








公众号/ ScienceAI(ID:Philosophyai)
编辑 | 橘子皮
在过去的两年里,人工智能程序的语言流畅度达到了惊人的水平。其中最大和最好的都是基于 2017 年发明的称为 Transformer 的架构。它以方程式列表的形式作为程序遵循的一种蓝图。
但除了这个简单的数学大纲之外,我们真的不知道 Transformers 对它们处理的单词做了什么。普遍的理解是,它们可以以某种方式同时关注多个单词,从而可以立即进行「大图」分析,但是这究竟是如何工作的——或者它是否是理解 Transformers 的准确方式——尚不清楚。就好比一道菜,我们只知道成分,但不知道配方。
现在,来自 Anthropic 公司的研究人员进行的两项研究,已经开始从根本上弄清楚 Transformers 在处理和生成文本时在做什么。在他们于 12 月发布的第一篇论文中,作者着眼于架构的简化版本并充分解释了它们的功能。以色列海法理工学院的 Yonatan Belinkov 说:「它们很好地描述了它们在非常简单的情况下是如何工作的……我对这项工作感到非常积极。它很有趣,有点独特和新颖,很有前途。」

论文链接:https://transformer-circuits.pub/2021/framework/index.html
作者还表明,简单的 Transformer 从学习基本语言模式到获得语言处理的一般能力。「你会看到能力的飞跃。」哈佛大学的 Martin Wattenberg 说, 作者是在「破译配方」。
在 3 月 8 日发表的第二篇论文中,研究人员表明,负责这种能力的相同组件也在最复杂的Transformer中发挥作用。虽然这些模型的数学在很大程度上仍然难以理解,但结果为理解提供了一个途径。「他们在玩具模型中发现的东西可以转化为更大的模型。」Conjecture 公司和研究小组 EleutherAI 的 Connor Leahy 说。

论文链接:https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
理解 Transformer 的难点在于它们的抽象性。传统程序遵循可理解的过程,例如每当看到「green」一词时就输出「grass」一词,而 Transformer 将「green」一词转换为数字,然后将它们乘以某些值。这些值(也称为参数)决定下一个单词是什么。它们在称为训练的过程中得到微调,模型学习如何产生最佳输出,但尚不清楚模型正在学习什么。
大多数机器学习程序将它们的数学打包成称为神经元的模块化成分。Transformer 加入了一种额外的成分,称为注意力头,它的头组分层排列(就像神经元一样)。但是头部执行与神经元不同的操作。头部通常被理解为允许程序记住输入的多个单词,但这种解释远非确定。
「注意力机制显然有效。它取得了很好的效果。」Wattenberg 说,「问题是:它在做什么?我的猜测是它正在做很多我们不知道的事情。」
为了更好地理解 Transformer 的工作原理,Anthropic 研究人员简化了架构,去掉了所有的神经元层和除一层或两层注意力头之外的所有层。这让他们发现了 Transformer 和他们完全理解的更简单模型之间的联系。
考虑一种最简单的语言模型,称为二元模型,它再现了基本的语言模式。例如,在对大量文本进行训练时,二元模型会注意单词「green」后面最常出现的单词(例如「grass」)并记住它。然后,在生成文本时,它会重现相同的模式。通过为每个输入单词记住一个相关的后续单词,它可以获得非常基本的语言知识。
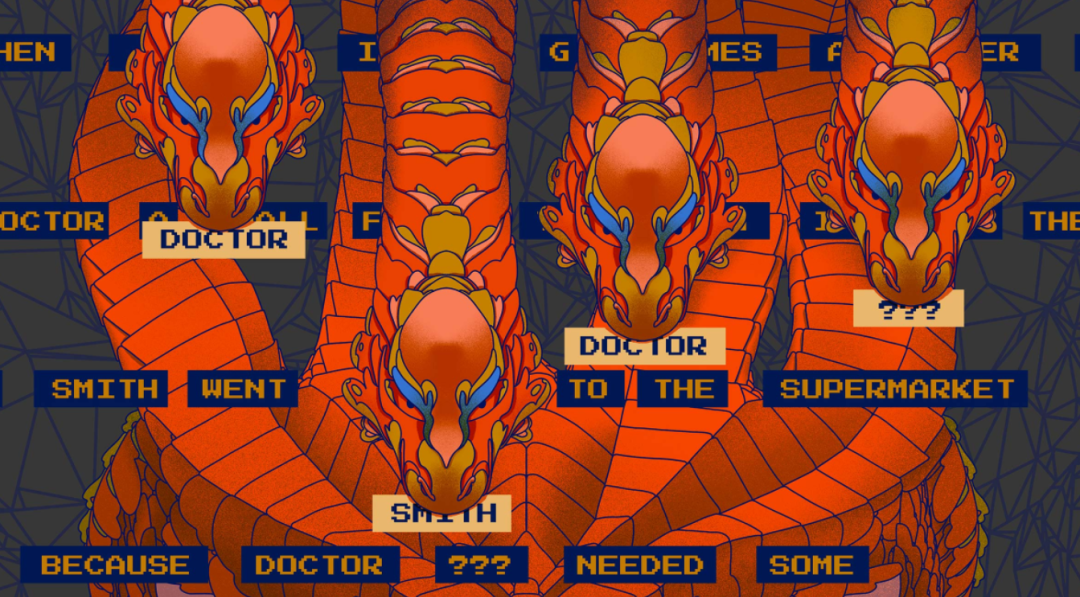
研究人员表明,具有一层注意力头的 Transformer 模型做了类似的事情:它再现了它所记忆的内容。假设你给它一个特定的输入,比如「史密斯医生去商店,因为医生……」这个输入被称为提示或上下文。对我们来说,下一个词是显而易见的——史密斯。
训练有素的单层模型中的注意力头可以分两步进行此预测。首先,它查看上下文中的最后一个词(医生),并在它已经学习(在训练期间)的上下文中搜索一个特定的词以与最后一个词相关联。然后,对于它找到的任何单词,它会查找另一个它已经学会的,且与找到的单词相关联的单词,就像在二元模型中一样(这可以是同一个词)。然后它将这个关联的词移动到模型的输出中。
对于这个例子,研究人员表明,根据最后一个词「医生」,头部从训练中知道搜索一个通用名称的词。在句子前面找到「Smith」这个名字时,头部会查看它所学到的与「Smith」相关联的内容,并将该词移动到输出中。(在这种情况下,模型已经学会将同一个词「Smith」与找到的词「Smith」相关联。)整个过程的净效果是模型将「Smith」这个词从上下文复制到输出。
「在这里,我们实际上可以理解注意力的作用。」共同作者之一 Anthropic 的 Chris Olah 说。
但记忆只能采取模型到目前为止。考虑一下当史密斯的名字变成一个虚构的名字时会发生什么,比如「Gigamuru」。对我们来说,句子完成仍然很明显——Gigamuru——但模型在训练期间不会看到虚构的词。因此,它不可能记住它与其他词之间的任何关系,也不会生成它。
Anthropic 团队发现,当他们研究一个更复杂的模型时——一个有两层注意力头的模型——一个解决方案出现了。它依赖于注意力头独有的能力:他们不仅可以将信息移动到输出,还可以移动到上下文中的其他位置。使用这种能力,第一层的头部学习用关于它之前的单词的信息来注释上下文中的每个单词。然后,第二个头可以搜索以单词「医生」(在本例中为「Gigamuru」)之前的单词,并像单层模型中的头一样,将其移动到输出。研究人员将后一层中的注意力头与前一层中的头协作称为感应头。它不仅仅是记忆。
「它正在做一些看起来更像抽象推理或实现算法的事情。」Anthropic 的 Nelson Elhage 说,他也是合著者,「这有点那种味道。」
感应头让两层模型做得更多,但它们与全尺寸Transformer的相关性尚不清楚,它们有数百个注意力头协同工作。在他们的第二篇论文中,研究人员发现这些发现得到了延续:感应头似乎对最复杂的多层架构的一些显著行为做出了重大贡献。
在这些行为中,算术的能力很显著,因为模型只被训练来完成文本。例如,如果给出重复提示:「问:48 加 76 等于多少?答:124,问:48 加 76 等于多少?A:……」一个完整的模型会得到正确的答案。并且在给出足够多的非重复示例后,它将能够正确回答它从未见过的算术问题。这种从上下文中明显学习新能力的现象称为上下文学习。
这种现象令人费解,因为从上下文中学习是不可能的。这是因为决定模型性能的参数仅在训练期间进行调整,而不是在模型处理输入上下文时进行调整。
感应头至少解决了部分难题。他们解释了上下文学习的简单、重复形式是多么可能,提供了所需要的:复制模型尚未经过训练可以使用的新词(如「Gigamuru」或「124」)的能力。
「感应头更有可能做任何模式,即使它有点奇怪或新奇。」另一位合著者 Anthropic 的 Catherine Olsson 说。
研究人员更进一步,在多层模型中识别感应头,并表明它们参与了更新颖的上下文学习形式,例如学习语言之间的翻译。
「这并不是要解释整个机制。」OpenAI 的 Jacob Hilton 说,「只是感应头似乎参与其中。」
结果为我们了解 Transformer 提供了一个立足点。他们不仅在获取知识,而且还在学习处理他们根本没有学到的东西的方法。也许通过知道他们这样做,我们可以对它们让我们感到惊讶而不那么惊讶。
相关报道:https://www.quantamagazine.org/researchers-glimpse-how-ai-gets-so-good-at-language-processing-20220414/

 友情链接
友情链接