,减少不必要的抗生素使用。
11月4日,这项来自MIT和哈佛大学医学院的研究团队的相关进展,发布在了Science的子刊Science Translational Medicine上。

就让我们带大家了解一下抗生素耐药性及如何利用算法进行控制管理吧。
抗生素耐药性
大量抗生素的滥用会对细菌进行自然选择,使那些进化出抗生素抗性的菌存活了下来,产生出了抗生素耐药性的问题。

目前,对于应对抗生素耐药性这个问题,主要的方法有:
人工研发或者从自然界发现新型的抗生素;
控制管理抗生素的使用,减少抗生素的滥用;
使产生耐药性的菌对抗生素失去抗性。
“研发新药”是最直接且有效,但是速度是远赶不及抗生素耐药性的形成。于是,让目前最容易控制且实现的“管理控制抗生素方法”标准化且普遍化,已然是医学界的共识。
但是,如何有效管理控制,仍存在着问题:缺少明确的指标。目前,管理控制上更多依赖的是过往的经验。
而这项研究,便是利用大数据算法,给出了一个模型作为指标,来对抗生素的使用进行更精确有效的管理,以防止滥用进一步地加剧。
模型与算法
尿路感染(UTI)是相对容易进行治疗的疾病,因此研究者们对其进行了初步的尝试,希望得出能够预测最低抗生素用量的决策算法。
数据来源于电子健康记录(EHR),选取的抗生素对象有四类:呋喃妥因(NIT)、甲氧苄啶-磺胺甲噁唑(TMP-SMX)、环丙沙星(CIP)以及左氧氟沙星(LVX)。
在这里,研究者将细菌的表型数据分为两类,之后设定一个阈值,在这个阈值之上被归类为“不敏感”,在该阈值之下则被归类为“敏感”,四种抗生素疗法使用了四个不同的阈值。
最后,研究者尝试了三种模型构建方式:决策树、逻辑回归和随机森林模型。
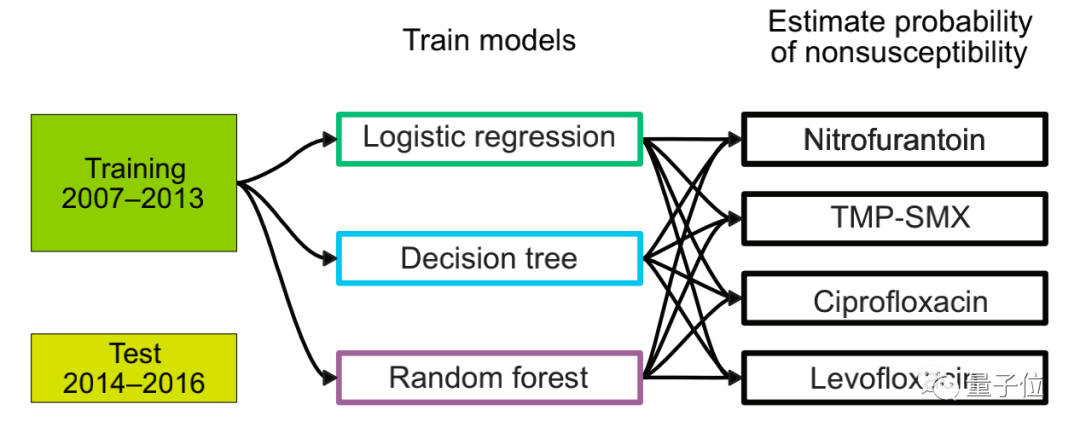
之后,研究者共选择了自2007年1月1日至2013年12月31日期间提交的患者尿液标本数据对模型进行训练。
通过对70%的训练数据进行训练(训练集),并对剩余30%的训练数据(验证集)进行AUROC评估,来调整模型类别和抗生素的每个组合的超参数。
在不敏感的数据归类中,结果显示,呋喃妥因和甲氧苄啶-磺胺甲噁唑的治疗效果是最好的,环丙沙星也略优于左氧氟沙星。
因此,为了更好地解释和预测现象,研究者选择了药效最弱的左氧氟沙星进行后续预测和分析。
有效的结果
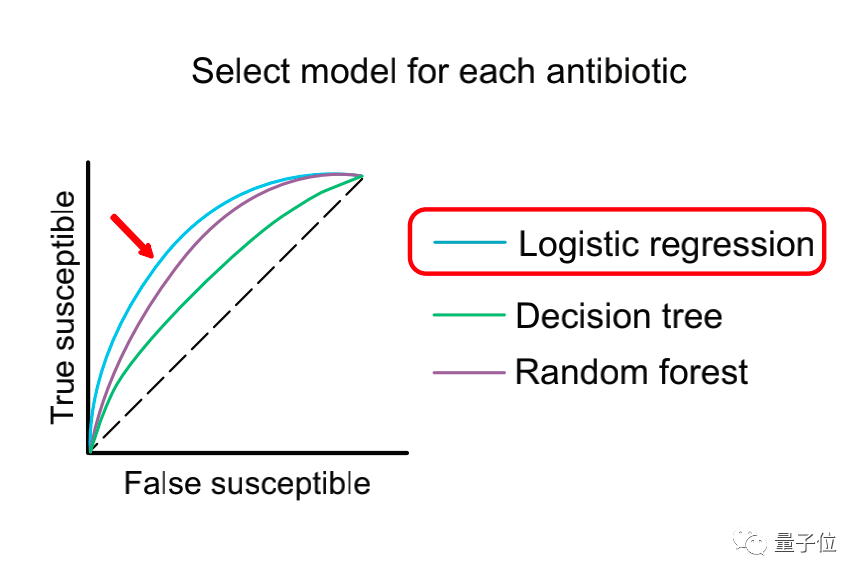
训练结束之后,研究者选择了结果最好的逻辑回归模型进行预测,并与自2014年至2016年间的患者组成的数据进行对比。
将模型应用于2014年至2016年之间的3629名患者并验证后,预测结果还是相当出色的:
该算法相对于临床医生而言,二线药物的使用减少了67%;
相对于临床医生,算法减少了18%的低于有效抗生素用量的治疗方案;
在临床医生选择二线药物,但算法选择一线抗生素中,92%结果最终对一线药物敏感;
当临床医生选择了不合适的一线药物中,有47%算法是选择了合适的一线药物的。
对此,研究人员说道:
这项机器学习的决策算法,在保持最佳的治疗效果同时,能够最大限度地减少广谱抗生素的使用,这为抗生素管理提供了方案。
作者及未来的研究
该研究的通讯作者是来自麻省理工学院副教授David Sontag:

其任教于麻省理工学院电气工程和计算机科学,隶属于医学工程和科学研究所和计算机科学和人工智能实验室。
研究重点是推进机器学习和人工智能,并利用它们来改进医疗保健。
对于未来的工作,David Sontag表示:
未来的工作将集中在进行随机对照实验,将常规方法与算法支持的决策进行比较。
另外,还可以增加样本量的多样性,比如族裔、社会经济地位以及更复杂的健康背景方面等。以更好地提出治疗的改进建议。
原文链接:
https://stm.sciencemag.org/content/12/568/eaay5067
— 完 —

 友情链接
友情链接