








公众号/
编辑/绿萝
临床医生越来越多地借助算法工具做出重要的医疗保健决策,这些工具利用大量复杂数据,其程度远远超过人类思维的推理能力。例如,研究人员开发了算法,可以从以前患者的大量数据中学习,以预测新患者在手术后出现并发症的风险。
然而,虽然现有的指导方针已到位,确保以清晰、标准化的方式向医疗保健界报告此类算法,但仍缺乏评估这些算法的框架。
佛罗里达大学的研究人员提出了一个理想算法的框架,包括 6 个要求:可解释、动态、精确、自主、公平和可重复性。并提出了一个理想的算法清单并将其应用于高引用算法。
该评论文章以「Ideal algorithms in healthcare: Explainable, dynamic, precise, autonomous, fair, and reproducible」为题,于 2022 年 1 月 18 日发布在《PLOS Digital Health》上。

为了最大限度地发挥其优势,算法必须包括 6 个要求:
可解释:能够阐明患者的各种特征,及其医疗状况在确定结果时的相对重要性,而不会混淆因果关系;
动态:能够根据患者特征的实时变化调整预测;
精确:能够充分利用以足够高的分辨率收集的数据,以可靠地捕捉患者不断变化的状况;
自主:能够以最少的人工输入学习和返回结果;
公平:能够解释任何隐含的偏见和社会不平等;
可重复性:能够与研究界广泛共享以进行验证。
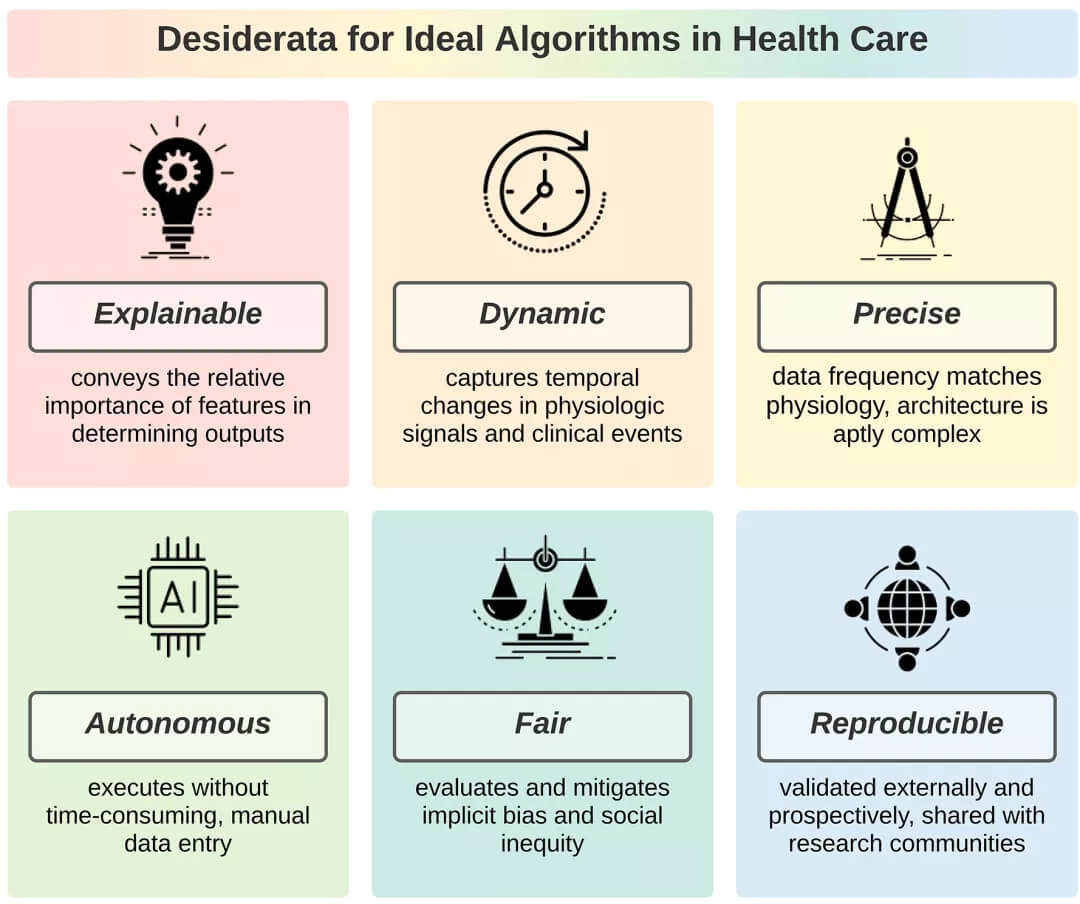
医疗保健中的理想算法具有 6 个理想特征:可解释、动态、精确、自主、公平和可重现。
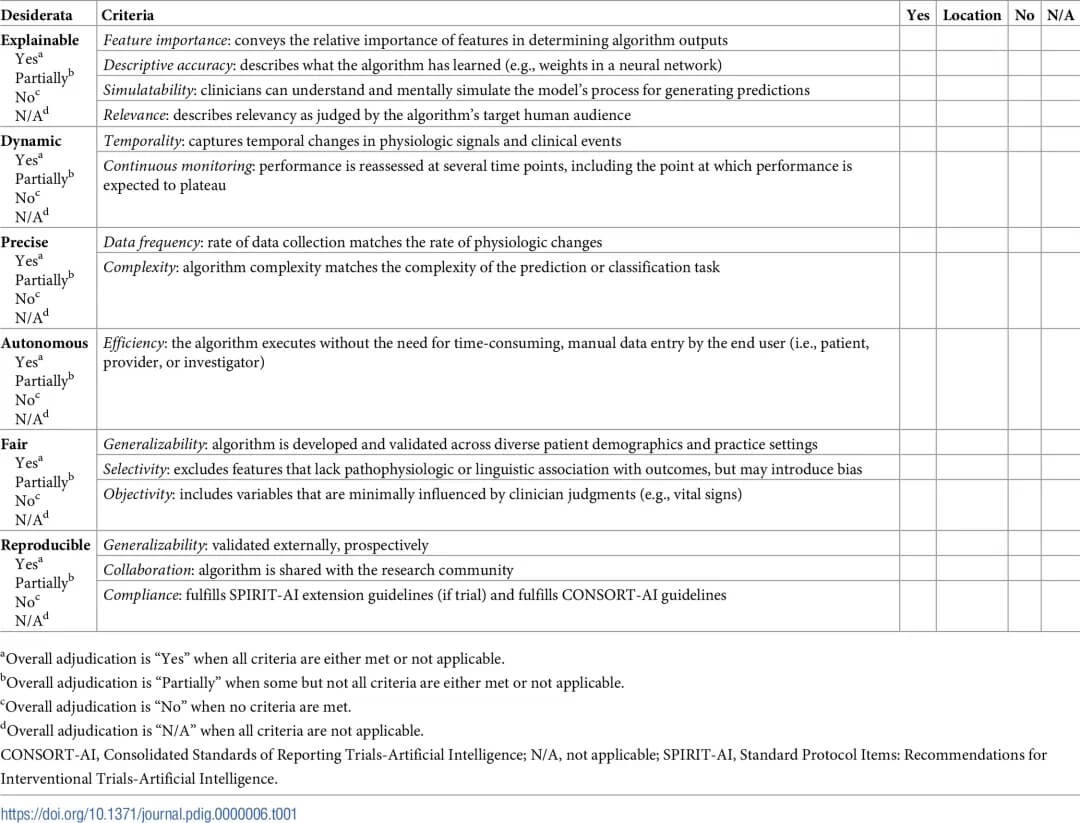
医疗保健中理想算法的清单。
理想算法是可解释的
可解释的算法传达了特征在确定输出中的相对重要性。知情的患者、勤奋的临床医生和严谨的调查人员想知道算法预测是如何做出的。这里建议使用预测性、描述性、相关性 (PDR) 框架来实现最佳可解释性。
算法的预测准确性通常被大多数临床医生和科学家描述和轻松解释。然而,预测准确性的一个被低估的方面可能会影响模型输出的可解释性:在某些情况下,预测误差因类别而异。
检查相关性可以解决预测和描述准确性之间的权衡。PDR 是一个简单而有效的框架,用于评估和讨论所有用户特定的机器学习解释,而不会混淆可解释性和因果关系。
理想的算法是动态的
动态算法通过时间序列或序列建模捕捉生理信号和临床事件的时间变化。当算法旨在改进临床试验设计、统计调整或患者登记策略时,单个时间点的静态预测就足够了。当算法旨在随着条件的发展而增强实时的临床决策时,算法应在新数据可用时使用新数据进行动态预测。
在对快速变化的条件进行建模时,算法动态性尤其重要。这些模型可能对研究目的、早期预测和早期资源使用决策有用,但它们不能执行随着新数据可用而更新预测的关键功能。
动态算法在评估随时间变化的性能和可解释性方面面临挑战。在某些情况下,算法学会预测临床医生下一步将采取的行动,而不是生理事件。此外,当以连续或几乎连续的方式进行预测时,没有评估模型性能的标准。在这里,建议在几个预定的离散时间点评估标准模型性能指标。
在动态算法中使用时间序列测量与理想算法的下一个要求有关:精度。
理想的算法是精确的
精确算法使用与生理变化率成比例的数据收集率和复杂性与目标结果相匹配的机器学习技术。精度很重要,因为人类疾病是复杂且非线性的。简单的加法模型通常表现出较差的预测性能。
在许多医疗保健环境中,出于临床目的,通常会从多个来源定期记录高度精细的数据。例如,危重患者的临床监测通常不仅包括生命体征和实验室测量,还包括对精神状态、疼痛、呼吸力学和活动能力的评估。
相反,当算法的输入相对于其应用而言过多时,由于过度拟合,通用性会受到影响。最佳方法通过使用维持高性能所需的最少变量来平衡预测准确性和输入复杂性。这可以通过稀疏回归方法来完成。生成简约模型虽然有可能损害预测性能,但具有提高输入特征描述准确性的额外优势。
理想算法是自主的
自主算法以最少的人工输入执行。除了所有无监督机器学习算法共享的训练和测试自主权之外,医疗保健中的自主算法可以在用户最少的输入的情况下实现。
对于许多输入特征与结果具有复杂关联的临床场景,自主算法具有增强决策制定的巨大潜力。预测手术后并发症的风险就是其中之一。
自主的潜在优势也适用于算法训练。监督机器学习算法使用由人类标记的训练数据,然后对新的、未见过的数据进行分类或预测;在无监督学习中,算法根据输入数据的结构和分布生成自己的标签,发现模式和关联。深度学习模型通过从原始数据中自主学习特征表示来避免耗时的手工特征工程。除了效率和实用主义之外,自主学习还具有性能优势,正如游戏行业所证明的那样。
理想的算法是公平的
公平算法评估和减轻隐性偏见和社会不平等。从理论上讲,算法利用数学公式和函数来产生客观的结果,从而防止主观因素带来的偏见和不公平。在实践中,许多算法都在有偏差的源数据上进行训练并产生有偏差的输出。在医疗保健领域,单中心源数据可能不成比例地代表某些人口统计数据。
通过对人口统计和社会经济变量进行评估校准,可以评估算法偏差。如果观察到的结果与算法预测的男性而不是女性的概率相匹配,则该算法表现出对女性的偏见。
已经描述了促进算法公平性的其他几种方法。应该随着时间的推移重新评估模型,以确定研究人群、医疗保健系统和医疗实践的时间变化是否影响了特征和结果之间的关系。这种现象,概念漂移,通过几种机制破坏算法性能,包括算法偏差。
理想算法是可重现的
可重现的算法经过外部和前瞻性验证,并与学术界共享。可重复性是任何科学探究的关键要素,对于机器学习算法尤其重要,因为它建立了可信度和可信度。在成功实施临床之前,「黑匣子」算法必须赢得患者、临床医生和研究人员的信任。
算法可重复性存在几个主要障碍。著名的 EHR 平台并不是为了适应跨机构和平台的算法可伸缩性而设计的。这产生了一个「分析瓶颈」,研究人员必须在机构孤岛内处理、协调和验证大量数据。许多研究人员不具备在如此大的计算规模下工作的必要资源,更不用说跟踪哪些数据用于不同的研究并评估数据重用对统计偏差的影响。此外,用于在拥有自己的算法管道和工具的研究组之间共享多个大型医疗保健数据存储库的云资源有限。
联合学习提供了通过协作机器学习确保算法的外部有效性、通用性和可重复性的机会,而无需数据共享。
理想算法框架在医疗保健领域的应用
为了确定医疗保健算法的突出示例,在这里,回顾了医学 AI 中引用率最高的 20 篇文章,这些文章在 Nadri 及其同事的文献计量分析中确定。在这 20 篇文章中,有 8 篇描述了一种算法。所有 8 种算法都符合精度标准,其中 6 种算法是自主的,5 种是公平的,4 种是可解释的,3 种是可重复的。动态性不适用于任何算法。这些发现为提高医疗保健算法的自主性、公平性、可解释性和可重复性提供了机会。
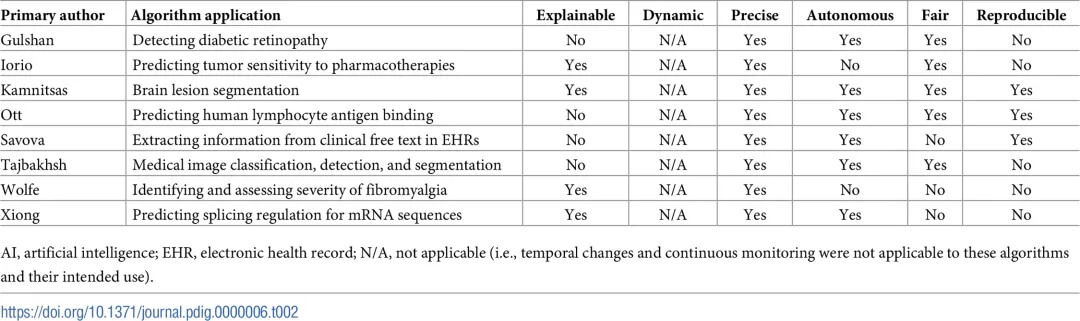
高度引用的人工智能算法根据其可解释性、动态性、精确性、自主性、公平性和可重复性进行分级。
结论
虽然人类疾病的广度和复杂性损害了假设演绎推理和启发式决策的有效性,但机器学习应用程序可以相对轻松地解析高复杂性和大容量数据。已建立的指南描述了报告算法医疗保健应用程序的最低要求;描述理想算法的最大潜力同样重要。研究人员建议理想算法有 6 个需求,在此处提供的清单中表示:可解释、动态、精确、自主、公平和可重复性。通过实现这些目标,医疗保健算法可以为患者、临床医生和研究人员带来最大的潜在利益。
论文链接:https://doi.org/10.1371/journal.pdig.0000006
相关报道:https://www.eurekalert.org/news-releases/939799

 友情链接
友情链接